Transforming Ads Personalization with Sequential Modeling and Hetero-MMoE at Uber
March 10 / Global
Introduction
Personalization lies at the heart of an effective ads delivery system. On Uber’s platform, this means ensuring every sponsored placement is relevant and timely, context-aware, and aligned with each person’s evolving preferences. Our ads delivery system leverages large-scale machine learning models that continuously learn from behavioral signals, such as past orders, user engagements, and geographic context, to predict the most relevant ads for every impression opportunity. By optimizing across multiple objectives like user engagement, advertiser performance, and marketplace health, the system delivers more meaningful recommendations to people while helping advertisers reach audiences with higher intent. This balance of personalization and efficiency, powered by scalable multi-task ML infrastructure and real-time decisioning, enables a dynamic ecosystem where ads enhance discovery rather than disrupt it.

Background
As our ads delivery system matured, two key limitations surfaced in the existing architecture. First, our reliance on largely static, aggregate features flattened rich temporal user behaviors into summary statistics, such as total clicks or impressions within a fixed time window. While effective for short-term modeling, this approach lost crucial ordering, recency, and long-term context, capturing only snapshots of user behavior rather than evolving intent. To better represent the dynamics of user engagement, we introduced sequential user features powered by a target-aware transformer encoder, enabling the model to preserve fine-grained interaction patterns and reason over a user’s lifelong engagement history.
The second challenge lay in the modeling capacity of the traditional MMoE (Multi-gate Mixture of Experts) framework, which struggled to learn higher-order cross-feature interactions through its MLP-based experts. This limited our ability to incorporate richer modalities such as text, image, and semantic embeddings, and constrained the expressiveness needed for multi-objective learning at scale. To address this, we re-architected the core model with a Hetero-MMoE design, which is a heterogeneous mixture of experts that blends MLP (multi-layer perceptron), DCN (Deep Cross Network), and CIN (Compressed Interaction Network) modules to capture both low- and high-order feature interactions more effectively.
Together, these upgrades significantly enhance our model’s ability to learn from sequential engagement signals and deliver more precise, context-aware ad predictions across diverse objectives.
Architecture
Sequential User Features
To capture temporal dynamics in user behavior, we construct a sequence of engagement events that reflect each user’s interaction history on the platform. Each event is represented as a compact set of features capturing contextual and behavioral information:
- Store UUID (hashed integer): identifies the merchant or restaurant interacted with
- Cuisine type (hashed integer): encodes the category of food or service
- Hour (local) and day of week (local): captures temporal context and periodic patterns in engagement
- Engagement type: indicates the nature of the interaction, including clicks, add-to-cart actions, and completed orders
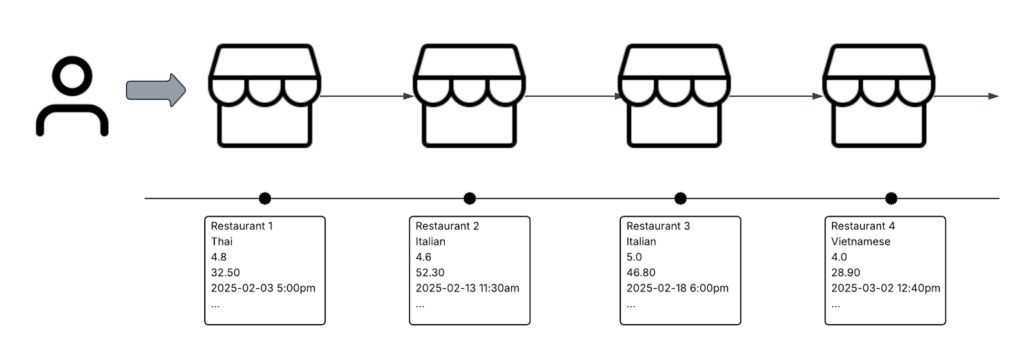
These event-level features are chronologically ordered to preserve temporal structure and fed into a target-aware transformer encoder. This allows the model to attend to relevant portions of the user’s historical sequence when evaluating a candidate ad, effectively modeling intent evolution over time rather than relying on static snapshots.
