
Uber has extensively adopted Go as a primary programming language for developing microservices. Our Go monorepo consists of about 50 million lines of code and contains approximately 2,100 unique Go services. Go makes concurrency a first-class citizen; prefixing function calls with the go keyword runs the call asynchronously. These asynchronous function calls in Go are called goroutines. Developers hide latency (e.g., IO or RPC calls to other services) by creating goroutines within a single running Go program. Goroutines are considered “lightweight”, and the Go runtime context switches them on the operating-system (OS) threads. Go programmers often use goroutines liberally. Two or more goroutines can communicate data either via message passing (channels) or shared memory. Shared memory happens to be the most commonly used means of data communication in Go.
A data race occurs in Go when two or more goroutines access the same memory location, at least one of them is a write, and there is no ordering between them, as defined by the Go memory model. Outages caused by data races in Go programs are a recurring and painful problem in our microservices. These issues have brought down our critical, customer-facing services for hours in total, causing inconvenience to our customers and impacting our revenue. In this blog, we discuss deploying Go’s default dynamic race detector to continuously detect data races in our Go development environment. This deployment has enabled detection of more than 2,000 races resulting in ~1,000 data races fixed by more than two hundred engineers.
Dynamically Detecting Data Races
Dynamic race detection involves analyzing a program execution by instrumenting the shared memory accesses and synchronization constructs. The execution of unit tests in Go that spawn multiple goroutines is a good starting point for dynamic race detection. Go has a built-in race detector that can be used to instrument the code at compile time and detect the races during their execution. Internally, the Go race detector uses the ThreadSanitizer runtime library which uses a combination of lock-set and happens-before based algorithms to report races.
Important attributes associated with dynamic race detection are as follows:
- Dynamic race detection will not report all races in the source code, as it is dependent on the analyzed executions
- The detected set of races are dependent on the thread interleavings and can vary across multiple runs, even though the input to the program remains unchanged
When to Deploy a Dynamic Data Race Detector?
We use more than 100,000 Go unit tests in our repository to exercise the code and detect data races. However, we faced a challenging question on when to deploy the race detector.
Running a dynamic data race detector at pull request (PR) time is fraught with the following problems:
- The race detection is non-deterministic. Hence a race introduced by the PR may not be exposed and can go undetected. The consequence of this behavior is that a later benign PR may be affected by the dormant race being detected and get incorrectly blocked, thus impacting developer productivity. Further, the presence of pre-existing data races in our 50M code base makes this a non-starter.
- Dynamic data race detectors have 2-20x space and 5-10x memory overheads, which can result in either violation of our SLAs or increased hardware costs.
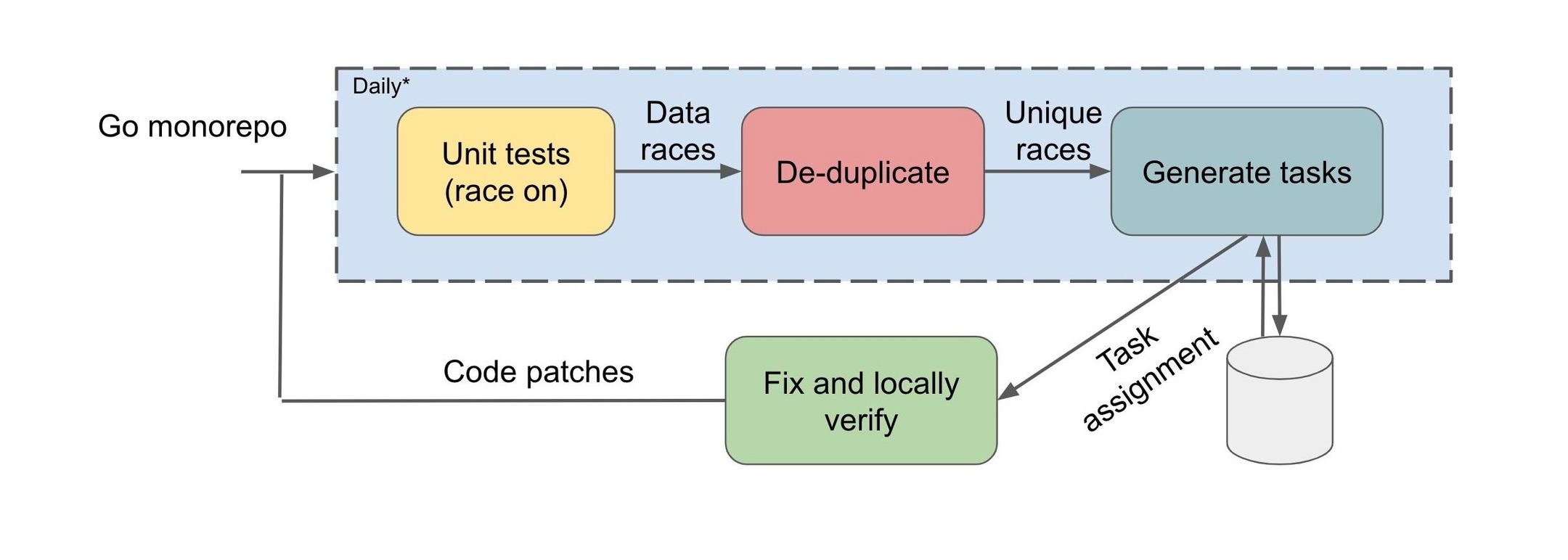
Based on these considerations, we decided to deploy the race detector periodically on a snapshot of code, post-facto, which involves the following steps:
(a) Perform dynamic race detection by executing all the unit tests in the repository
(b) Report all outstanding races by filing tasks to the appropriate bug owner
A detected race report contains the following details:
- The conflicting memory address
- 2 call chains (a.k.a., calling contexts or stack traces) of the 2 conflicting accesses
- The memory access types (read or a write) associated with each access
We handled a few hurdles in ensuring that duplicate races are not reported by performing a hash of the reported stack races, and applying heuristics to determine the possible developer who is responsible for fixing the bug. While we chose this deployment path, CI time deployment can be pursued if either detected races do not block the build and are used as warnings to inform the developer, or dynamic race detection is refined to make CI time deterministic detection feasible.
Impact of Our Deployment
We rolled this deployment out in April 2021 and collected data over a period of 6 months. Our approach has helped detect ∼2,000 data races in our monorepo with hundreds of daily commits by hundreds of Go developers. Out of the 2,000 reported races, 1,011 races were fixed by 210 different engineers. We observed that there were 790 unique patches to fix these races, suggesting the number of unique root causes. We also collected the statistics for the total outstanding races over the 6+ month period and have reported this data below:

