
Apache Spark™ is an open-source, distributed processing system used for big data workloads. It utilizes in-memory caching, and optimized query execution for fast analytic queries against data of any size.
Figure 1 depicts the spark cluster overview. The driver program is where most of the application logic runs alongside Spark’s scheduler and other infrastructure components, including those that talk to the Resource manager and get the necessary containers. The other is the executor, which gets work from the driver, executes it, and returns the result to the driver. In a cluster, there is only one driver and multiple executor processes, which might be short-lived compared to the driver’s run time.
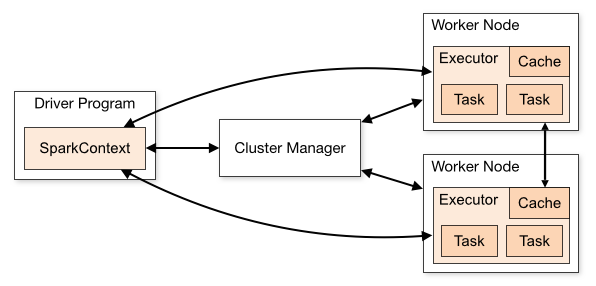
This blog focuses on the reliability and efficiency of executor processes.
The Issue of Executors’ Out-of-Memory (OOM)
Does the error message in Figure 2 look familiar and have your applications failed due to it? Well, the error means that an executor of yours failed with an out-of-memory exception. By the way, it is one of the most common errors in Apache Spark™!

Why Do They Happen?
An OOM scenario can happen due to many reasons. No one purposefully writes code to produce OOM exceptions, but when it comes to Apache Spark™ it is not just the application logic written. Here are a few other factors:
- A Spark task handling a skewed partition
- Organic increase in the input data handled by the pipeline
- Some Spark operations explode, creating a larger-than-expected number of records
- A genuine (or buggy) application that needs larger memory in few flows compared to others
- Infrastructure changes, dependent libraries
Challenges of OOM Exceptions in Spark
A few characteristics or challenges around this error:
- Debuggability and failure reproduction is extremely challenging
- The error does not follow any particular pattern
- Over a while, even well-tuned apps can encounter this error
Impact on Uber’s Pipelines
Failing of Spark applications due to executor OOM exceptions is very common. Uber is no exception to this! At Uber, we realized that these failures affect reliability and, less obviously, are also expensive in time and resources wasted. Assume an application that ran for hours and consumed a lot of resources, and then failed with OOM. All the work done by the application gets wasted, and the application needs a restart. Most errors require user intervention to make the applications work. The on-call teams sit on the edge of their seats, hoping that the pipeline doesn’t fail with an OOM in crunch situations.
The worst part of this saga is that there are not enough tools and insights to solve this problem!
How to Fix OOM Exceptions
“Come on, this is easy! Increase the executor memory and reduce parallelism!”
Or in Spark terms, “Reduce spark.executor.cores and increase spark.executor.memory!”
This has been the unwritten mitigation step followed by many at Uber for ages. If one looks it up on the internet, many blogs try to tell the same steps above in different forms.
Some users run many trial-and-error cycles to find the “best” config where the application finishes reliably. This approach works on many occasions. Yet, it could be far from either being reliable or efficient. If an OOM exception repeats, the exercise needs to be redone.
And we circle back to not having enough tools and insights to tell how efficient the fix was in the first place.
The Design of Spark’s Scheduler Logic
The exception has much to do with the goal and architecture of the Spark engine. For Spark, it has always been about maximizing the computing power available in the cluster (a.k.a., the number of executors’ cores/task slots of the executor). Its scheduler algorithms have been optimized and have matured over time with enhancements like eliminating even the shortest scheduling delays, intelligent task placements, speculative executions, etc.
Despite these optimizations, unfortunately, the “memory asks” of a task is nowhere considered. The argument favoring this could be, “It’s hard to predict the memory ask pattern of tasks.”
