Introduction
Search is a foundational pillar of Uber’s user experience, directly influencing key aspects of our core business. Whether you’re looking for a meal on Uber Eats or requesting a ride, search is what connects you with the right options—quickly, accurately, and at scale.
Uber Eats users are faced with a staggering choice: over one million restaurants globally, and typically more than a thousand dishes or restaurants per user session. Helping Uber Eats users navigate this vast space—based on preferences like cuisine, price, delivery time, dietary needs, or past behavior—is a deeply complex problem.
The importance of search extends to the Uber Rides experience as well. Riders rely on intelligent destination search, autocomplete suggestions, and personalized predictions—all of which must be fast, reliable, and context-aware. Even the process of matching riders to drivers is, at its core, a search problem. This matching must balance multiple real-time signals—driver availability, location, preferences, and compliance rules—while delivering results in seconds. These challenges illustrate how search and ranking are deeply embedded in Uber’s fulfillment logic, operating under strict latency and accuracy constraints, all while serving millions of people in dynamic, real-world conditions.
Given its central role, the Search Platform at Uber must meet high demands for performance, scalability, and data freshness. It’s not only a critical enabler of product innovation and business growth, but also a strategic area of investment—especially as the industry evolves rapidly in the era of AI. Building sustainable, forward-looking solutions in this space is key to staying ahead of both customer expectations and industry standards.
In this blog, we take you through the evolution of Uber’s Search platform—from its early days of rapidly scaling to meet the demands of hyper-growth, to building bespoke in-house solutions tailored to Uber’s unique business challenges, and finally to our current strategy: embracing open standards and collaborating with the broader tech community to build sustainable, future-ready systems.
Elasticsearch® in the Early Days (Before 2019)
Elasticsearch was released in 2010 and quickly gained traction across the industry as a powerful solution for both search and log analytics. Like many fast-growing tech companies, Uber adopted Elasticsearch early on. In the early days, the Search team’s primary focus was integrating Elasticsearch into Uber’s infrastructure and scaling operations to keep pace with the company’s explosive growth—often needing to double cluster capacity and fleet size every six months.
At that stage, the team functioned largely in an SRE (Site Reliability Engineering) capacity, dedicating most of its efforts to operational stability rather than deep exploration of Elasticsearch internals. As a result, Elasticsearch was often treated as a black box, optimized for availability rather than customization. For critical use cases, the team deployed dedicated Elasticsearch clusters and assigned engineers specifically to maintain and support them, ensuring reliability at scale.
Transition to Sia as In-House Solution (2019-2024)
As business demands grew, the Search team began encountering limitations with Elasticsearch. One notable constraint stems from Elasticsearch’s underlying engine, Apache Lucene Core™—the industry-standard library for building search systems. Lucene operates with near-real-time (NRT) semantics, meaning updates to the search index aren’t immediately searchable until a flush operation is performed. This latency poses challenges for use cases requiring real-time responsiveness.
A prime example is Uber’s fulfillment use case, where the system must match riders with nearby drivers as quickly as possible. Since drivers are constantly moving, the index must support high-throughput ingestion and true real-time query capabilities. To address this, the Search team extended Apache Lucene Core by introducing data structures that support concurrent reads and writes, enabling queries against actively updating indexes.
Building on this innovation, the team developed an in-house search engine called Sia, which eventually replaced Elasticsearch for key search workloads. As shown in Figure 2, Sia introduces a Live Index—a memory-resident layer that buffers new data and supports real-time querying. At regular intervals (like every 30 minutes), the Live Index flushes to create a Snapshot Index, which merges with previous snapshots. This snapshotting process is essential to free up memory, as the Live Index relies on memory-intensive data structures. The flushed Snapshot Index is immutable and stored in the standard Lucene segment format.
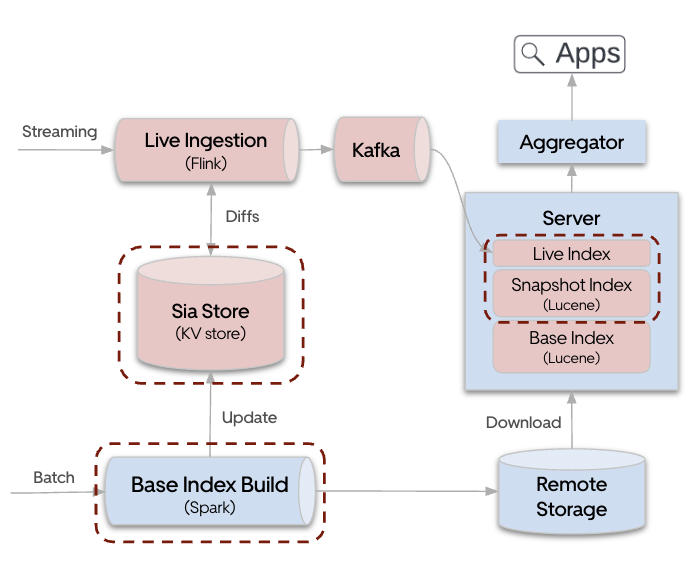
Over time, as snapshots accumulate, they are compacted via a Base Index build—a process that periodically (like weekly) reads from the source of truth and consolidates the data into a more compact Base Index. This layered index architecture reduces memory pressure and keeps the overall index manageable and performant.
This design draws inspiration from the search infrastructures of other large tech companies. In particular, Sia shares many architectural similarities with the LinkedIn® Galene search stack.
