
Introduction
An invoice is a commercial document issued between two parties (a seller and a buyer) that lists the goods and services provided by the seller to the buyer, indicating the agreed-upon prices and quantities. Invoices back up the information a given party provides to the government, and they serve as a reliable data source when audits are carried out. In some markets, in addition to issuing an invoice, the sale transaction should be reported to the respective government electronically (the so-called e-invoicing).
In this article, we want to share our journey migrating a business-critical large-scale invoice generation service to its successor, some of the challenges we faced, and lessons learned.
The Motivation Behind the Project
For close to a decade, validation, generation, reporting, and distribution of invoicing documents at Uber were handled by a single service. Written in Python, that service was called Invoice-gen – a name that is still used to this day at Uber. Early design choices, ever-changing business requirements, and years of accumulated technical debt had made the service challenging to maintain while the legacy software and infrastructure stack made it difficult to scale with the ever-growing business of Uber. The feature velocity was dropping, since some of the new use cases couldn’t be handled by just extending the service. This led to the introduction of custom solutions, which were defeating the purpose of a common platform.
Because of that, migrating to a new service was a frequent discussion topic among engineers. As with any big project, trying to squeeze it in between countless business launches and deadlines proved to be unmanageable.
What tipped the scales was Uber’s commitment to continuously modernizing our technology stack. When Python was announced to no longer be a supported language for backend services development, we got that final nudge and the leadership support we needed to begin our journey.
Architecture
From the point of view of our stakeholders, this migration was supposed to be seamless. Invoices are official documents that must adhere to a previously approved compliant format. These were strict guidelines, which couldn’t be easily altered. Our service is also business-critical. If invoices are not generated within SLA, Uber could face a business shutdown. On a very high level, our service had to ingest trip data through a Kafka topic and based on the given use case generate an invoice for that event.