And thus the schedulers are not tuned for memory, and that’s where the root of this problem lies.
Understanding OOM Exceptions
In a multi-threaded, Java-based application, it is very hard to separate the memory allocation amongst the threads running in the JVM. This constraint of Java is very critical in understanding OOM exceptions in Spark.
To help understand this, we introduce a term here: the compute-to-memory ratio. This ratio indicates how the computing power (a.k.a., the cores in the executor) and the memory capacity of an executor are configured.
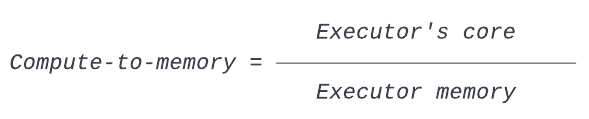
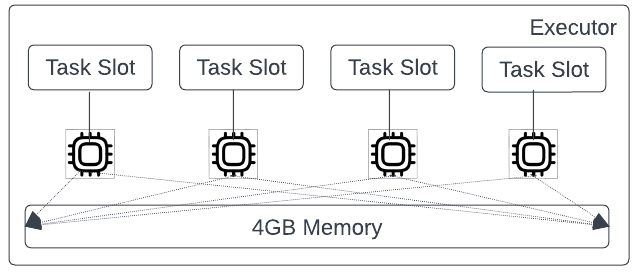
Figure 4 illustrates a Spark executor. It has four cores and 4GB of memory. For simplicity, let’s assume that one core is sufficient to run a Spark task. In terms of Spark configurations:
- spark.executor.cores=4
- spark.executor.memory=4G
With this configuration, the driver gets to schedule 4 tasks concurrently on each executor. And for these tasks, the compute-to-memory ratio for a task is 4 cores: 4GB = 1:1.
Now Spark’s scheduler keeps scheduling tasks to maximize the compute and assumes that the compute-to-memory ratio of the tasks would remain constant. And this assumption leads to OOM exceptions–let’s see how.
Let us try to run a stage with 20 tasks (Figure 5). Let us split the tasks in it into two groups:
- Memory-intensive tasks: 1, 5, 10, 15, and 19 are memory-intensive and each of these tasks needs 3GB to finish their work. Note that the Spark scheduler does not know this information!
- Normal tasks: The rest of the tasks of the stage need only 1GB.
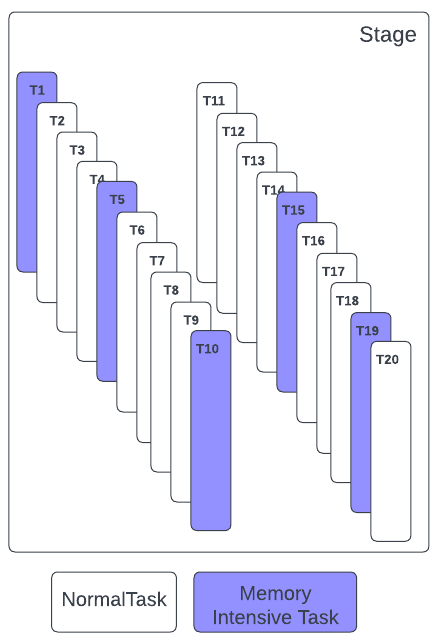
If we express this in the compute-to-memory ratio, then it is 1:3 for memory-intensive tasks and 1:1 for others.
Assume the cluster has two executors. The Spark scheduler picks a combination of 2 sets of 4 random tasks, in which one of these memory-intensive tasks gets picked.
