
Introduction
Built on Apache Pinot™, the real-time analytics platform at Uber powers hundreds of critical use cases, from user-facing analytics and experiences to massive internal platforms like log search, tracing, and more. Until 2024, nearly all of the hundreds of millions of daily Pinot queries were served from Neutrino, an internal fork of Presto® optimized for low latency and high QPS. While our Neutrino-based query architecture has served us well over the years, we’ve also faced significant challenges in building a coherent query system over this layered architecture.
Transitioning away from Neutrino seemed extraordinarily challenging a few years ago, since Neutrino could run complex OLAP queries with multiple sub-queries and window functions at high QPS and low latency with minimal reliability risks. While Pinot’s MSE (Multi-Stage Engine) was promising, it was originally aimed at adding full Distributed SQL support, with a focus on completeness. A new MSE query could easily involve large scans or huge joins on arbitrarily large tables, which could impact a tenant’s reliability.
In this blog, we share how we’ve rebuilt our query architecture to begin our transition away from Neutrino. At the core of this transition is the new Pinot MSE Lite Mode, which combines our learnings from Neutrino, Pinot’s single-stage scatter-gather query engine, and the Pinot MSE. Not only is the new architecture simpler, relying solely on Apache Pinot’s query engines, it also significantly increases the overall capability of the system.
Neutrino: Presto Over Pinot Query Architecture
We described Neutrino and how we run it at Uber in a previous blog. To set the stage for our transitioning architecture, let’s run through a quick primer on Neutrino.
High-Level Architecture
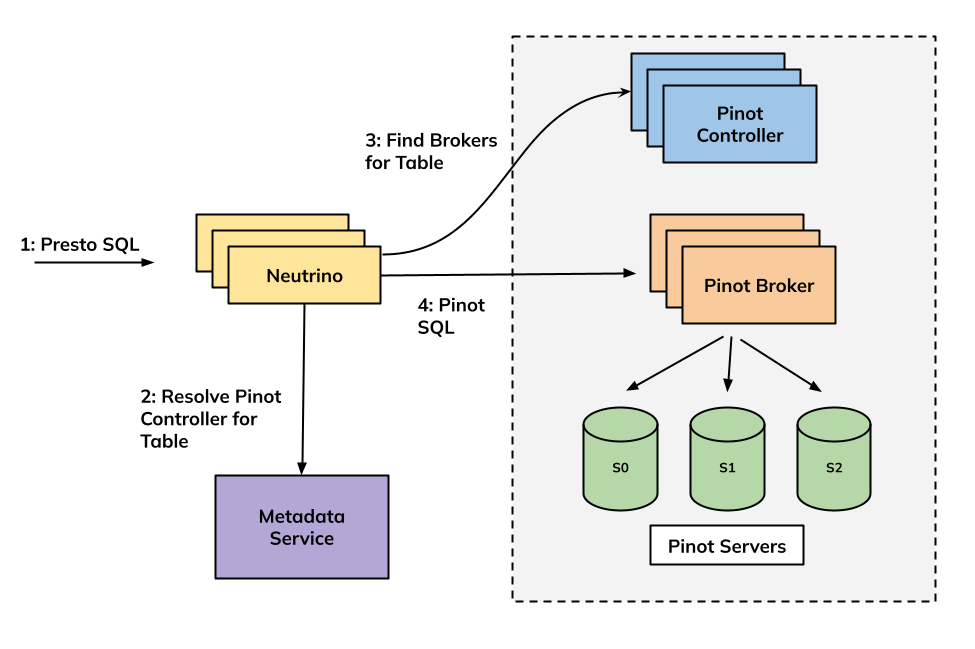
Neutrino is a stateless microservice that runs the Presto coordinator and worker within the same process. Users submit a PrestoSQL query, Neutrino finds the brokers that can serve that query, and sends a Pinot SQL query to the broker. Within Pinot, the query runs using the single-stage engine, which follows a scatter-gather paradigm.
Notably, Neutrino serves both as a query proxy and a query execution engine.
Query Pushdown
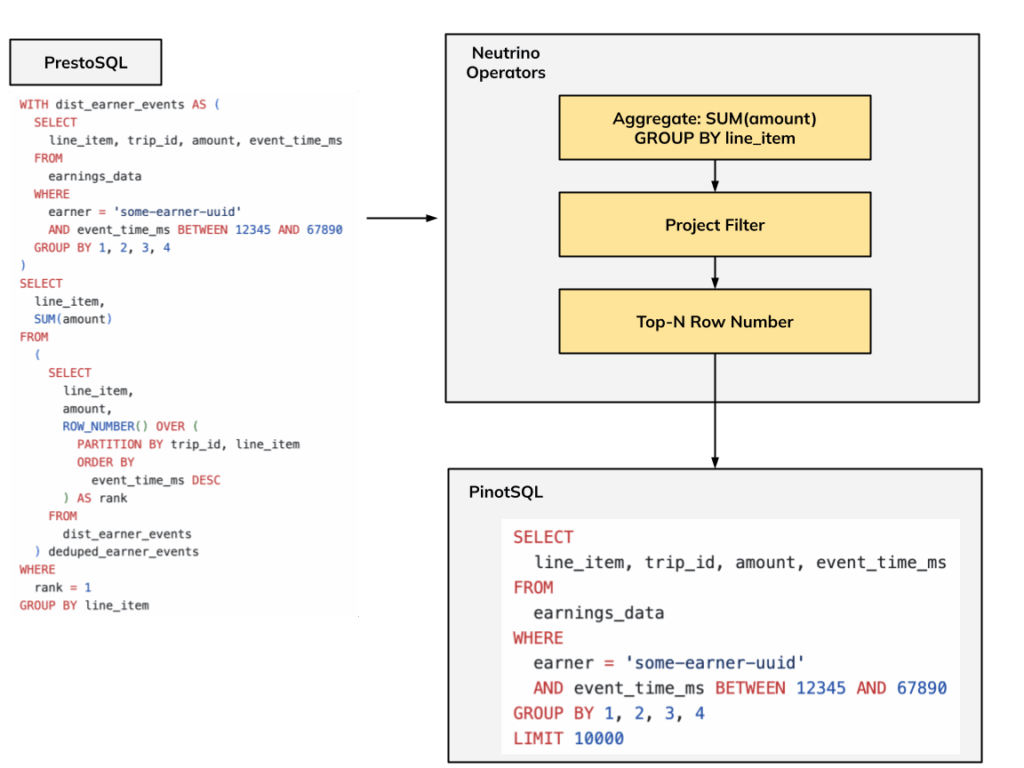
Neutrino generates a plan from the user-submitted PrestoSQL, and finds the maximal sub-plan it can push down to Pinot. The pushed-down sub-plan is converted to a Pinot SQL query, which is submitted to Pinot brokers. The rest of the plan is executed within Neutrino using Presto’s execution engine.
Crucially, the generated PinotSQL query always has a limit. This limit may match the user’s expectations when a sort with a non-null limit is present in the pushed-down plan. But if it isn’t, we add a default limit of 10,000 records and return a warning to the users.
If the generated PinotSQL query doesn’t include any aggregation/group-by, the max allowed limit is set to 50,000 records to prevent large scans in Pinot. If an aggregation/group-by is present, there’s no limit enforced by Neutrino and we rely on Pinot’s grouping algorithm to protect the system.
