DBEvents: A Standardized Framework for Efficiently Ingesting Data into Uber’s Apache Hadoop Data Lake
Keeping the Uber platform reliable and real-time across our global markets is a 24/7 business. People may be going to sleep in San Francisco, but in Paris they’re getting ready for work, requesting rides from Uber driver-partners. At that same instant, halfway around the world, residents of Mumbai might be ordering dinner through Uber Eats.
We facilitate these interactions on Uber’s Big Data platform, using our marketplace to match riders and driver-partners; eaters, restaurants, and delivery-partners; and truck drivers and shippers. Data-driven insights about these interactions help us build products that provide rewarding and meaningful experiences to users worldwide.
Since eaters want their food delivered in a timely manner and riders want to wait a minimal amount of time for a pickup, our data must reflect events on the ground with as much immediacy as possible. As data comes into our data lake from a variety of sources, however, keeping it fresh at this scale represents a major challenge.
While existing solutions that offer 24-hour freshness work for many companies, it is far too stale for the real-time needs of Uber. Additionally, the data size and scale of operations at Uber prevents such a solution from working reliably.
To address these needs, we developed DBEvents, a change data capture system designed for high data quality and freshness. A change data capture system (CDC) can be used to determine which data has changed incrementally so that action can be taken, such as ingestion or replication. DBEvents facilitates bootstrapping, ingesting a snapshot of an existing table, and incremental, streaming updates.
Complementing other software built at Uber, such as Marmaray and Hudi, DBEvents captures data from sources such as MySQL, Apache Cassandra, and Schemaless, updating our Hadoop data lake. This solution manages petabytes of data and operates at a global scale, helping us give our internal data customers the best possible service.
Snapshot data ingestion
Historically, data ingestion at Uber began with us identifying the dataset to be ingested and then running a large processing job, with tools such as MapReduce and Apache Spark reading with a high degree of parallelism from a source database or table. Next, we would pipe the output of this job to an offline data lake such as HDFS or Apache Hive. This process, referred to as a snapshot, generally took minutes to hours depending on the size of the dataset, which was not quick enough for the needs of our internal customers.
Every time a job began ingesting data, it fanned out parallel tasks, established parallel connections to an upstream table, such as MySQL, and pulled data. Reading large amounts of data from MySQL puts a lot of pressure on real-time application traffic to MySQL, slowing it down to unacceptable levels. Strategies to reduce this pressure include using dedicated servers for extract, transform, and load (ETL), but that brings in other complications around data completeness as well as adding extra hardware costs for a backup database server.
The time to take a database or table snapshot increases with the amount of data, and at some point it becomes impossible to satisfy the demands of the business. Since most databases only have part of their data updated with a limited number of new records being added on a daily basis, this snapshot process also results in an inefficient utilization of compute and storage resources, reading and writing the entire table data, including unchanged rows, over and over again.
DBEvents requirements
With Uber’s need for fresher, faster insights, we needed to design a better way to ingest data into our data lake. When we began designing DBEvents, we identified three business requirements for the resulting solution: freshness, quality, and efficiency.
Freshness
Freshness of data refers to how recently it was updated. Consider an update to a row in a table in MySQL at time t1. An ingestion job begins running at time t1 + 1 and takes N units of time to ingest this data. The data becomes available to users at time t1 + 1 + N. Here, freshness lag of the data equals N + 1, that is the delay between when the data was actually updated to when it is available in the data lake.
Uber has many use cases which require N+1 to be as small as possible, preferably on the order of a few minutes. These use cases include fraud detection, where even the slightest delay can impact customer experience. For these reasons, we made data freshness a high priority in DBEvents.
Quality
Data in a data lake is of no use if we cannot describe or make sense of it. Imagine a situation where different upstream services have different schemas for different tables. Although each of these tables were created with a schema, these schemas evolved as their use cases changed. Without a consistent means of defining and evolving a schema for the data being ingested, a data lake can very quickly turn into a data swamp, a collection of large amounts of data which cannot be understood.
Additionally, as a table schema evolves, it is important to communicate the reasoning behind adding new fields or deprecating existing ones. Without an understanding of what a column represents, one cannot make sense of the data. As a result, ensuring high quality data was another priority for DBEvents.