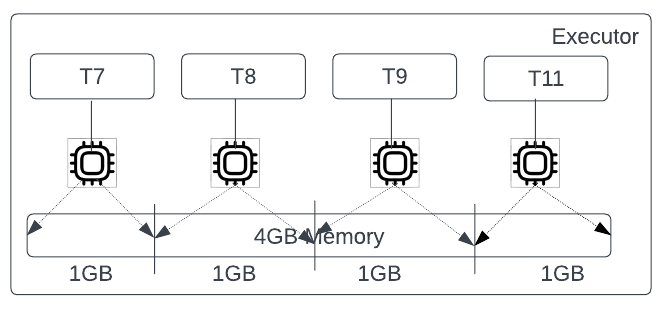
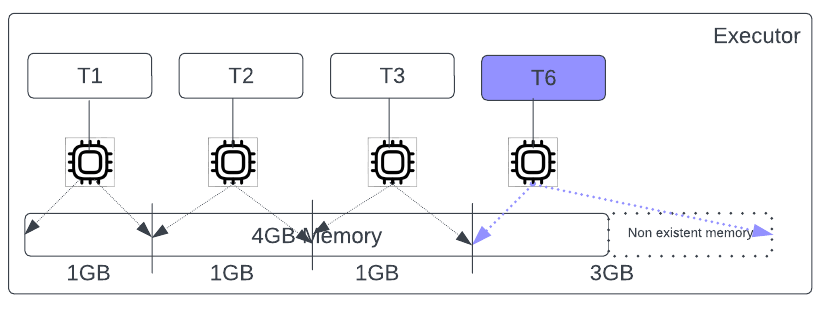
As shown in Figure 6, each of the 4 tasks needs 1GB of memory, and the executor’s memory is sufficient for the requirement of these. However, as shown in Figure 7, the executor’s memory is not sufficient for the 4 tasks, as their combined requirement is 6GB. This leads to an OOM exception on that executor.
Spark’s Retry Logic
When an OOM exception happens (actually, it is true for any error) Spark engine retries the failed tasks a fixed number of times. If all the reattempts fail, Spark fails the application.
Case of Unpredictability
Spark’s reattempt logic is naive and does not consider the reason for failure. If these tasks get scheduled together again on another executor, there is a very high probability that the executor would also fail with the same error. And if this happens a couple more times, Spark will give up the application. However, practically the scheduler’s logic is based on complex state machines that are too fine to control from the outside and thus make it hard to predict when and where the tasks get scheduled.
On the executor front as well, a lot depends on how the JVM schedules these tasks, how well GC operates, etc which are all beyond the control of naive application developers, which makes the OOM exceptions more random and unpredictable.
So it’s fair to say that it’s by chance or by sheer luck that your Spark applications are finishing successfully. And that’s not a good thing when we are talking about enterprise-grade reliability.
Impact of Configuration Changes
As discussed earlier, as a “simple and easy fix”, users try to manually adjust the compute-to-memory ratio by changing the two config values. The below table shows some of the config values one could choose and the ratio it ends up with.
| spark.executor.cores | spark.executor.memory | Compute-to-memory ratio |
| 4 | 4 | 1:1 |
| 2 | 4 | 1:2 |
| 1 | 4 | 1:4 |
| 4 | 8 | 1:2 |
| 2 | 8 | 1:4 |
| 1 | 8 | 1:8 |
Well, there are a lot of combinations of which many might work and many may not. The user must depend on their experience in choosing the most appropriate one.
Trading Efficiency for Reliability
Well, the tough part of this whole OOM exception is, how does anyone know how much memory the task needs in the first place? We talked about 1 and 3GB earlier for understanding the working. But in the real workload, it is hard to come up with those numbers. That involves a lot of trial and error and human patience.
Let us make it even harder: what if the memory asks of the memory-intensive tasks increases? How long will it take to get to a reliable configuration each time?
Many application developers and pipeline owners increase the memory configuration to a very high value to accommodate the dynamics of memory and its impact on the application’s reliability. They trade efficiency for reliability.
Issue of Static Configuration
Another unfortunate fallout of Spark’s design is that these configurations apply to all tasks of the application. Assume less than 1% of a very costly application is memory intensive. Now the skewed compute-to-memory ratio applies to all the executors and tasks of the cluster. There is no provision to tune these configs. Thus if someone looks at the stage-level or application-level efficiency metrics, it would echo the complaints at Uber.
