Uber’s Strategy to Upgrading 2M+ Spark Jobs
25 September 2025 / Global
With over 2 million Apache Spark™ applications running daily, Uber operates one of the largest Spark deployments in the industry. Migrating Spark versions is no simple feat, given the scale and complexity of our operations. This blog delves into how Uber successfully navigated this migration, and the innovative automation and tooling we developed to make it possible.
Introduction
Apache Spark has long been a cornerstone of Uber’s data infrastructure, enabling everything from data analytics and machine learning to real-time processing. Today, users launch over 2 million Spark applications through more than 20,000 scheduled workflows and thousands of interactive sessions each day. Until recently, all of these workloads ran on Spark 2.4. This blog explores the transition from Spark 2.4 to Spark 3.3 and the challenges faced along the way.
Motivation
Due to its out of the box support for Kubernetes as a resource manager, we decided to move to Spark 3.3 to:
- Improve efficiency and save cost from numerous Spark 3.3 optimizations (adaptive query execution and dynamic partition pruning)
- Adopt common vulnerabilities and exposures fixes that make Spark more secure
- Improve developer productivity with features like Koalas™ (pandas on PySpark)
- Onboard other optimizations like Apache Gluten™ and Velox
- Be on par with the latest open-source contributions to Spark
Architecture

At Uber, Spark applications are written in Java®, Scala, or Python. Either Apache Hadoop® YARN or Kubernetes® handles resource management, with both options supported in production.
Jobs can execute in two primary modes:
- As part of scheduled Piper pipelines
- Through ad-hoc execution using the CLI, custom scripts, or internal tools
The source code for these jobs lives in either Uber’s monorepo or micro-repos, depending on the team’s architecture and ownership model.
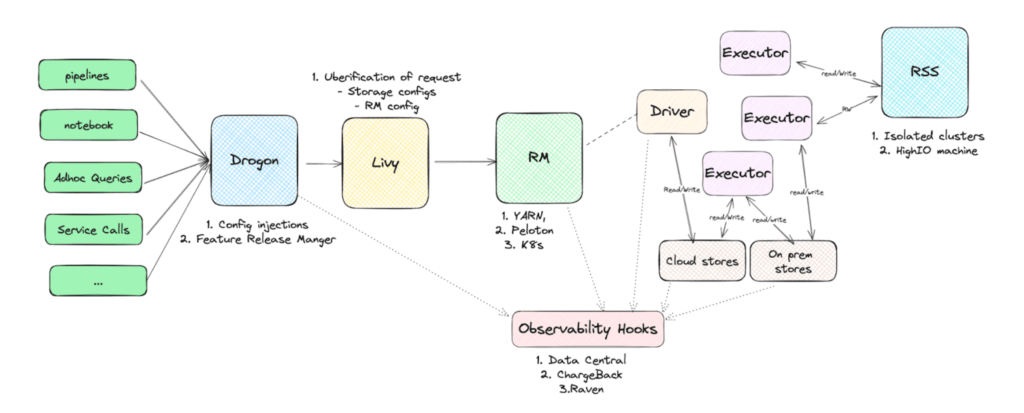
Typically Spark jobs at Uber are submitted through Drogon (our proxy to Apache Livy™) which is integrated throughout the ecosystem powering Jupyter® notebooks, PySpark, Java applications, Spark shells, and more. The app is submitted through Livy to YARN or Kubernetes based on user preferences. There are several observability hooks powering observability, chargeback, and analytics to debug failures. We also have an in-house external shuffle manager called Zeus which is used for most applications with fallbacks to ESS.
Migration Strategy
The migration process involves 4 steps:

