DataCentral: Uber’s Big Data Observability and Chargeback Platform
In this blog, we will walk you through DataCentral, Uber’s homegrown Big Data Observability, Attribution, and Governance platform. This blog gives a high-level overview of DataCentral’s key features. Before we get into the what and why of DataCentral, let’s do a quick primer of Uber’s Data ecosystem and its challenges.
Introduction to Uber’s Big Data Landscape
Uber’s data infrastructure is composed of a wide variety of compute engines, scheduling/execution solutions, and storage solutions. Compute engines such as Apache Spark™, Presto®, Apache Hive™, Neutrino, Apache Flink®, etc., allow Uber to run petabyte-scale operations on a daily basis. Further, scheduling and execution engines such as Piper (Uber’s fork of Apache Airflow™), Query Builder (user platform for executing compute SQLs), Query Runner (proxy layer for execution of workloads), and Cadence (workflow orchestration engine, open-sourced by Uber) exist to allow scheduling and execution of compute workloads. Finally, a significant portion of storage is supported by HDFS, Google Cloud Storage (GCS), AWS S3, Apache Pinot™, ElasticSearch®, etc. Each engine supports thousands of executions, which are owned by multiple owners (uOwn) and sub-teams.
Challenges
With such a complex and diverse big data landscape operating at petabyte-scale and around a million applications/queries running each day, it’s imperative to provide the stakeholders a holistic view of the right performance and resource consumption insights.
Stakeholder Personas
The stakeholders of the big data ecosystem at Uber comprises of the following:
Job Owners: End users visit DataCentral to find out the metadata for their jobs such as duration, costs, resource consumption, query text and logs, etc. This allows DataCentral to serve as a powerful platform for debugging failed queries and applications.
Big Data Teams: Big data engine teams like Spark, Presto, Hive, and Neutrino leverage the DataCentral platform to get high-level insights into the number of jobs failing, bad/abusive jobs, top error reasons, blocked queries, etc. In addition, DataCentral helps them to investigate SLA breaches, incidents, and job failures.
Executive Leadership: DataCentral also supports business decision making by providing organization-level statistics, such as app/query level costs. It also offers information that can be leveraged to forecast hardware requirements and costs incurred.
Some typical questions which go through various personas involved with the big data platforms at Uber:
Enter DataCentral
At Uber, we have developed DataCentral, a comprehensive platform to provide users with essential insights into big data applications and queries. DataCentral empowers data platform users by offering detailed information on workflows and apps, improving productivity, and reducing debugging time. DataCentral provides the following key services for customers:
- Observability: Granular insights into performance trends, costs, and degradation signals for big data jobs.
- Chargeback: Metrics and resource usage for big data tools and engines such as Presto, Apache Yarn™, HDFS, Apache Kafka®, etc.
- Consumption Reduction Programs: Powers core cost reduction initiatives for Uber’s data ecosystem, such as HDFS growth reduction, Yarn usage reduction, etc.
How does DataCentral help with Observability?
Data Observability provides real-time insights into compute queries and applications. Since Uber’s data ecosystem is spread across different components, we have to track metrics across engines like Presto, Spark, Hive, and Neutrino. Aggregation and tying these metrics to execution engines is also a challenge. We do this with the following offerings:
Time series metrics (a.k.a. Clio): Every query run at Uber is fingerprinted and associated with a historical trend of executions (we call this in-house solution Clio). Customers can view historical trends for metrics like Costs, Duration, Efficiency, Data Read/Written, Shuffle, and much more. Having insights into historical trends allows customers to detect and debug applications faster. Further, we provide “config change markers” that allow easy correlation between config changes and changes in the historical trends (refer to Metrics trend in Figure 4). One major challenge we observed was that infrastructure introduced failures. To address this, we built observability into Yarn, HDFS, and correlation tools.
Yarn Observability: Saturated Yarn resources can cause job failures and slowness, which are difficult to debug. We offer solutions to observe and correlate the Yarn utilization in real time when applications are run. Further, we provide insights and suggestions when jobs get affected by Yarn.
File System Observability: HDFS slowness and File-system-induced latencies are another factor causing degradations that are difficult to detect. We made changes to the Uber Hadoop client to add client-side monitoring of HDFS call counts and latencies with application-level granularity. Every developer can view the File System performance for their specific application/query, which makes the debugging process smoother. We further have correlation systems in place to capture the various infrastructure and engine metrics to root cause issues and suggest fixes–that’s for another blog.
