
Introduction
In this blog, we dive into the technical challenges of processing financial updates for hot user accounts at scale. A hot user account in this context is a hot-key phenomenon observed in our User Account financial data store, whose disproportionately high number of changes in a row becomes too much for the system to keep up with. We detail how we built the User Account Batch Processing system to handle over 30 update operations per second per user account while maintaining strict consistency guarantees. Let’s explore what we learned from building this system.
Background
Our core payments platform, Gulfstream, serves as an integrated, SOX-compliant platform built on double-entry accounting principles. It uses a job/transaction-based architecture and processes millions of transactions daily. The system maintains the basic accounting principle that money flows between accounts without creation or destruction, and provides an immutable audit trail via UACs (User Account Changelogs).
However, as the platform grew, certain user accounts experienced extreme traffic bursts and volume resulting in hot-key issues that overwhelmed the standard processing pipeline. By 2023, some user accounts needed to handle far more than our system’s limit of 3-4 update operations per second.
For example, large marketplace operators process tens of thousands of daily bulk adjustments against a single user account, taking 21-24 hours to complete. Fleet operators tend to create hundreds of thousands of daily transactions, taking more than a day to complete. Fleet operators experiencing massive payment bursts at specific times create systemic loads that overwhelm processing pipelines. Beyond fleets, certain Uber for Business customers provide subsidies to riders in certain regions. Such campaigns result in tens of thousands of daily transactions against individual Uber for Business customers.
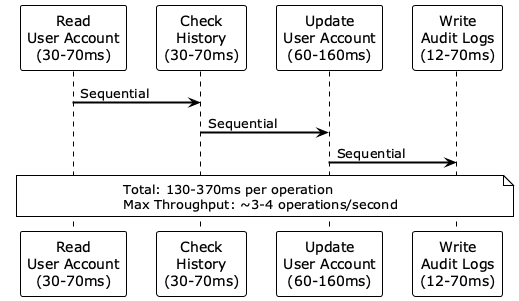
The traditional processing approach required multiple sequential round trips for each operation:
- Reading the user account state (30-70 milliseconds)
- Checking the processing history (30-70 milliseconds)
- Updating the user account (60-160 milliseconds)
- Writing audit logs (12-70 milliseconds)
With total latencies of 130-370 milliseconds per operation, achieving the target of over 30 update operations per second was mathematically impossible through sequential processing. We needed a fundamentally different approach.
Why We Chose Batching
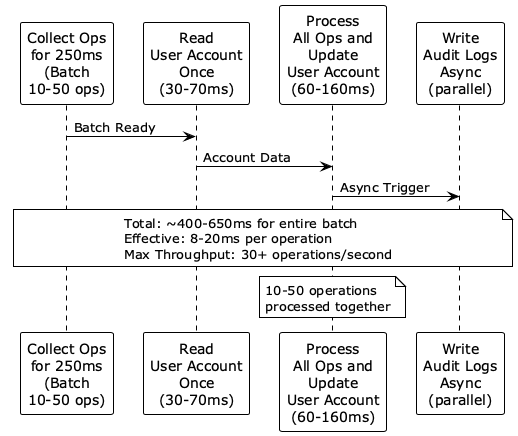
The core insight was that most processing time was spent on data store round trips rather than actual computation. This led us to batch multiple updates to amortize latency costs.
We considered and rejected traditional batching approaches like those based on Apache Kafka® because client-side batching adds delays, consumer-side delays of 1-2 seconds are normal, and Kafka is optimized for high-throughput, but not for sub-second latency.
We have a soft limit of 1 second to support real-time operations like credit card holds. So, we needed a system that could batch operations in 250 millisecond windows. This would be short enough for real-time operations and yet long enough for meaningful throughput gains.
Alternative architectural approaches we rejected included:
- Stream processing with global ordering. Maintaining global ordering in a distributed system was too complex and required frequent compaction.
- Sharded user account. Using multiple Amazon DynamoDB® rows for a single account complicates the single-balance concept and hot account detection.
- Geographical co-location. Moving services closer to data stores only provided a 2-3× improvement, which was insufficient for our 10× throughput requirement.
Design Considerations
When designing the system, we needed to achieve over 30 operations per second per user account while maintaining strict consistency guarantees. We also needed to batch operations in a 250 millisecond window to balance latency and throughput.
Regardless of batch size, we needed to minimize data store interactions to only one read and one write per batch. We also had to ensure an immutable audit trail for SOX compliance.
Finally, the system needed to handle data durability where Redis® data loss affects only individual operations and not entire batches.
Architecture
The User Account Batch Processing system has a three-service architecture: Batch Creator, Batch Process, and Batch Post-Processing. Figure 3 shows how these services work together.