Both the legacy Invoice-gen and the next-gen service had to follow the same steps, and to a certain extent, those can be considered separate building units that are to be executed one after another.
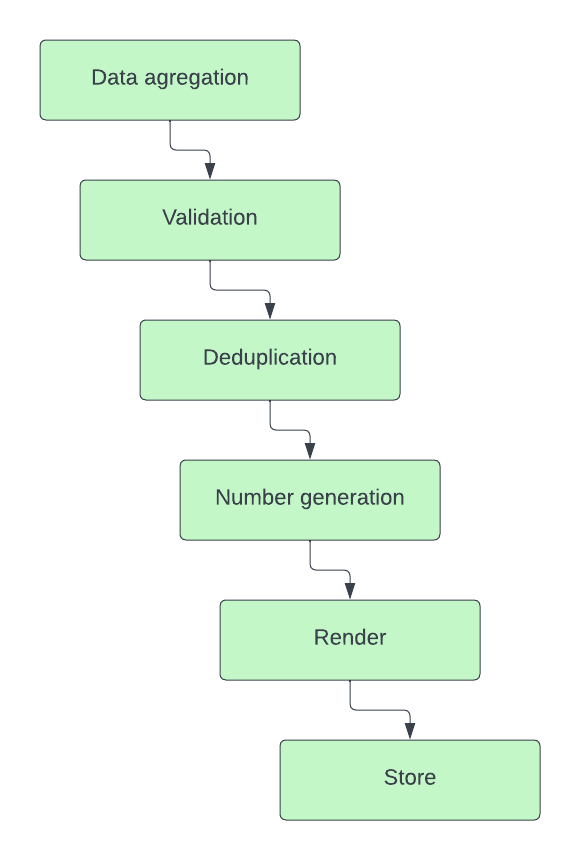
For the most part, Invoice-gen was following the same idea in its architecture. Invoice-gen was in practice a state machine. Each building step was a separate execution block, manipulating the previous data and keeping a record in our temporary storage database before it sent the data through several Redis task queues. At that point to issue a single invoice, an event would have to pass through 4 different queues and have an entry saved or read from a total of 12 different tables.
Invoices got stuck. Invoices got lost. Support requests were piling up.
The migration allowed us to take a look at the previous architecture we had and address some of the key points that we realized no longer worked for us. Revisiting the logic of deduplication (every invoice has to have a unique number) and invoice number generation allowed us to remove the state machine and lower the number of tables required for the generation of an invoice from 12 to 2.
How Did We Migrate?
Bootstrapping the New Service
First of all, we chose to build our new service, named Invoicer, in Go, which was one of the recommended programming languages at Uber. Go gave us the speed and the flexibility we needed in order to handle the high-scale demand we had. To give you a perspective, at peak loads, the service had to produce over 300 PDF invoices per second.
Team Structure
In terms of team setup, we first tried to handle it like any other big project among the business’ many. This proved ineffective as we addressed no more than 10% in the first 6 months. Multiple last-minute requests from external teams, challenging product launches, and other factors pushed our resources more into product development than into the deprecation. That is why we decided to dedicate a team focused entirely on invoice-gen deprecation. The team had its own complete set of scrum rituals, as the only touchpoint with the broader team was the Sprint Demo. The design discussions were open to everyone, and all decisions were documented, with at least 2 reviewers for each team.
Component vs Flow-Based Migration
Kicking off the migration, we had to make a decision: How will we deprecate a service that has accumulated several years of technical debt? We evaluated 2 choices:
- Component-based migration: Breaking down the whole system into small components. Then each component is prioritized according to its place in the flow and the team’s needs. Each component is being rolled out separately. The components are usually a set of functionality that can be reused by different flows.
- Flow-based migration: There are multiple different flows in our service, usually based on the line of business (LOB). One way for us to migrate was to do the design and implementation of a given flow in a single iteration. This way we can focus on an E2E flow (e.g., the flow of an invoice for a ride trip) and implement the needed functionality for that flow. Once we are ready, we start a country-based shadowing and rollout process of the whole system.
| Component-Based Migration | Flow-Based Migration | |
| Pros | Iteratively delivering business value Constant feedback loop Sharp focus on a single problem Easier prioritization Easier work parallelization A sense of moving forward | Single engineering design session per flow, where the end design is clear from scratch Single country-based shadowing and rollout Faster due to reduced rollout overhead |
| Cons | Lack of holistic picture of what we will end up with Multiple country-based verification and rollouts | Business value will be delivered at the end of the effort The feedback for a design decision will be received multiple months after it was taken Lack of a focus area |
One of the key factors that were paramount for our success was the ongoing iterative business value delivery. We couldn’t afford to ask the business to stop and wait for the whole solution to be in place (a.k.a., the flow-based migration approach). Instead, we decided to maximize faster component delivery that can be put into production as soon as the module is developed. This made the decision to use the component-base migration the most suitable for our use case. The biggest drawback of the decision, without any doubt, was the lack of a holistic picture of the end product. To mitigate that we decided to set a simple rule: all components in the workflow had to work only with a single data model, which will be used for data aggregation, storage, analytic export, template rendering, and invoice data representation.
In order to be able to do a component-based migration we had to introduce Invoicer in the production flow. As with most of the migrations happening at Uber, we went through a process of traffic shadowing. This means that every upstream event was ingested by both services and the service doing shadowing was just comparing its outcome with the result from the production service without causing any side effects.
Once we ensured Invoicer was ready to act as an entry point for the whole flow, it started ingesting all upstream events. This way we have put Invoicer at the start of the production flow. And at that point, it was mostly serving as a proxy (via an HTTP call) to Invoice-gen, which was still doing the majority of the work.
The order by which the components were migrated depended on the overall system flow. We started top-down and for each component, we had to evaluate if we would completely change the way it operates or if we can preserve the overall idea.