“For many of the Spark containers, the memory utilization has been poor!”
At Uber, efficiency is as important as reliability given the scale and infra cost it has. One wonders if the configuration had been a bit better, the overprovisioned memory could have been used to help other starving pipelines.
If the question in your mind was, “What can be done?”, we just heard it!
An Art to Engineering
Handling OOM exceptions was considered an art that a pipeline owner learns over time and a niche skill. With `Dynamic Executor Core resizing` we made it an engineering problem to solve. It gives predictability to the exception. This feature enriches the Spark scheduler by making the memory needs of a task a parameter of scheduling.
Learning from the Past
The scheduler keeps track of the tasks that run on an executor. When the executor fails due to OOM exceptions, the feature helps the scheduler understand that these tasks are memory intensive and should not be scheduled together. To keep things simple, the feature assumes all tasks running on the lost executor as memory intensive. Trying to pinpoint the exact tasks causing OOM is going down a rabbit hole.
Memory as a Schedulable Parameter
As mentioned in an earlier section, the application developers and pipeline owners resort to changing the compute-to-memory ratio for the application. The feature takes away this manual intervention. If one has to express this in terms of compute-to-memory, the scheduler picks the most memory-safe option for these tasks. On reattempting to run the tasks, the feature forces the scheduler to allocate a full executor to each of these tasks. In other words, no other tasks get scheduled along with these rescheduled tasks on an executor.
Let us understand with an example:
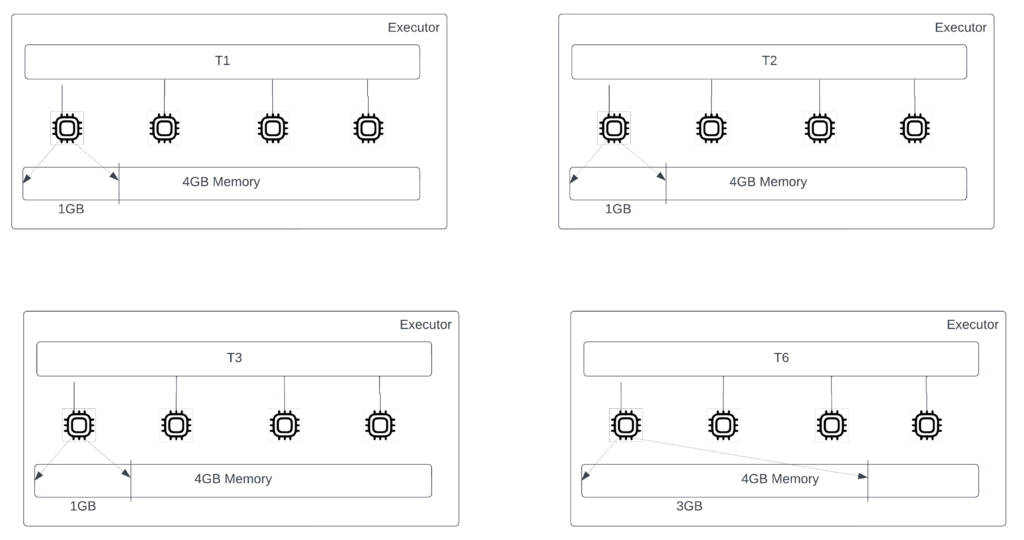
Back to Figure 7, where the executor failed with the OOM exception. When the first task set fails with OOM Exception, the scheduler finds the tasks running on them (T1, T2, T3, and T6). The feature marks all the tasks in that set as memory intensive.
Before rescheduling these tasks, the feature dynamically adjusts the compute-to-memory ratio to 1:4, only for these 4 tasks. It forces the scheduler to look for executors with all its cores free. In other words, all the cores of the executors will be merged to create a single task slot. Figure 8 illustrates the new look of the executors to run memory-intensive tasks. Since no other tasks get scheduled along with it on an executor, the complete memory of that executor is at its disposal. Note that we are not changing the hardware spec of the executor here.