Advantages
There have been several advantages of this design that have been crucial to our platform’s success over the years.
New use cases, either on existing tables or on new tables, are onboarded every day to our platform. It’s critical that the platform is resilient and hard to break. Neutrino enables complex SQL features like sub-queries, window functions, and so on. Pinot’s single-stage query engine doesn’t support these features, so Neutrino helped unlock a large set of use cases that would have been hard to support with Pinot alone.
Since each query sent to Pinot has a limit, the risk of queries impacting a tenant’s reliability is infinitesimally low. This means that the platform is less likely to break as users onboard new queries or and modify existing ones.
Challenges
This query-pushdown-based layered architecture, where one query engine is layered above another, yields complicated semantics that are hard to understand. Moreover, it can lead to unpredictable behavior, where a slight change in the query leads to a very different query plan. Generally speaking, a visual inspection of the query isn’t sufficient to determine what the pushed-down PinotSQL query would look like.
Moreover, it’s inevitable that you’ll have to add a default limit to the generated PinotSQL query, which changes the semantics of the query and can often lead to partial results.
Finally, our Neutrino-based query architecture means that every query must necessarily go through the query proxy, and there’s no way to bypass it for our bigger use cases. Each Neutrino environment is shared by multiple Pinot tenants, which breaks the resource isolation we get from Pinot.
Pinot Multi-Stage Engine
Originally, Pinot had one query engine, which is called the single-stage query engine. It follows a scatter-gather execution paradigm, and has custom-built planners and operators. It only supported queries with a single clause of each type: SELECT, FROM, GROUP-BY, LIMIT, and so on. Crucially, it didn’t support complex SQL features like subqueries (WITH), window functions (OVER), and joins.
Pinot multi-stage engine, on the other hand, can handle general SQL queries, allowing users to run distributed joins, window functions, sub-queries, and more.
Distributed Joins and Multi-Stage Queries in OLAP
Pinot tables can be as big as hundreds of terabytes with hundreds of billions of records. QPS can go from single digits to the many thousands. For more than 90% of our use cases, users expect sub-second latencies and are likely to send at least 10-50 QPS.
There’s a fundamental challenge in supporting multi-stage queries with such an OLAP system: it’s very easy for users to write a multi-stage query that can’t be supported with the available resources and the latency/QPS requirements. This isn’t just a question of writing better query execution engines, but rather about the fact that without properly defined limits, multi-stage queries can easily exceed the theoretical capacity of even an ideal system. This is shown with the query in Figure 4.