- Getting the binary ready.
- Getting the ecosystem compatible.
- Making the Spark 2 apps source code compatible with Spark 3.
- Data validation and shadow testing.
Getting the Binary Ready
The first step is to rebase Uber’s Spark fork with the OSS release. Our internal Spark fork has evolved over the years. For example, we have task-level event listeners that publish memory/CPU consumption. This is used for profiling and optimizing applications. To improve security and compliance, we’ve also coded out column-level lineage and access control support. To reduce local-SSD wear-out, we employ a custom remote shuffle manager called Zeus.
Getting the Ecosystem Compatible
Getting the Spark ecosystem ready for a new migration was all the more challenging. Below is the list of all the dependencies that we had to sort out before we could attempt any migration.
| Dependency | Prerequisite |
| Python | We had to move from Python 2 to 3 for all PySpark applications. |
| Scala | All Scala apps required 2.11 to 2.12 upgrades. |
| Parquet | We made Spark 3.3.2 work with Parquet 1.10 by downgrading Parquet within Spark. |
| Zeus | Our custom shuffle manager wasn’t compatible with AQE. |
| Monorepo deps | All Spark apps are in a monorepo, so we had to resolve popular dependencies like Jackson and Guava. |
Making the App Source Code Compatible with Spark 3
Our Spark apps are written in a Python monorepo as PySpark jobs or they live in a Java monorepo. We have over 2,100 applications of Spark source code. To handle code changes at scale, we had to employ bulk parser/rewriter utilities. We chose Uber’s open-source tool called Polyglot Piranha, originally built to clean up stale feature flag code. By extending its capabilities, we used it to handle the code changes required when migrating from Spark 2 to Spark 3.
Here’s how Polyglot Piranha works:
- Piranha parses the source code into an AST (Abstract Syntax Tree) and uses structural search rules to locate specific patterns.
- Once the target patterns are detected, Polyglot Piranha applies a series of predefined transformation rules.
To leverage Piranha, we defined structured rules needed to identify code patterns and changes required for Spark 3.
Let’s first take an example of a basic code change required for a basic Spark application.
// Before upgrade
val conf = new SparkConf()
.setMaster(master)
.setAppName(appName)
.set(“spark.driver.allowMultipleContexts”, “true”)
sc = new SparkContext(conf)
sqlContext = new TestHiveContext(sc).sparkSession
Our migration tool identifies when SparkConf is initialized and adds relevant set configs accordingly.
// After upgrade
val conf = new SparkConf()
.setMaster(master)
.setAppName(appName)
.set(“spark.driver.allowMultipleContexts”, “true”)
.set(“spark.sql.legacy.allowUntypedScalaUDF”, “true”)
sc = new SparkContext(conf)