Efficiency
At Uber, we have thousands of microservices responsible for different parts of the business logic as well as different business lines. In most cases, each microservice has one or more backing databases used for storing non-ephemeral data. As one can imagine, this leads to hundreds or thousands of tables that may be eligible for ingestion, requiring a large amount of compute and storage resources.
Consequently, a third goal we defined for DBEvents was to make the system efficient. By optimizing for usage of resources such as storage and compute, we end up lowering costs around datacenter use and engineering time, and subsequently make it easier to add more sources in the future.
Designing DBEvents
With these three needs in mind, we built DBEvents, Uber’s change data capture system, to capture and ingest changes to data incrementally, leading to an improved experience on our platform.
Dataset ingestion can be divided into two processes:
- Bootstrap: A point-in-time snapshot representation of a table.
- Incremental ingestion: Incrementally ingesting and applying changes (occurring upstream) to a table.
Bootstrap
We developed a source pluggable library to bootstrap external sources like Cassandra, Schemaless, and MySQL into the data lake via Marmaray, our ingestion platform. This library provides semantics needed to bootstrap datasets efficiently whilst providing a pluggable architecture to add any source. Each external source backs up a snapshot of its raw data into HDFS.
Once the snapshot backup process is complete, Marmaray invokes the library, which in turn reads the data back up, schematizes it, and serves it as a Spark Resilient Distributed Dataset (RDD) that is usable by Marmaray. Marmaray then persists the RDD into Apache Hive after performing optional deduping, partial row merging, and various other actions.
To improve the efficiency and reliability of ingesting really large tables, the bootstrap process is incremental. One can both define a batch size for the dataset and can incrementally (and potentially in parallel) bootstrap a dataset, avoiding overly large jobs.

MySQL bootstrap example
Creating backups of MySQL databases traditionally involves making a copy of the data on the file system and storing it in another storage engine using its native file format. This type of backup, where files are copied bit-by-bit, is referred to as a physical backup. The so-called physical files being copied often contain duplicate data due to the existence of indexes, which significantly increases the size of the dataset on disk.
As part of our DBEvents architecture, we developed and open sourced a service called StorageTapper, which reads data from MySQL databases, transforms it into a schematized version, and publishes the events to different destinations, such as HDFS or Apache Kafka. This method of generating events on target storage systems lets us create logical backups. Rather than using on a direct copy of a dataset, a logical backup relies on the events created by StorageTapper, based on the original database, to recreate datasets on the destination system.
In addition to greater efficiency than physical backups, logical backups offer the following benefits:
- They are easy to process by systems other than the originating storage service because the data is in a standard, usable format.
- They are not dependent on particular versions of MySQL, thereby providing better data integrity.
- They are significantly compact because they do not copy over duplicated data.

Achieving freshness
To make our data as fresh as possible, we need to consume and apply changes to a dataset incrementally, in small batches. Our data lake uses HDFS, an append-only system, for storing petabytes of data. Most of our analytical data is written in Apache Parquet file format, which works well for large columnar scans but cannot be updated. Unfortunately, since HDFS is append-only and Apache Parquet is immutable, users can’t apply updates to a dataset without bulk rewriting the entire dataset, or, in the case of Hive, rewriting large partitions of the dataset.
To ingest data quickly, we use Apache Hudi, an open source library created by Uber for managing all raw datasets in HDFS, which reduces the time taken to perform upserts into our immutable data lake. Apache Hudi provides atomic upserts and incremental data streams on datasets.
MySQL incremental ingestion example
Along with bootstrapping, we can also use StorageTapper to perform incremental ingestion from MySQL sources. In our use case, StorageTapper reads events from MySQL binary logs, which records changes made to the database. The binary log includes all INSERT, UPDATE, DELETE, and DDL operations, which we refer to as binary log events. These events are written to the log in the same order in which the changes were committed to the database.
StorageTapper reads these events, encodes them in Apache Avro format, and sends them to Apache Kafka. Each binary log event is a message in Kafka, and each message corresponds to a complete row of table data. Since the events being sent to Apache Kafka reflect the order that changes were made to the originating database, when we apply Apache Kafka’s messages to a different database, we get an exact copy of the original data. This process uses fewer compute resources than direct data transfer from MySQL to a different database.