With MSE, this query scans the entire table, which may consist of billions of records. Note that there’s a simpler way to write this query that won’t lead to a full scan, but it’s not guaranteed that users of the platform can figure it out before production onboarding.
Multi-Stage Engine Lite Mode
Pinot version 1.4 introduces the Multi-Stage Engine Lite Mode that combines our learnings from Neutrino with the capabilities of Pinot’s Multi-Stage Engine.
At a high-level, MSE Lite Mode:
- Adds a configurable max record limit for the leaf stage. This limit is visible in the Explain Plan of the query.
- Executes the query using a scatter-gather paradigm. The leaf stages run on Pinot servers, and all of the other operators run using a single thread in the Pinot broker.
The query in Figure 4 fails in one of our clusters, but runs in under a second with Lite Mode.
We’re working on adding a feature in Pinot where users are warned about data truncation due to the Lite Mode limit.
Cellar: Redefining Uber’s Pinot Query Architecture

Our new query architecture is built around a lightweight passthrough proxy called Cellar. Users can use PinotSQL or M3QL on Pinot (powered by Pinot’s pluggable Timeseries Engine) to query their data. Cellar doesn’t modify the query it receives from users, so the only semantics users have to deal with are the ones defined by Pinot.
Our team provides Cellar client libraries so users can query Cellar using PinotSQL. The query is passed as is to Pinot brokers. Users can also use M3QL to query Pinot through our Observability platform. M3QL on Pinot is powered by the Pinot Timeseries Engine.
For most of our users, we’ll continue to recommend the single-stage Pinot query engine. For users that need advanced SQL features but don’t need to run distributed joins, our recommendation will be to use the Pinot Lite Mode. Finally, users that need the full might of the Multi-Stage Engine need to request access and work with our team to onboard new use cases.
Advantages
Multi-Stage Engine Access
Users can enable the Multi-Stage Engine just as Pinot allows it, by using the SET useMultistageEngine=true; statement. Since opening up Multi-Stage Engine for all users is risky as we mentioned in the sections above, we limit access to Multi-Stage Engine using our dynamic config store called Flipr. Only if a user’s server tenant is permitted in Flipr to leverage MSE, will they be able to run MSE queries.
Once we roll out Pinot v1.4 across our clusters, we aim to enable MSE Lite Mode access by default for all users.
Timeseries Engine Access: M3QL on Pinot
In early 2025, we contributed a Generic Time Series Engine to Pinot. The engine can run queries for any timeseries query language, like PromQL, Uber’s M3QL, and so on. We leverage this engine using an internal implementation of the M3QL Timeseries Plugin to support M3QL on Pinot for all users at Uber.
With Cellar, we can expose both SQL and M3QL, making Pinot a powerful tool for observability use-cases.
We talked in depth about how and why we built the Time Series Engine in our talk at RTA Summit earlier this year.
Clients for Java/Go Monorepos
We support official clients for Java and Go monorepos, which come with a ton of features out of the box.
- Clients handle all the complexity of Pinot’s response format and return a CellarResultSet with a neat API.