sqlContext = new TestHiveContext(sc).sparkSession
In this case, the tool adds the legacy configuration spark.sql.legacy.allowUntypedScalaUDF needed for Spark 3 seamlessly.
Data Validation and Shadow Testing
During the evaluation and proof of concept, we noticed multiple behavior changes with the newer Spark version. For example:
- UDFs don’t maintain backwards compatibility.
array_contains(array(1), 1.34D) returns TRUE in 2.4 and FALSE in 3.3. - Data validation and cast differences.
- The requirement of legacy configs to maintain behavior.
Given the above, it was imperative to do shadow testing and data validation. But doing data validation brought challenges. We had over 40,000 Spark apps, so we couldn’t decentralize the data validation. We also had no notion of a staging environment and couldn’t dry-run in production as it may affect production data. Further, no test cases existed. Even if we could solve the staging environment issue, we didn’t know the baseline of the data to validate against.
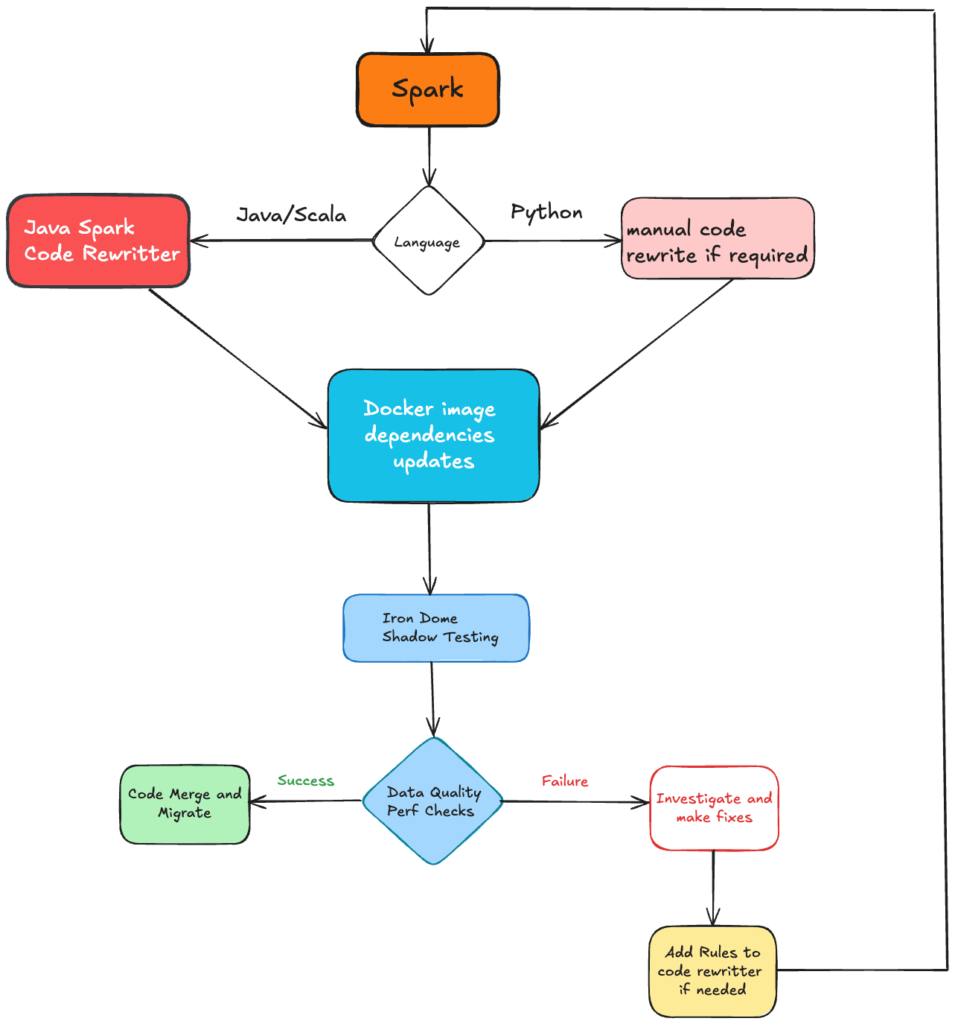
There were no OSS utilities that solved the above, so we built a new framework called Iron Dome that could safely test a Spark job with these features:
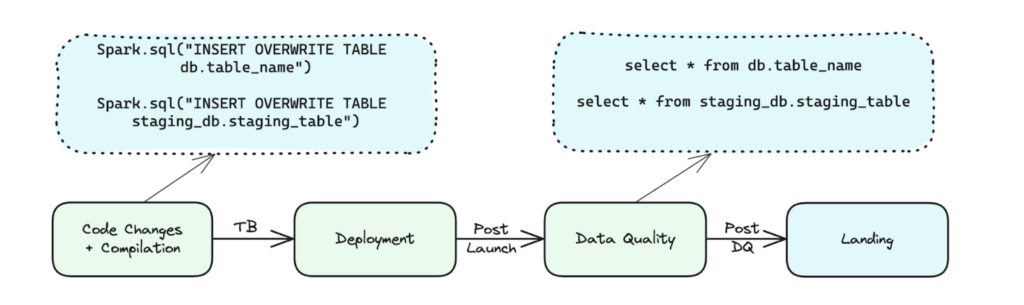
- Safe rewrite: To make sure production paths weren’t affected during shadow tests, we intercepted Spark’s Catalog interface and Hadoop’s File Output Committer. A production path of sort /db/tbl transforms at runtime into /stgdb/tbl.
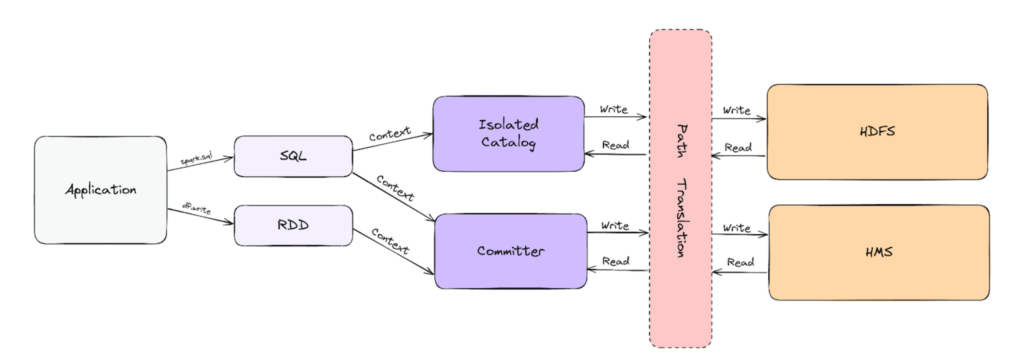
- Guardrails: We also used guardrails at the Hadoop’s FileSystem interface to make sure production paths weren’t affected accidentally.
- Validation infra: The interceptors also published telemetry to a message queue. These included the tables the job wrote to and the paths it touched. We used this information to validate the data against the production counterpart.
- Orchestration: After having the software to safely run and validate, we needed to build a workflow to automatically shadow production runs, validate data, and mark them for migration. We used Cadence to automate the workflow.
Results and Impact
We saw major improvements in efficiency, duration, and cost across jobs, including:
- 85% job migration: Due to automations like Iron Dome and orchestrations, the majority of the 20,000 jobs transitioned to Spark 3 within 6 months.
- Performance improvements: Over 60% of jobs saw more than a 10% improvement, resulting in millions of dollars in total savings.
- Productivity gains: The automated nature of the upgrade also ended up saving thousands of developer/data-engineer hours who’d otherwise have to migrate the jobs individually.
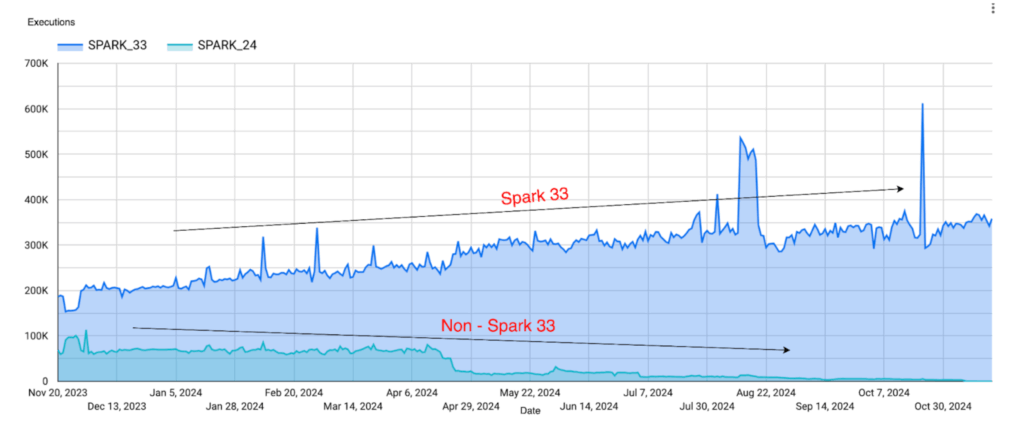
As part of this work, several patches were open sourced, marking this a major infrastructure upgrade for Uber.