Enforcing quality
To ensure high quality data, we first need to define the structure of a dataset in the data lake using a schema. Uber uses an in-house schema management service called Schema-Service, which ensures that every dataset on-boarded to the data lake has an associated schema and that any evolution of the schema goes through certain evolution rules. These evolution rules guarantee backwards compatibility on schemas to avoid breaking consumers of such datasets.
Schema-Service uses the Apache Avro format to store schemas and perform schema evolution. This schema is generally a 1:1 representation of the upstream table schema. A self-service tool lets internal users evolve the schema as long as the changes are accepted as backwards compatible. Once schema changes go through in Apache Avro format, a data definition language (DDL) statement is applied to the table to alter the actual table schema.
Schema encoding is a process through which each of the datum is schematized. A schema enforcement library (heatpipe) schematizes, or encodes, each datum, much like a thin client that can perform schema checks on each datum. The schema enforcement library also adds metadata to each changelog, making it globally standardized irrespective of what source the data originates from or to which sink the data is intended to be written. Making sure that all of our data follows a schema, and that our schemas are up-to-date, means that we can find and use all of the data ingested into our data lake.

MySQL schema enforcement example
As described above, users can request changes to the schema for MySQL through Schema-Service, which will validate the changes and make sure they are backwards compatible. If the request succeeds, a new version of the schema is available for use. Whenever StorageTapper reads an ALTER TABLE statement in the MySQL binary logs, it detects these schema changes. This triggers StorageTapper to start using the new schema for processing further events.
Efficient resource use
We identified a few inefficiencies in our older pipelines:
- Compute usage: Large jobs snapshotting the entire table and reloading them at a cadence is highly inefficient, especially when only a few records may have been updated.
- Upstream stability: Due to the frequent need to load the entire table, the job puts pressure on the source, such as during heavy reads on a MySQL table.
- Data correctness: Data quality checks are not performed upfront, resulting in a subpar experience for data lake users and low data quality.
- Latency: The delay between the time the mutation takes place in the source table to the time it is available to be queried on the data lake is large, lessening data freshness.
Hudi contributes to the efficiency of our DBEvents-powered pipelines by consuming and applying only updated rows and changelogs from upstream tables. Hudi ameliorates many of the inefficiencies we found by allowing incremental updates as opposed to snapshots, using fewer compute resources. By reading changelogs, Hudi does not need to load entire tables, thereby reducing pressure on upstream sources.