Target-Aware Transformer Encoder
The transformer is a deep learning architecture originally designed for natural language processing tasks such as translation and text generation. Conceptually, a transformer learns to predict the next token in a sequence based on contextual information from previous tokens. This ability to model dependencies and relationships across sequences makes it a natural fit for capturing user engagement patterns over time, where each interaction can be viewed as a token in the user’s behavioral history.
Each event in the user sequence is represented through a multi-hash embedding that converts categorical inputs (such as store UUID, cuisine type, and engagement type) into dense vector representations. Unlike a standard embedding layer that assigns a unique vector to every possible ID, multi-hash embedding uses multiple independent hash functions to map high-cardinality features into smaller embedding spaces. The resulting vectors from each hash are combined to form the final embedding. This design dramatically improves parameter efficiency and memory scalability, especially given the vast and evolving corpus of entities on the Uber platform (millions of stores and cuisine variations). Combined with positional encoding, these embeddings preserve semantic meaning and temporal ordering.
To make the sequence modeling target-aware, we introduce the candidate ad as a query to the encoder. The transformer learns to compute relevance scores between this target and the user’s historical events through self-attention. This allows the model to focus on the most relevant parts of the user’s engagement sequence when evaluating a candidate ad, aligning behavioral context with the current prediction. The resulting representation encodes long-term user intent and target-specific relevance, forming a rich contextual signal for the downstream Hetero-MMoE layer used in final ranking.
Our encoder is composed of stacked transformer blocks, each containing a self-attention module and a feed-forward network (FFN).
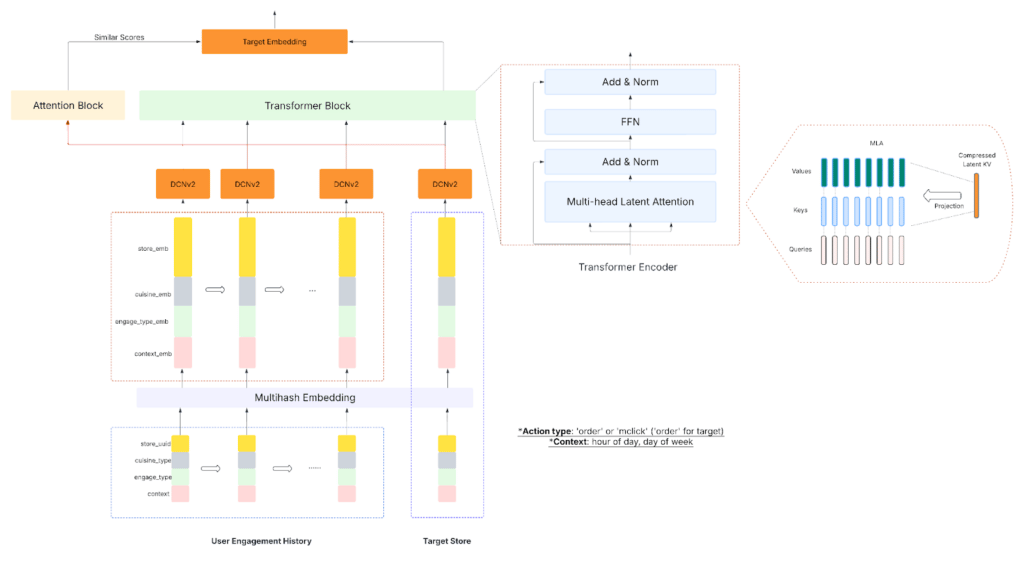
Traditional MHA (Multi-Head Attention) computes attention weights for every token-to-token pair, allowing each event to attend to all others in the sequence. While expressive, this approach scales quadratically with sequence length: O(N²) and often captures redundant or noisy interactions, especially in long engagement histories. It also makes it challenging to enforce global abstraction, as the attention mechanism can become overly localized.
To address these limitations, we introduced MLA (Multi-Head Latent Attention), which is a more efficient variant that leverages a fixed-size set of learnable latent tokens as intermediaries between user events. Attention is routed through these latents in two stages:
- Token → Latent (read/compression). The model compresses detailed event-level information into a small set of latent representations, effectively summarizing the sequence.
- Latent → Token (broadcast/global context). The latents then redistribute aggregated global context back to individual tokens.