Contactless
A good chunk of any data platform user’s time goes into debugging/troubleshooting failed queries and applications. To help them to efficiently troubleshoot, we developed the “Contactless: system with the following objectives:
- Improve discoverability of errors
- Identify and surface the root cause, from the right layer
- Provide user-friendly explanations and suggestions
- Provide actionable workflows to resolve errors
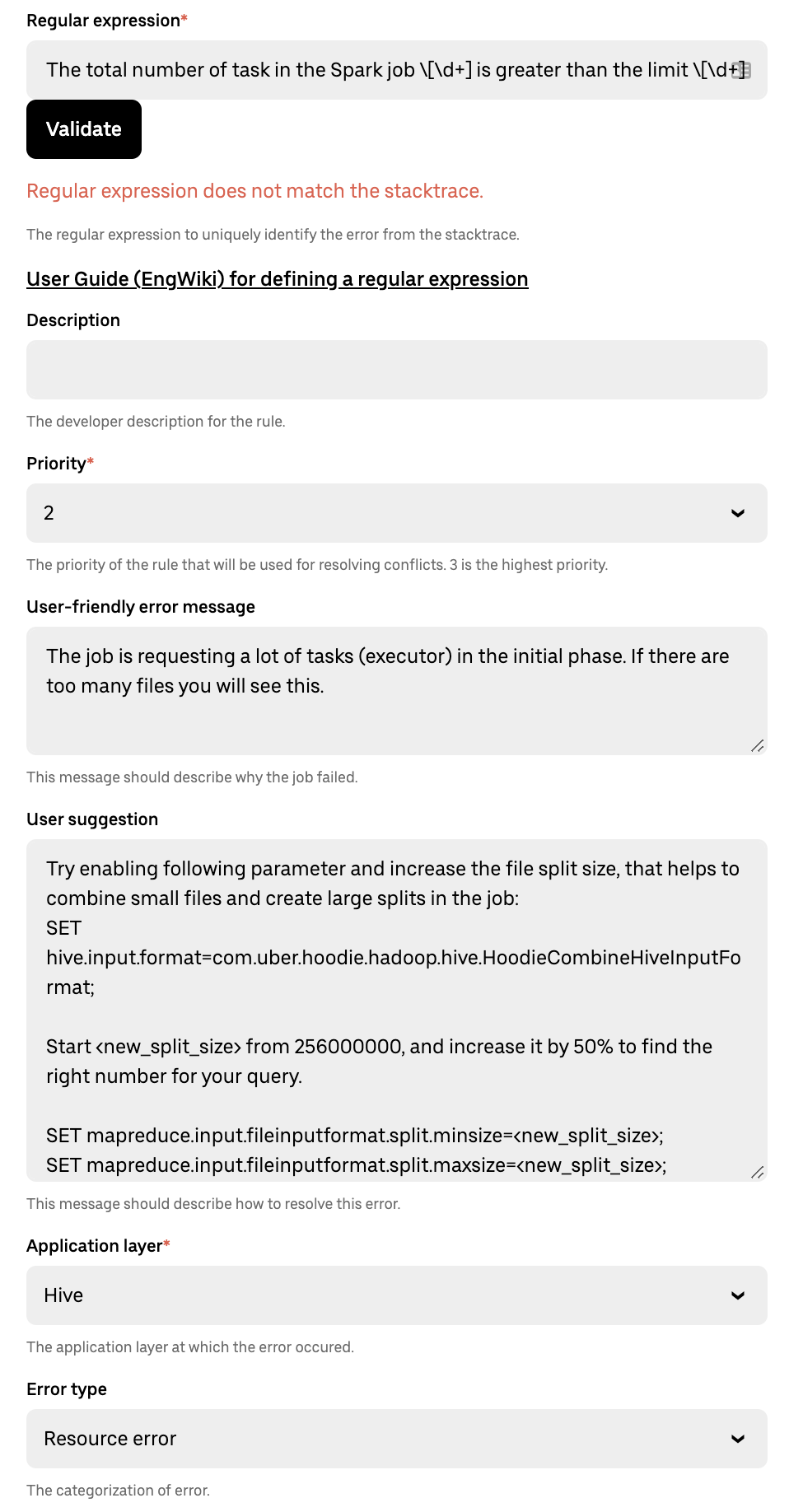
The service enables engine teams to add regex-based rules into the system. A rule also supports adding additional metadata, like user-friendly explanation, root cause layer, priority, etc. Once the stack traces are gathered for an application, the contactless service matches the exception trace against the rules and surfaces the most relevant message back to the user.
Whenever applications fail, DataCentral parses the error logs and applies contactless rules on the stack traces. User friendly suggestions and error messages are then displayed on the DataCentral console, which enable the end user to debug and root cause failures. Furthermore, a suggestions tab indicates the best actions that can be taken to resolve the error.

How Does DataCentral Help with Cost Efficiency?
Cost governance and reduction at Uber are driven by two concepts: attribution and cost efficiency.
Chargeback
Instead of setting hard limits and budgets on teams, Uber provides high transparency into costs and resource usage on several dimensions so that the stakeholders are equipped with the right data while making decisions. Resource usage and costs are tracked at a uOwn (Uber’s ownership platform) level granularity. Furthermore, the resource usage can be dissected across different granularities such as: User, Pipeline, Application, Schedule, and Queue level. Attribution is critical in driving conservation, identification of anti-patterns, and driving critical cost-reduction initiatives.