Figure 4, below, depicts clearly how these solutions work together in the DBEvents incremental architecture. At Uber, we pull data from various different sources. Each source has a custom implementation to read changelog events and provide incremental changes. For example, MySQL changelogs are tailed and pushed to Apache Kafka via StorageTapper, as described above, while Cassandra changelogs are made available through an Apache Cassandra feature called change data capture (CDC), along with Uber-specific integrations.
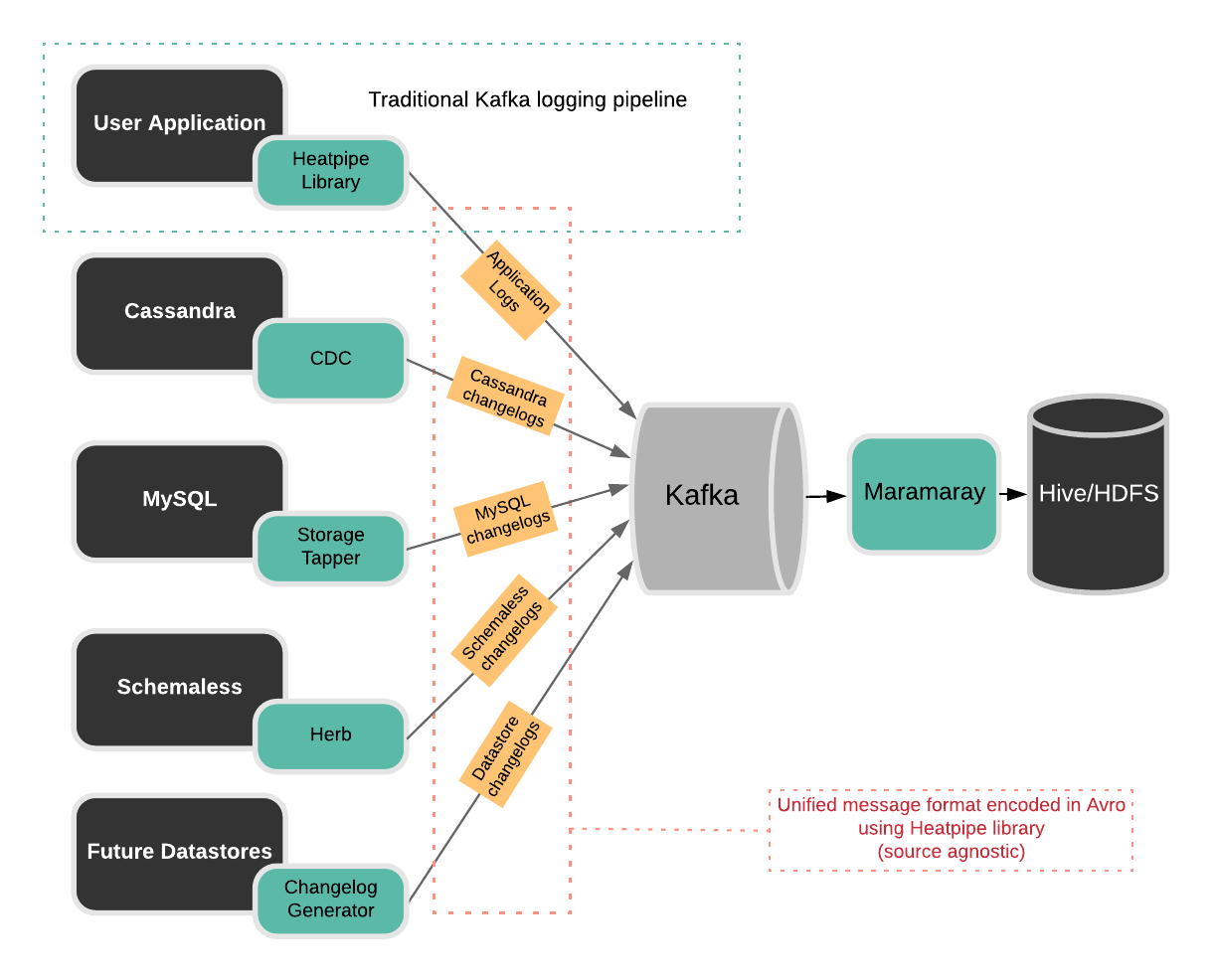
Marmaray is Uber’s open source, general-purpose data ingestion and dispersal library. At a high level, Marmaray provides the following functionalities for our DBEvents pipeline, leading to greater architecture efficiency:
- Produces quality, schematized data through our schema management library and services.
- Ingests data from multiple data stores into our Apache Hadoop data lake.
- Builds pipelines using Uber’s internal workflow orchestration service to crunch and process the ingested data as well as store and calculate business metrics based on this data in HDFS and Apache Hive.
A single ingestion pipeline executes the same directed acyclic graph job (DAG) regardless of the data source. This process determines the ingestion behavior at runtime depending on the specific source, similar to the strategy design pattern.
Standardizing Changelog events
One of our objectives was to standardize changelog events in a way that can be used by other internal data consumers such as streaming jobs and custom pipelines.
Before standardizing changelogs in DBEvents, we needed to address a few questions:
- How can we find errors while schematizing the payload and how should we handle them?
- A payload can be complex and only some parts of the full payload may be updated. How do we know what exactly was updated?
- If this payload is a changelog of a row mutation in an upstream database or table, what is the row’s primary key?
- Since we are using Apache Kafka as a message bus to send and receive changelogs, how do we enforce the use of monotonically increasing timestamps for events?
To answer these questions for the DBEvents use case, we defined a set of Apache Hadoop metadata headers that can be added to each Apache Kafka message. With this design, both the metadata and data are encoded via heatpipe (using Apache Avro) and transported through Apache Kafka. This enables us to standardize a global set of metadata used by all consumers of such events. This metadata describes each update in isolation and how these updates relate, in some ways, to previous streams of updates. The metadata is also written to Apache Hive in a special column called MetadataStruct which follows a metadata schema. A user can then easily query MetadataStruct and find out further details about the state of a row.