In the initial phase (2-3 months) of the rollout, we shepherded the assignees to fix the data races. The drop in the outstanding races is noticeable during this phase. Subsequently, as the shepherding was minimized, we noticed a gradual increase in the total outstanding races. The figure also shows the fluctuations in the outstanding count, which is due to fixes to races, the introduction of new races, enabling and disabling of tests by developers, and the underlying non-determinism of dynamic race detection. After reporting all the pre-existing races, we also observe that the workflow creates about 5 new race reports, on average, every day.

In terms of the overhead of running our offline data race detector, we noticed that the 95th percentile of the running time of all tests without data race detection is 25 minutes, whereas it increases by 4 fold to about 100 minutes with data race enabled. In a survey taken by tens of engineers, roughly 6 months after rolling out the system, 52% of developers found the system to be useful, 40% were not involved with the system, and 8% did not find it useful.
Looking Ahead
Our experiences with this deployment suggest the following advancements:
- There is a need for building dynamic race detectors that can be deployed during continuous integration (CI). This requires that the challenges due to non-determinism and overheads are effectively addressed by the new detectors.
- Until such time, designing algorithms to root cause and identify appropriate owners for detected data races can help in accelerating the repair of data races.
- We have identified underlying coding patterns pertaining to data races in Go (discussed in the second part of this blog series), and a subset of these races can potentially be caught by CI time static analysis checks.
- The set of detected races is dependent on the input test suite. Being able to run race detection on other kinds of tests (beyond unit tests) such as integration tests, end-to-end tests, blackbox tests, and even production traces can help detect more races.
- We also believe that program analysis tooling that fuzzes the schedules on the input test suite can expose thread interleavings that can enhance the set of detected races.
- Finally, the current approach is dependent on the availability of multithreaded executions via unit tests and all possible scenarios may not necessarily be incorporated while manually constructing such tests. Automatically generating multithreaded executions containing racy behavior and using the detector to validate the race can serve as an effective debugging tool.
This is the first of a two-part blog post series on our experiences with data race in Go code. An elaborate version of our experiences will appear in the ACM SIGPLAN Programming Languages Design and Implementation (PLDI), 2022. In the second part of the blog series we discuss our learnings pertaining to the race patterns in Go.

Murali Krishna Ramanathan
Murali Krishna Ramanathan is a Senior Staff Software Engineer and leads multiple code quality initiatives across Uber engineering. He is the architect of Piranha, a refactoring tool to automatically delete code due to stale feature flags. His interests are building tooling to address software development challenges with feature flagging, automated code refactoring and developer workflows, and automated test generation for improving software quality.

Milind Chabbi
Milind Chabbi is a Senior Staff Researcher on the Programming Systems Research team at Uber. He leads research initiatives across Uber in the areas of compiler optimizations, high-performance parallel computing, synchronization techniques, and performance analysis tools to make large, complex computing systems reliable and efficient.
Posted by Murali Krishna Ramanathan, Milind Chabbi
Related articles





Most popular

Enhanced Agentic-RAG: What If Chatbots Could Deliver Near-Human Precision?

Advancing Invoice Document Processing at Uber using GenAI

From Archival to Access: Config-Driven Data Pipelines