Consumption Reduction
Once resources can get attributed to the right teams and owners, stakeholders have insights into metrics like: most expensive pipelines, continuously failing workloads, unnecessary compute, etc. As part of cost efficiency, we have taken up projects (such as HDFSRed, YarnRed, PrestoRed, etc.) that make automated, data-driven decisions to reduce costs. The HDFSRed project checks the access patterns of Uber’s data tables and creates Jira tickets for owners to push for table deletions and TTLs when data is not frequently accessed. Yarn and Presto reduction initiatives similarly check for anti-patterns and unnecessary compute and raise actionable Jira tickets to reduce/stop unused compute.
DataCentral’s Scale
In order to provide real-time metadata for all Uber-wide applications, DataCentral has to match the scale of the various engines at Uber. Flink jobs keep up with Engine-level scale to ingest real-time modeled data into the internal stores. With 500K Presto queries/day, 400K Spark apps/day, and 2M Hive queries/day, the data observability jobs handle 2K queries per minute and 30K RPS while reading the engine-level metrics. Further, HDFS insights handle over 10B calls per day and peak at 150K RPS (since this tracks calls on application-level granularity).The datastores have a 6-month retention span to handle the data growth and scale.
Architecture
It is critical to provide real-time insights and metadata in order to minimize time to debug and mitigate job failures. DataCentral’s architecture consists of the following components:
- Engines like Presto, Hive, Spark, and Neutrino emit query-level metadata to Kafka topics in real time. DataCentral has Flink jobs that constantly listen to these Kafka topics and consume any job-level metadata emitted by the engines.
- The Flink jobs pre-process this data in real time and combine metadata on job-level granularity across multiple sources. Finally, the data is stored in internal stores like MySQL and Docstore (Uber’s internal datastore, providing strong consistency and high horizontal scaling).
- DataCentral microservice stack consists of several APIs that serve a variety of use cases, such as the DataCentral UI, external teams, TTL setting on Hive tables, and much more.
The journey of the metadata right from the engines to Observability datastores takes under 500 ms. The DataCentral UI provides insights and metadata, which are served via the MySQL and Docstore datastores. The UI supporting APIs fetch data from disparate sources and join it into unified responses, finally serving the customer-facing views.
Further batch workloads are run to power modeled datasets, which provide critical cost attribution data. Data from various engines is joined with HiveMetastore, uOwn, and other metadata sources to power rich insights, which are served on the DataCentral UI to downstream teams and leveraged for cost-reduction initiatives.
DataCentral & Uber’s Move to Cloud
As Uber moves to cloud, our priority remains to provide cost transparency and cost reduction into the Cloud ecosystem. Furthermore, DataCentral is supporting engine teams with critical metrics for performance testing, benchmarking, and identifying degradations when moving workloads to cloud. This allows us to make the right decisions as we migrate critical jobs to the cloud. For example, File System Observability has allowed engine teams like Spark to observe the latency increase with cloud and make the right solutions to migrate.
Conclusion
DataCentral has been a critical tool for engineers, data analysts, and platform teams at Uber. It provides advanced analytics and granular insights into big data applications and queries. DataCentral is used by stakeholders ranging from job owners, engine on-calls, platform teams and executive leadership. The self-serve nature of the platform has made it efficient for customers to debug jobs, mitigating incidents and root cause SLA breaches. Another key offering of DataCentral is the consumption insights into big data compute and storage entities such as HDFS, Yarn, Kafka, Presto, etc. DataCentral acts as the single source of truth for stakeholders to get insights into platform-, team-, and org-level insights. Furthermore, we plan to open-source the DataCentral toolkit for broader adoption and community collaboration.
Apache®, Apache Pinot™, Apache Flink®, Apache Kafka®, Apache Hive™, Apache Hadoop®, Apache Spark™, Apache Yarn™, Kafka®, Apache Airflow™, Flink®, Hive™, Hadoop®, Spark™, Pinot™, Airflow™, and Yarn™ are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Presto is a registered trademark of LF Projects, LLC. No endorsement by LF Projects, LLC is implied by the use of these marks.
Amazon Web Services, AWS, S3, the Powered by AWS logo are trademarks of Amazon.com, Inc. or its affiliates.
Header image: “New York Grand Central Station” by jensfrickephotography is licensed under CC BY 2.0.
Krishna Karri
Krishna Karri is an Engineering Manager on Uber's Data Platform Team. He leads the Data Central team, which specializes in crafting advanced big data observability and chargeback platforms that are integral to the consumption reduction and cost efficiency initiatives within Uber’s Data Platforms.
Atul Mantri
Atul Mantri is a Senior Software Engineer on Uber's Data Platform team. He is focused on building systems that enable big data observability across all batch and real-time applications at Uber and turbocharging the cost-efficiency initiatives in the platform. Before Uber, Atul worked at Rubrik and Netapp building high-performance distributed systems. He holds a Masters degree from NC State University.
Amruth Sampath
Amruth Sampath is a Senior Engineering Manager on Uber’s Data Platform team. He leads the Batch Data Infra org comprising Spark, Storage, Data Lifecycle management, Replication, and Cloud Migration.
Arnav Balyan
Arnav Balyan is a Senior Software Engineer on Uber’s Data team. He’s a committer to Apache Gluten™, and works on optimizing query engines and distributed systems at scale.