This architecture reduces attention complexity from O(N²) to O(N × L), where L ≪ N, making it significantly more scalable for long sequences while preserving expressiveness. The latent bottleneck forces the model to distill key behavioral signals, such as dominant cuisines, engagement frequency, or recency trends, into compact, globally relevant representations, enabling efficient extraction of high-level user intent.
The FFN component complements this by refining each token’s representation independently, allowing the model to capture localized nuances once global context has been integrated through MLA.
Hetero-MMoE Framework
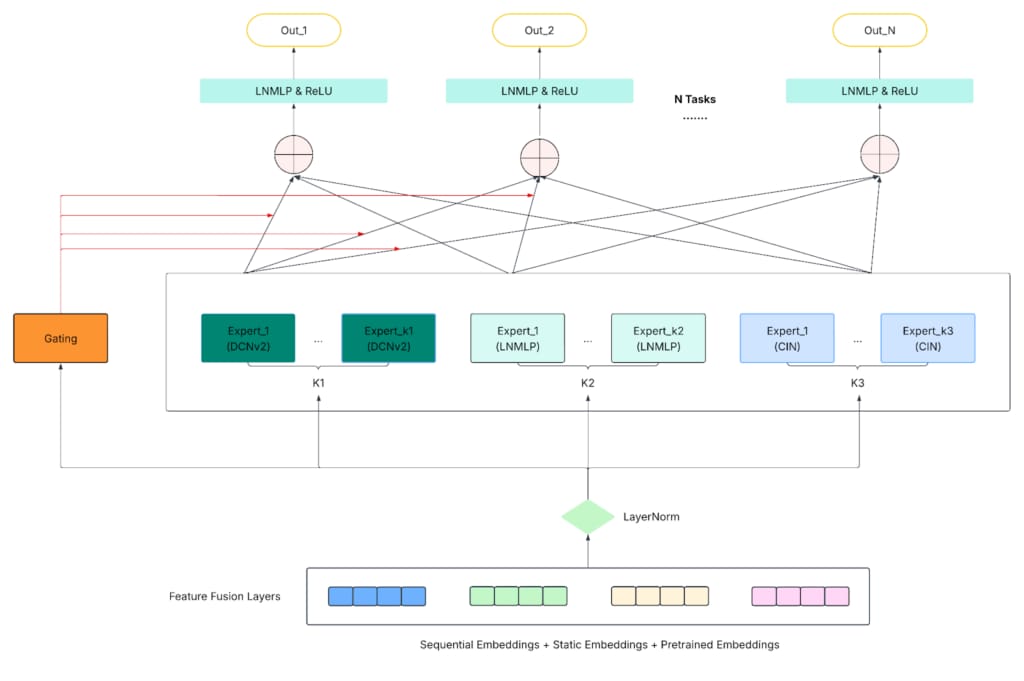
As our ads ranking system evolved to optimize for multiple business objectives, such as CTR (click-through rate), and CTO (click-to-order) rate, we required a multi-task learning framework that could scale efficiently while mitigating task conflicts and negative transfer. The MMoE (Multi-gate Mixture-of-Experts) architecture addressed this by combining shared expert networks that learn diverse latent representations from shared inputs with task-specific gating networks that dynamically weight expert contributions. On top of these, task towers generate objective-specific predictions (like pCTR and pCTO).
While effective, the traditional MMoE framework revealed key limitations at Uber’s production scale. Its experts, typically simple MLPs, struggled to capture higher-order cross-feature interactions, especially when modeling rich multimodal inputs like text, images, or semantic embeddings. This lack of structural diversity created a bottleneck in representational capacity, limiting the model’s ability to capture deep nonlinear patterns and explicit cross-feature relationships essential for complex ads delivery tasks.
To overcome these challenges, we introduced the Hetero-MMoE (Heterogeneous MMoE): an enhanced architecture that diversifies the expert layer composition by integrating multiple expert types, each specializing in different forms of feature interaction. The expert types are:
- MLP experts: Traditional feed-forward networks that learn deep, implicit feature interactions. They remain the backbone for nonlinear representation learning and generalization across tasks.
- DCN experts: Combine across networks that explicitly models feature interactions through cross layers with a deep MLP component that captures higher-level abstractions. This structure efficiently learns low- to mid-order feature interactions, improving interpretability and convergence.