Below, we highlight some of the critical metadata fields that we standardized across events:
| Hadoop metadata fields | |
| Metadata field | Description |
| Row Key | The Row Key field is a unique key per source table that is used to identify the source table row and, based on the result, merge partial changelogs. |
| Reference Key | The Reference Key field is the version of the received changelog and must monotonically increase. This key is used to determine whether the data represents a more recent update for a particular row or not. |
| Changelog Columns | The Changelog Columns field is an array |
| Source | The Source field reflects the type of the source table that is used to generate this changelog. A few examples include Apache Kafka, Schemaless, Apache Cassandra, and MySQL. |
| Timestamp | The Timestamp field marks the time of creation of the event in milliseconds. The timestamp attribute has multiple uses but most importantly monitors latency and completeness. (We refer to the creation of an event as the time when a data schematization service such as StorageTapper actually schematizes the event before pushing it to Apache Kafka.) |
| isDeleted | [True/False]. This is a boolean value to support the deletion of a row_key in Hive tables. |
| Error Exception | Error Exception is a string capturing the exception or issue faced with sending the current changelog message (null in case of no error). In case of any schema issue with the source data, Error Exception will reflect the exception received which can later be used to track the source issue or fix/re-publish the message. |
| Error Source Data | Error Source Data is a string containing the actual source data-containing error (null in case of no error). In case of any problematic message, we cannot ingest this string into the main table and we move it to the related error table. We can use this data to work with the producer on a fix. |
| ForceUpdate | [True/False]. ForceUpdate is a boolean value which ensures this changelog is applied on top of existing data. In many cases, a ref_key older than the last seen ref_key is considered a duplicate and skipped. Having set this flag, however, the changelog will be applied regardless of the hadoop_ref_key field. |
| Data Center | The Data Center field refers to the the originating data center where the event originated. This field is very helpful to track messages and debugging any potential issue especially with the active-active or all-active architecture. Heatpipe automatically fill this value based on the data center the message is being published from. |
Standardized metadata, as shown in the table above, makes our architecture very robust and generic. This metadata provides adequate information to completely understand the state of each event. For example, if schematizing or decoding the event had any issues, the error fields will populate, as shown in Figure 5, below, and we can decide what action to take. At Uber, we write errors to an error table along with the actual payload that resulted in the issue.

Error tables serve many purposes:
- Producers of this data can find data that did not pass schema checks and later fix and publish an update.
- Data operations and tools can use error tables to find and debug missing data.
- Writing to error tables ensures we don’t have any data loss in the system and that every message is accounted for either in the actual table or in the error table.
Next steps
With the stream of incremental changes available through DBEvents, we are able to provide faster, fresher, and high quality data to the data lake. Using this data, we can ensure that Uber’s services, such as rideshare and Uber Eats, works as effectively as possible.
In the future, we intend to enhance the project with the following features:
- Self-service integration: We want to make onboarding a dataset to Apache Hive extremely easy and simple. For this to happen, we need to make some enhancements to the DBEvents framework so each source implementation can trigger bootstrapping and incremental ingestion seamlessly. This requires integrations between the source systems and ingestion, as well as integration with a source monitoring framework.
- Latency and completeness monitoring: Although we have the building blocks to provide this information, we only have an implementation for the Apache Kafka data source type. We would like to add enhancements to productionize this for all data source types.
If working on distributed computing and data challenges appeals to you, consider applying for a role on our team!
Acknowledgements
Special thanks to Reza Shiftehfar, Evan Richards, Yevgeniy Firsov, Shriniket Kale, Basanth Roy, Jintao Guan, and other team members for all their contributions!
Ovais Tariq
Ovais is a Sr. Manager in the Core Storage team at Uber. He leads the Operational Storage Platform group with a focus on providing a world-class platform that powers all the critical business functions and lines of business at Uber. The platform serves tens of millions of QPS with an availability of 99.99% or more and stores tens of Petabytes of operational data.
Nishith Agarwal
Nishith Agarwal currently leads the Hudi project at Uber and works largely on data ingestion. His interests lie in large scale distributed systems. Nishith is one of the initial engineers of Uber’s data team and helped scale Uber's data platform to over 100 petabytes while reducing data latency from hours to minutes.