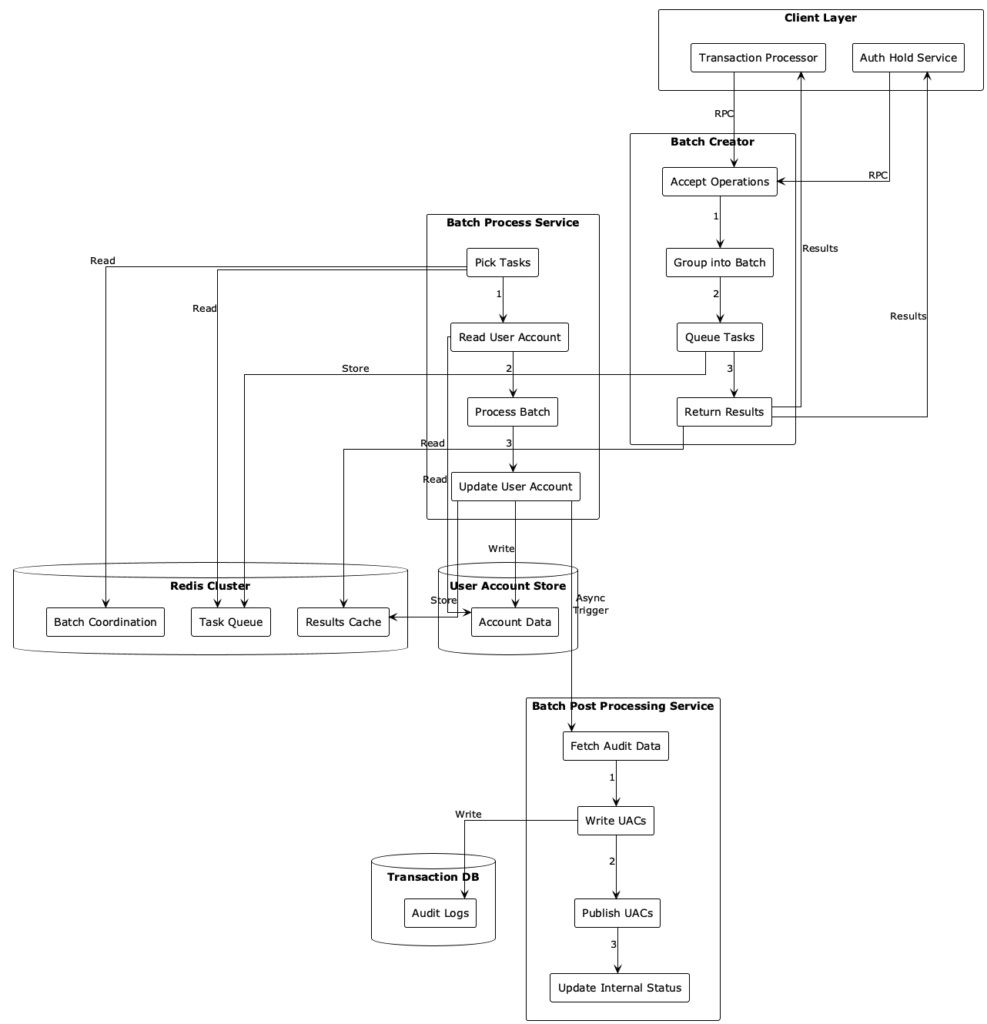
Batch Creator handles incoming operations and groups them into time-bounded batches. It uses Redis for coordination due to its sub-millisecond latency and high RPS capability.
The Batch Process service is the core engine that processes batches by reading account state once, applying all operations in memory, and performing a single atomic update. It uses multiple processors across different zones for fault tolerance.
The Batch Post-Processing service is decoupled from the main path and handles asynchronous audit log generation and publishing.
The system uses a Redis cluster, User Account Store, and transaction database. The Redis cluster is the central coordination layer for batch coordination, the task queue, and the results cache. The User Account Store is the authoritative data store for account balances, designed for minimal interaction (one read, one write per batch). The transaction database stores the immutable audit trail (UACs) for compliance.
The architecture is designed to amortize the latency of data store round trips across multiple operations. The maximum throughput is over 30 operations per second per user account, with an effective latency of 8-20 milliseconds per operation within a batch. The total time for an entire batch is approximately 400-650 milliseconds.
End-to-End Flow
The overall flow of the User Account Batch Processing system involves:
- The Client layer. The system accepts operations from the Transaction Processor and Authorization Hold service, both requiring real-time processing capabilities for financial operations.
- The Batch Creator service. Acts as the entry point and coordination hub for all incoming operations. It follows a four-step process:
- Accept operations. Receives individual operations via RPC calls from client services.
- Group into batch. Uses Redis-based coordination to group operations by user account into time-bounded batches (250 millisecond windows).