- CIN experts: Adapted from the xDeepFM architecture, the CIN module explicitly models high-order feature interactions in a vector-wise, compressed form. We implemented a 2D variant optimized for our use case, preserving embedding structure while scaling efficiently with large input dimensionality.
By blending these complementary expert types within the same mixture layer, Hetero-MMoE achieves a flexible and modular expert composition that captures explicit and implicit feature interactions across modalities, scales efficiently to multi-task, multi-objective optimization, and provides an extensible foundation for future expert variants tailored to specific modalities or business needs.
Uber Use Cases
The upgraded model is deployed to predict key user behaviors in ads delivery, including pCTR (click-through rate) and pCTO (click-to-order rate). In online experiments, the new architecture delivered substantial performance gains across both objectives, translating into measurable improvements in revenue impact, user engagement, and advertiser outcomes. These enhancements created a positive business impact across the ecosystem: Uber Eats users receive more relevant recommendations, advertisers achieve higher-quality conversions, and Uber benefits from a healthier, more efficient marketplace.
| Model Performance | pCTR | pCTO | ||
| Metrics | AUC | LogLoss | AUC | LogLoss |
| Gains | +0.93% | +0.70% | +0.66% | +2.0% |
Beyond its immediate application in ads ranking, the Hetero-MMoE with target-aware transformer architecture is highly extensible and serves as a general foundation for multi-objective, multi-task modeling across the platform. It can be adapted to related domains such as ads search ranking or the organic homefeed model, providing a unified, scalable solution to power diverse business needs with consistent modeling principles.
Next Steps
Building on the success of the current architecture, we’re exploring several directions to further enhance personalization and scalability across the ads delivery system:
- Real-time sequences. Integrate real-time user engagement signals to capture evolving intent and improve responsiveness in ad serving.
- Extended features. Broaden the range of engagement types and introduce flag sequences to distinguish between ad-driven and organic interactions, enriching the model’s understanding of user context.
- Longer context. Extend the sequence length to model deeper behavioral history, enabling the system to learn from long-term engagement patterns and preference shifts.
Conclusion
Through the integration of target-aware transformer encoders and the Hetero-MMoE framework, we’ve significantly advanced the personalization and effectiveness of Uber’s ads delivery system. These upgrades allow the model to capture lifelong user engagement patterns, learn complex cross-feature interactions, and optimize across multiple business objectives simultaneously, resulting in measurable gains in ad relevance, conversion performance, and overall marketplace efficiency.
Beyond immediate improvements, this work establishes a scalable and extensible modeling foundation for future innovation. The architectural flexibility enables seamless adaptation to other ranking and recommendation systems across the platform, while setting the stage for deeper personalization through real-time sequence modeling and generative ranking approaches.
Ultimately, this evolution represents more than just a model upgrade. It’s a step toward a unified, intelligent ads ecosystem that continuously learns, adapts, and delivers value to Uber Eats users, advertisers, and the broader Uber platform.
Acknowledgments
The progress described in this blog wouldn’t have been possible without the collaboration and support of teams across Uber Ads, as well as the broader Delivery and Platform teams. Special thanks to the Michelangelo, Data Science, Product, Ads Delivery, and Organic Feed teams for their partnership in making this work possible.
Our implementation of MLA (Multi-Head Latent Attention) was inspired by the DeepSeek paper on latent attention mechanisms. The Hetero-MMoE framework builds upon ideas from theHeterogeneous Mixture of Experts for Multi-Task Learning paper. We thank the broader research community for their foundational work, which continues to inspire advancements in large-scale modeling and personalization systems.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.

Lance Lin
Lance Lin is a Staff Machine Learning Engineer on the Ads Machine Learning team at Uber, where he focuses on advancing machine learning modeling techniques and system architectures to optimize Uber’s ads delivery platform and improve personalization at scale.

Diego Estrada
Diego Estrada is a Machine Learning Tech Lead Manager at Uber, leading the team responsible for developing advanced ML solutions that power Uber’s Ads systems. His work focuses on building scalable, high-performance models and infrastructure that drive personalization, optimization, and business impact across the Ads platform.
Posted by Lance Lin, Diego Estrada