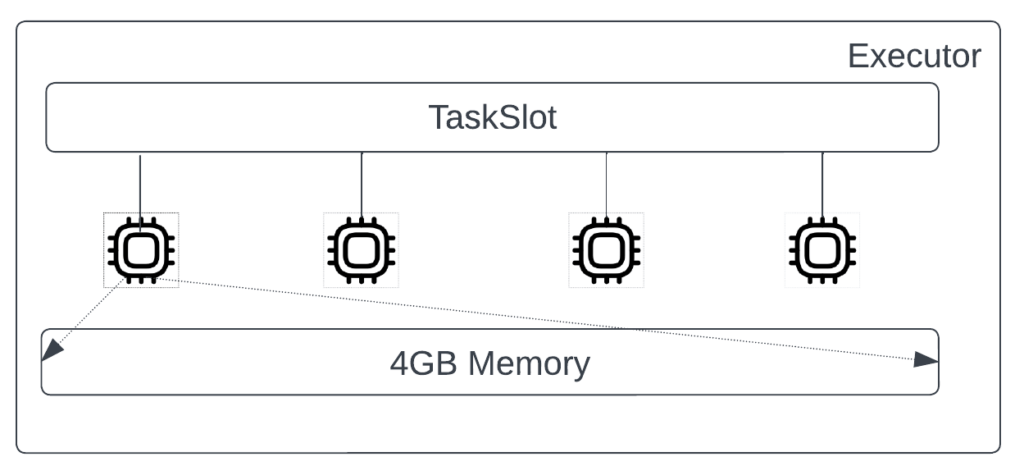
Figure 9 illustrates the reattempt and memory usage of the memory-intensive tasks. Now the memory needs of all the tasks are within the available limits of the executor. This ensures all these tasks finish with definite reliability.
Impact
An attentive reader would have noted these key points:
- Zero human intervention: Without any human intervention, the Spark engine has adjusted the compute-to-memory ratio automatically only for the memory-intensive tasks while keeping the default ratio for other tasks.
- Guaranteed reliability: If OOM happens due to increased concurrency, the Spark engine will ensure each failing task gets a complete memory available, thus reducing failure chances.
- Improved efficiency: With reliability guaranteed by the feature, pipeline owners can now configure fatter executors for their application as it gives better efficiency in using the resources.
- More tasks marked memory intensive: While T6 was only a memory-intensive task, the colocated tasks were also marked equally intensive. This slightly affects the runtime of the application.
- Non-intrusive: The feature is designed to be reactive, and kicks in only when there are OOM exceptions in the system.
- Fail fast: As an add-on, this feature fails the application faster if a memory-intensive task fails with OOM exception despite having all the memory, and not wasting compute in blindly retrying. That’s a genuine out-of-memory case that needs a higher container size and manual intervention.
Conclusion
The feature was rolled out to most of the pipelines at Uber. The feature kicks in and saves around 200 costly applications daily. Also, the pipelines have got more efficient and their owners were now very clear on the steps to fix further OOM exceptions. This feature is an example of the work at Uber towards efficiency improvements in Uber’s 2.X and 3.x versions, and more exciting works on 3.X are underway. Stay tuned for such updates.
Cover Image Attribution: Image by Lemsipmatt and under CC BY-SA 2.0.

Kalyan Sivakumar
Kalyan Sivakumar is a Staff Engineer on Uber’s Data platform team. He spent most of his career on database engine internals. At Uber, as a part of the Batch Analytics team, he focuses on projects on reliability and efficiency improvement.
Posted by Kalyan Sivakumar
Related articles

How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global


Most popular

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale

Scaling AI/ML Infrastructure at Uber
How LedgerStore Supports Trillions of Indexes at Uber

Migrating a Trillion Entries of Uber’s Ledger Data from DynamoDB to LedgerStore
Products
Company