- Queue tasks. Places batch-processing tasks into a global Redis task queue for pickup by processors.
- Return the results. Retrieves and returns processing results to clients from the Redis results cache when the results become available.
- A Redis cluster. Serves as the central coordination layer with three key data structures:
- Batch coordination. Manages entity-to-batch mappings, batch metadata, and batch of operations using atomic Lua scripts.
- Task queue. Maintains a list of tasks that need to be executed by batch processors.
- Results cache. Holds processing results for client retrieval, enabling fast response times when results become available.
- The Batch Process service: The core processing engine that handles the heavy lifting of batch execution.
- Pick tasks. Competes with other processors across zones to claim batch processing tasks.
- Read the user account. Performs a single read of the current user account state from the data store.
- Process the batch. Applies all operations in the batch to the account state in memory
- Store tentative audit logs. Audit logs that are generated as part of batch processing are stored tentatively using Batch Post-Processing service.
- Update the user account. Performs an atomic update using optimistic locking to ensure consistency.
- Persist and publish tentative audit logs: Triggers Batch Post-Processing service to store the tentative audit logs permanently.
- The User Account Store. The authoritative data store for user account balances and state. The system is designed to minimize interactions with this store—the Batch Process service makes only one read and one write per batch, regardless of batch size.
- The Batch Post-Processing service: Handles audit trail generation asynchronously to avoid blocking the critical processing path.
- Store audit data. Stores the tentative audit log when requested.
- Fetch audit data. Retrieves the necessary data for audit log generation.
- Write UAC. Creates User Account Changelog entries in the Transaction DB.
- Publish UACs. Publishes audit events to downstream systems via messaging.
- Update internal status. Marks audit processing as complete to avoid repeated work.
- Transaction DB. Stores the immutable audit trail (UACs) required for SOX compliance and regulatory requirements. This is separate from the main processing path to ensure audit operations don’t impact performance.
Benefits
Key architectural benefits and novelties of our design include:
- Sub-second batching. The 250 millisecond batching window balances latency for real-time operations with the throughput required for scale.
- Async audit processing. Decoupling audit trail generation from the critical processing path prevents compliance requirements from impacting performance.
- Optimistic concurrency. Multiple processors compete for the same batch, but an atomic update with optimistic locking ensures exactly-once processing and consistency.
- Minimal data store interaction. Only one read and one write per batch, regardless of the number of operations, drastically reduces total latency.
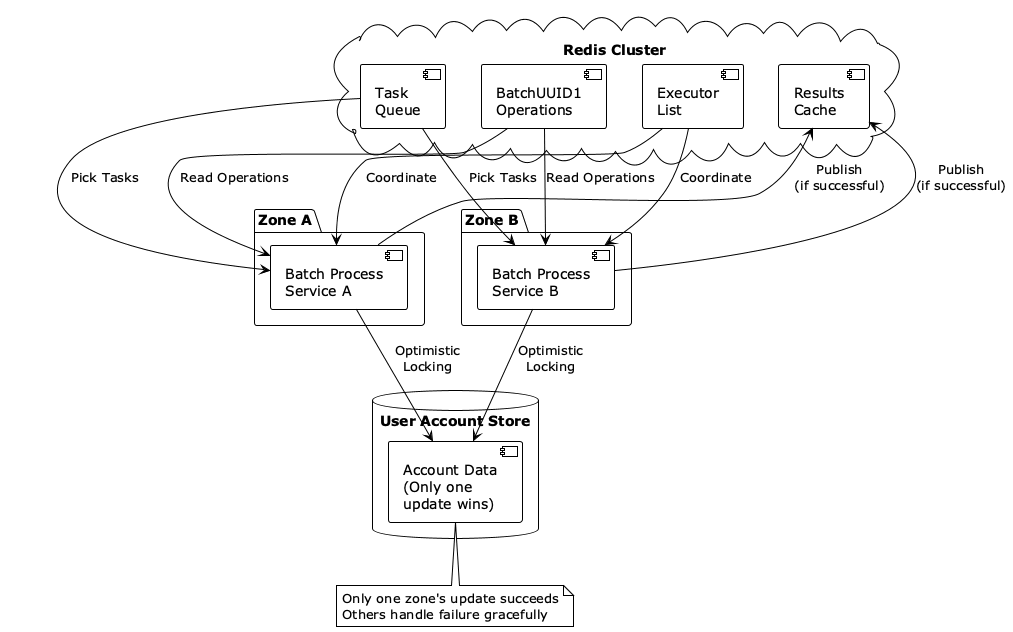
- Multi-zone redundancy strategy. Batch processors run in multiple availability zones, using zone names as executor identifiers, which significantly reduces batch failure rates during outages or deployments.
Development Challenges
Two technical roadblocks and solutions emerged during development: time synchronization and user account size management.