- Clients enable partial result handling by default. If a query has partial results, the result set contains warnings. Users can choose to retry or simply accept the results, if their use case allows for it.
- Clients enforce best practices like timeouts, retries, and so on. Each cellar query has a timeout attached to it, which is propagated to Pinot via the timeoutMs query option.
- Clients emit metrics around latency, query success/failures, query warnings, and so on. We have a Cellar users Grafana dashboard where every new user can use to get out-of-the-box monitoring.
Direct Connection Mode for Complete Isolation
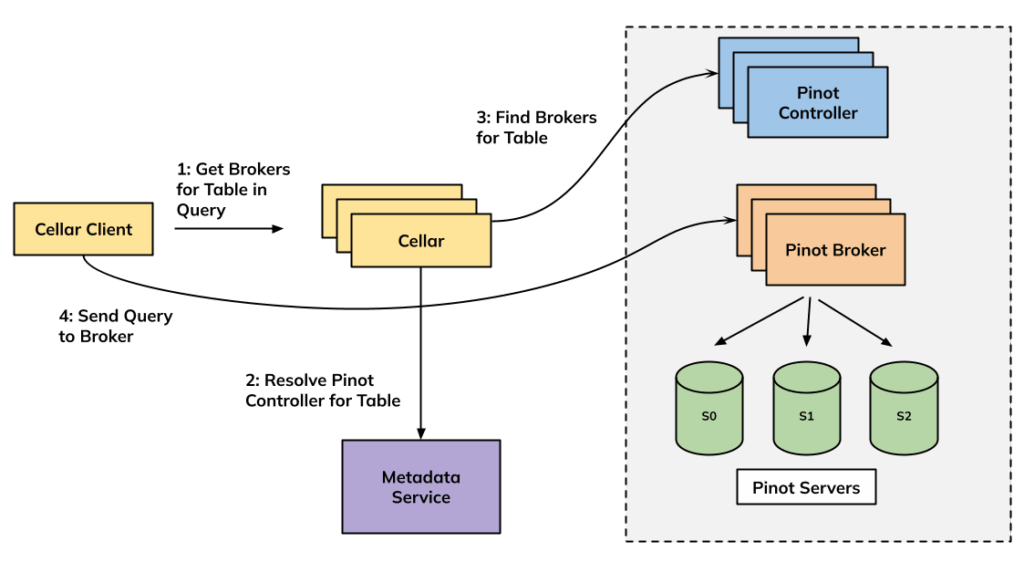
Cellar’s HTTP APIs mimic Pinot broker APIs. That makes it quite easy to allow the Cellar clients to bypass the proxy and directly hit Pinot brokers. It enables true end-to-end resource isolation for dedicated tenants since they no longer have to share a common query proxy environment.
Current Status
Our daily query traffic for both Cellar and Neutrino can vary quite a bit month over month. In terms of QPS, at the time of writing, Cellar’s total QPS is nearly 20% of the total QPS served by Neutrino. It powers many major use cases like Uber’s Segmentation and Tracing platforms.
Over the past year alone, Cellar has unlocked many use cases that couldn’t be supported with Neutrino. With direct connection mode, we’ve also been able to support higher QPS use cases efficiently and with true end-to-end resource isolation.
Next Steps
We’re hoping to release MSE Lite Mode to our users later this year. Based on how that experiment goes, we hope to mark Neutrino as deprecated in the future.
We also plan to improve the Lite Mode further. For example, it might make sense to add support for rejecting join queries by default and only enabling it for some use cases. Lite Mode would also significantly benefit from sub-plan-based execution, where a part of the query is executed first before the compilation for the remainder of the query completes.
Conclusion
OLAP system capabilities and features have continued to increase this decade, and this trend isn’t specific to Apache Pinot. We believe that OLAP systems will continue to evolve for the remainder of this decade, further increasing their capabilities.
Cover Photo Attribution: “castle di Gabiano cellar” by scott1346 is licensed under CC BY 2.0.
Apache®, Apache Pinot™, Pinot™ are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
The Grafana Labs® Marks are trademarks of Grafana Labs, and are used with Grafana Labs’ permission. We are not affiliated with, endorsed or sponsored by Grafana Labs or its affiliates.
Presto® is a registered trademark of LF Projects, LLC.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.

Ankit Sultana
Ankit Sultana is a PMC Member for Apache Pinot and a Staff Engineer at Uber.

Christina Li
Christina is a Senior Software Engineer on the Real-Time Analytics team at Uber. Her work focuses on the Pinot query stack.

Shaurya Chaturvedi
Shaurya Chaturvedi is a Senior Software Engineer at Uber.

Tarun Mavani
Tarun Mavani is a Software Engineer II at Uber.

Shreyaa Sharma
Shreyaa Sharma is a Software Engineer II at Uber.
Posted by Ankit Sultana, Christina Li, Shaurya Chaturvedi, Tarun Mavani, Shreyaa Sharma