The migration also opened up avenues such as Kubernetes and JDK17. Beyond this migration, the agnostic automation build is being used for other upgrades.
Conclusion
We successfully upgraded 100% of all Spark applications to 3.3. This migration resulted in a 50% reduction in runtime and resource usage overall. With the Spark upgrade, several frameworks such as Iron Dome were built, which provided general-purpose sandboxing of Spark applications and paved the way for future Spark upgrades. This accelerates bringing newer Spark features and version upgrades without requiring user intervention. Going forward, we plan to increase coverage for our tooling and support the upcoming Spark 4 upgrade, along with using the tooling for other key infrastructure upgrades.
Acknowledgments
Special thanks to Pralabh Kumar for his invaluable contributions during this upgrade which were instrumental in bringing this blog to fruition.
Cover Photo Attribution: “Sparks” by Daniel Dionne is licensed under CC BY-SA 2.0.
Apache®, Apache Spark™, Apache Spark SQL™, Apache Hive™, Apache Hadoop®, Apache Gluten™, Apache Kafka®, and the star logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Java, MySQL, and NetSuite are registered trademarks of Oracle® and/or its affiliates.
Jupyter® and Jupyter® logo are registered trademarks of LF Charities in the United States and/or other countries. No endorsement by LF Charities is implied by the use of these marks.
Kubernetes® and its logo are registered trademarks of The Linux Foundation® in the United States and other countries. No endorsement by The Linux Foundation is implied by the use of these marks.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.

Amruth Sampath
Amruth Sampath is a Senior Engineering Manager on Uber’s Data Platform team. He leads the Batch Data Infra org comprising Spark, Storage, Data Lifecycle management, Replication, and Cloud Migration.

Arnav Balyan
Arnav Balyan is a Senior Software Engineer on Uber’s Data team. He’s a committer to Apache Gluten™, and works on optimizing query engines and distributed systems at scale.

Nimesh Khandelwal
Nimesh Khandelwal is a Senior Software Engineer on the Spark team. He is focused on projects on modernizing and optimizing the Spark ecosystem at Uber.

Sumit Singh
Sumit Singh is a Senior Software Engineer on the Spark team. His primary focus area is query planning and io optimizations.

Parth Halani
Parth Halani is a Software Engineer on the Spark team. His primary focus area is running Spark efficiently.

Suprit Acharya
Suprit Acharya is a Senior Manager on Uber’s Data Platform team, leading Batch Data Compute Engine (Spark, Hive), Observability, Efficiency, and Data Science Platforms.
Posted by Amruth Sampath, Arnav Balyan, Nimesh Khandelwal, Sumit Singh, Parth Halani, Suprit Acharya