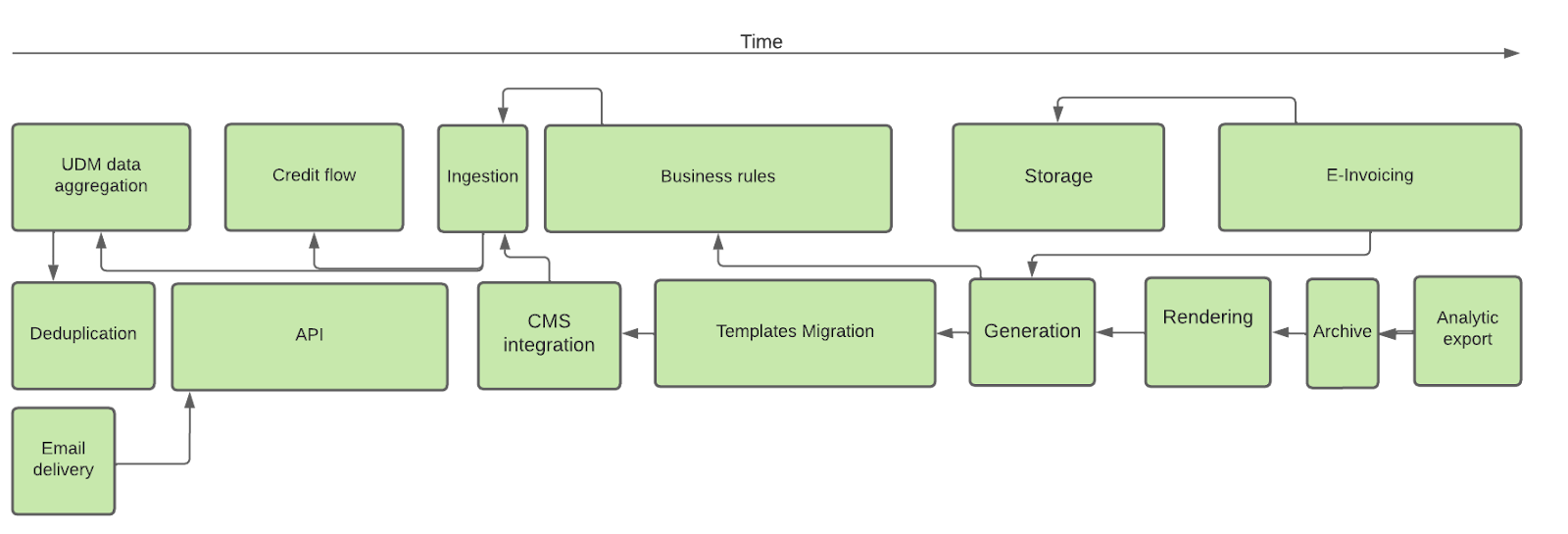
The diagram above illustrates some of the components and their dependencies. Focusing on the different components one by one, enabled us to come up with a few key improvements that significantly reduced the operational costs. Below is a non-exhaustive list:
- Unification of the data model: Before the migration we used a different invoice representation for storing, validating, rendering, analytics, and invoice retrieval. In total, we had 7 different models, which effectively meant that showing a new field on the templates required all models to be updated. That is why we decided to consolidate all of them into a single one: UDM (Unified Data Model).
- Unification of the invoice templates: Issuing compliant documents in almost the whole world, led to the creation of hundreds of different templates. To enable non-engineers to modify them, we integrated the invoicing service with a CMS (content management system) and reorganized them into a hierarchy. After multiple conversations with the local tax experts, we managed to consolidate all existing templates into a single root template, with minor country-specific modifications.
- Config-based validation rules: 25% of all commits for a calendar year were related to invoicing validation rules. It was clear that the legacy schema validation was not scaling well for Uber. So we devised a lightweight config driver validation rule engine, relying entirely on the already-introduced UDM. As of today, 100% of the changes in validation rules are driven by non-engineers.
- Database Redesign: The introduction of the new data model and the rewrite of the system enabled us to reduce the number of reads and writes to the SQL database 2 times, while maintaining the same memory footprint, despite the more verbose model.
- API redesign and generalization: The existing API endpoints were created to serve only specific use cases and couldn’t scale with the pace of the business. Based on that we redesigned them more generically, enabling us to not only cover what we knew but to also make them future-proof.
Impact
While the benefits of this migration may not be obvious at first glance, prioritizing it allowed us to improve a lot of inefficiencies. First, it allowed us to improve the performance of the system in several ways, like reducing the number of nodes needed to run the service, and thus reducing the operational cost. After the migration to the new service was fully completed we reduced the computing requirements by almost 97 percent, releasing hundreds of nodes while processing the same amount of traffic. Additionally, we also managed to reduce the size of the MySQL cluster, which improved performance and prevented database bottlenecks.
We also increased the self-serve capabilities of our system by allowing non-engineers to do configuration changes and launch new markets. This allows the engineers to do engineering work instead of being needed for every business model change, reducing engineers’ support work from 60% to less than 20% of their time. What is more, entirely new use cases and business models can fit into the existing setup without doing any additional code changes.
What’s Next?
The path for our service is clear: deliver more with less. We will continue investing in our platform so that whatever business case is thrown at us, we can handle it by just enhancing the existing setup.
The best sign we saw was the shift in the nature of the work our team does now compared to 2 years ago. From supporting every business case individually to scaling and maturing our platform, so that engineers can work on creating and enhancing features that can scale throughout the vast world of business cases in Uber.
Concluding Thoughts
We learned a lot, especially when it was the hardest. The main takeaways for us were:
- Doing the right thing can be hard and (usually) takes more time, but you need to keep that course throughout the whole journey.
- Be bold–don’t be afraid to challenge previous decisions and redo/simplify things when you see a chance. Often things can be done in more complicated ways than needed.
- Great minds don’t think alike–don’t be afraid to challenge the ideas in your team. As long as ideas (not people) are being challenged, you will get the best out of everyone.
Every service migration and team can be different, but there are common patterns.
We hope our success can inspire you to take that first step in your journey.

Georgi Zhuhov
Georgi Zhuhov is a Senior Software Engineer on the Tax Invoices team.

Irina Kurteva
Irina Kurteva is a Software Engineer on the Tax Invoices team.

Iskren Dimov
Iskren Dimov is an Engineering Manager on the Tax Invoices team. He is passionate about building and sustaining high-performance teams.

Nikolay Lazarov
Nikolay Lazarov is a Senior Software Engineer on the Tax Invoices team.

Plamena Todorova
Plamena Todorova is a Software Engineer II on the Tax Invoices team.

Yordan Petrov
Yordan Petrov is a Senior Software Engineer on the Tax Invoices team.
Posted by Georgi Zhuhov, Irina Kurteva, Iskren Dimov, Nikolay Lazarov, Plamena Todorova, Yordan Petrov
Related articles

How LedgerStore Supports Trillions of Indexes at Uber
4 April / Global




Most popular

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale

Scaling AI/ML Infrastructure at Uber
How LedgerStore Supports Trillions of Indexes at Uber

Migrating a Trillion Entries of Uber’s Ledger Data from DynamoDB to LedgerStore
Products
Company