In distributed systems, machines don’t agree on time, which is critical for defining time-bounded batches. To address this, we designated the Redis instance hosting each batch as the authoritative time source. This eliminated clock synchronization issues and ensured consistent batch boundaries.
The other challenge was that traditional audit logs consumed significant space, which could lead to user account size exceeding storage limits during high-throughput processing. To address this, we developed the MicroUAC format, which is less than 100 bytes, significantly smaller than the traditional audit logs, serving the same purpose of giving idempotency guarantees. This was a critical insight for managing user account size at high batch frequencies that came from production testing.
Fault Tolerance Guarantees
We designed the system for failure scenarios. Individual operation failures are isolated, and Redis outages cause temporary unavailability but don’t compromise data integrity. Data durability for the audit trail is ensured using a combination of Redis for speed and Docstore for durability. Multi-zone redundancy also ensures that even during single-zone outages, executors from other zones continue with batch processing.
Validation Strategy
When migrating or building a new system to handle mission-critical, high-volume transactions—like bulk order processing or large-scale financial updates—the potential for errors is huge. A single bug in a high-throughput pipeline can lead to systemic data corruption.
To offer completeness (all work done) and correctness (all data is right), we relied on two powerful techniques: shadowing and stress testing.
Shadowing involves routing a copy of live production traffic to the new system without its output affecting the production environment. The goal is to compare the new system’s behavior against the trusted, existing system’s behavior.
The validation process is split into two critical areas: completeness validations and correctness validations.
The completeness validation step ensures the new system finishes all necessary work items as expected. We validate that:
- Audit logs and transaction records are published and persisted for every transaction
- All requests are definitely processed and correctly reflected in success metrics
- Any required side effects or follow-up transactions are correctly generated
- The system leaves no dangling state (for example, temporary holds or locks that weren’t cleaned up)
During correctness validations, we confirm the arithmetic and state mutations are perfect. A dedicated Validation service queries the results for the two parallel runs. It compares the final account balances or state of account A (legacy) against account B (new system). It also cross-references the state changes in the audit logs against the original input to ensure every transaction updates the account’s state correctly. The ultimate pass criterion is simple: the final state and all associated logs for account A must be identical to account B.
Correctness under normal load isn’t enough. A high-throughput system must perform flawlessly under maximum strain. To identify system limits, we use a dedicated traffic amplification process. Instead of just mirroring live traffic, we apply a multiplication factor (for example, 10×, 15×) to the shadow stream. This allows us to simulate bursts of activity far exceeding peak production volume.
This stress test helps us identify maximum sustainable throughput (requests per second), system latency under extreme load, and hidden bottlenecks or resource contention points (for example, database connection pooling and CPU saturation).
Use Cases at Uber
This system was built to handle accounts experiencing extreme traffic bursts, such as large marketplace operators processing tens of thousands of bulk adjustments. Or, fleet operators generating massive numbers of daily transactions or payment bursts or processing of incentives.
The system now processes financial operations that previously took 21-24 hours in just minutes. This massive performance boost enables new business capabilities that were previously impossible and allows the system to handle extreme traffic bursts while maintaining consistency guarantees.
Conclusion
In this blog, we covered using realtime batching to process financial updates at a speed of 30 operations per second per user account while maintaining consistency guarantees. We use a three-service design for creating batches, processing batches, and post-processing batches. That is, ensuring audit log generation. We discussed how we ensure fault tolerance and keep data size reasonable. This additional ability reduced retries and related noise in our system, creating a significantly better experience for our largest clients.
Cover photo attribution: Whalein sea by Thomas Lipke is licensed under the Unsplash license.
Apache Kafka®, Kafka®, and the star logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. Any use herein is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Apache and Uber.
Amazon Web Services, AWS, DynamoDB and the Powered by AWS logo are trademarks of Amazon.com, Inc. or its affiliates. Any use herein is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Amazon and Uber.
Redis is a trademark of Redis Labs Ltd. Any rights therein are reserved to Redis Labs Ltd. Any use herein is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and Uber.
Docstore are either registered trademarks or trademarks of Uber Technologies, Inc in the United States and/or other countries.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.

Raghav Kumar Gautam
Raghav Kumar Gautam is a Staff Software Engineer on the Gulfstream team at Uber. He primarily focuses on data-related problems. Raghav holds a master’s degree in Internet Science and Engineering from Indian Institute of Science, Bengaluru.

Akshay Kale
Akshay Kale is a Senior Software Engineer on the Gulfstream team at Uber. He focuses on driving the observability, reliability, and efficiency side of efforts within Gulfstream. Akshay holds a master’s degree in Computer Science from the University of Southern California.
Posted by Raghav Kumar Gautam, Akshay Kale