Sia also introduced several key innovations over the previous Elasticsearch-based solution at Uber, designed to meet the company’s evolving scale, reliability, and performance requirements:
- gRPC®/Protobuf for efficient RPC communication. Unlike Elasticsearch, which relies on REST APIs and JSON—a verbose and slower communication format—Sia adopted gRPC with Protobuf for all RPC interactions. This approach enables significantly more compact serialization and faster processing on both client and server sides. Moreover, since gRPC/Protobuf is the default communication protocol across Uber’s infrastructure, Sia’s native support ensured integration and consistency across systems.
- Apache Kafka®-based ingestion for improved resilience. Traditional Elasticsearch ingestion is push-based via REST APIs, which can lead to operational issues under high write traffic. If the server becomes overwhelmed, it may reject writes, requiring application owners to implement complex backpressure handling. In contrast, Sia used a pull-based ingestion model built on Kafka. This decouples producers from consumers, allowing Sia to ingest data at its own pace without backpressuring upstream systems, improving reliability and operational simplicity.
- Active-active deployment for high availability. Business continuity and resilience are top priorities at Uber. While Elasticsearch lacks native support for cross-cluster replication in active-active setups, Sia was designed to address this gap. Leveraging Uber’s active-active Kafka infrastructure, where regional Kafka topics are cross-replicated to global aggregation clusters, Sia can consume from these replicated topics to maintain a consistent global view across regions. This architecture ensures high availability, regional redundancy, and seamless failover support while trading off data consistency.
Project Sunrise to Redefine the Strategy
While Sia introduced significant improvements in reliability and scalability—enabling Uber to support rapid business growth—new challenges have surfaced as product requirements evolve. Over time, the limitations of maintaining a homegrown search system have become increasingly apparent.
One key challenge lies in the complexity of the BSL (Base/Snapshot/Live) index architecture. This structure, while necessary for enabling real-time search, creates friction when adopting new features from Lucene. For instance, when Lucene introduced vector search capabilities, we had to re-implement the HNSW algorithm to work within the BSL indexing model. Every new query operator added to Lucene requires a parallel implementation within our custom index structure—resulting in additional development overhead and slower adoption of new capabilities.
More importantly, we found that only a small subset of use cases truly require real-time freshness. The majority of applications can operate effectively with near-real-time (NRT) semantics. This insight led us to decouple NRT use cases from the BSL model and transition them to directly use Apache Lucene. Doing so significantly simplified platform operations by eliminating the need for periodic snapshotting and base index build workflows. NRT search in Lucene manages compaction internally, without requiring external orchestration or memory-intensive components.
A second major challenge is staying aligned with the rapid pace of innovation in the search and AI/ML ecosystem. In recent years, we’ve seen an explosion of advancements, including new vector search techniques like quantization-based indexing for compression, memory-efficient algorithms such as DiskANN, and growing adoption of GPU acceleration to drastically reduce indexing latency. Integrating and keeping up with these advancements in a custom-built system like Sia would demand considerable engineering effort and domain expertise—resources that are difficult to justify at scale.
Ultimately, we recognized that continuing to maintain and evolve an in-house search engine was no longer sustainable. To meet the increasing demands of our business and to stay competitive in a rapidly changing industry, we needed to rethink our long-term strategy for the Search platform.
To address these challenges, we launched Project Sunrise in 2024 —an initiative to redefine the strategy of Uber’s Search platform. Our core belief was that the most sustainable path forward is to innovate alongside the open-source ecosystem, leveraging the collective strength of the community while continuing to innovate for Uber’s unique needs.
Our goal was to adopt a technology that isn’t only battle-tested in the industry but also backed by a vibrant and active community of developers, contributors, and users. At the same time, we aimed to preserve the valuable features we had built to meet Uber’s unique requirements—and, where possible, contribute those innovations back to the open-source project. By doing so, we hope to give back to the community and help accelerate the evolution of the broader search ecosystem.
OpenSearch Adoption
We conducted a thorough evaluation of several leading technologies commonly used in the industry to solve large-scale search problems, including Elasticsearch, OpenSearch™, Apache Solr™, and others. Each of these platforms offers distinct advantages, but our analysis considered several key factors critical to our specific use case at Uber—such as scalability, flexibility, cost-efficiency, open-source governance, and community support.
After rigorous testing and comparison, we determined that OpenSearch best meets the complex and dynamic needs of Uber’s search problems. OpenSearch provides a robust, scalable, and extensible platform that aligns with our architectural goals. Its open-source nature under the Apache 2.0 license ensures long-term flexibility and avoids vendor lock-in, while also allowing us to tailor the platform to meet our specific requirements. In addition, the OpenSearch community is constantly growing, and that attracted us to adopt a solution that is actively maintained, benefits from diverse contributions, and evolves rapidly to meet the needs of modern search and AI workloads.
As a result, we proudly supported the launch of the OpenSearch Software Foundation (under the Linux Foundation) as a founding member—recognizing the importance of fostering a sustainable, open, and community-driven ecosystem around search technologies. By partnering with other premium members of the Foundation such as AWS® (Amazon Web Services) and SAP®, we aim to contribute to the governance, development, and long-term vision of OpenSearch. This collaboration reflects our commitment to open-source innovation and our belief in the power of community-led development to drive forward a scalable, reliable, and transparent search platform that benefits not only Uber, but the broader technology community as well.
LucenPlus Innovations
We want to contribute several key innovations we developed in Sia to OpenSearch—most notably, support for gRPC/Protobuf-based RPC communication and pull-based ingestion from streaming sources like Kafka. These features have been essential for achieving the scale, efficiency, and operational resilience required by Uber’s infrastructure.
Beyond these differences, we identified a shared limitation in both Sia and OpenSearch: neither offers an efficient query solution for a common class of use cases involving hierarchical (parent-child) relationships in the data. For example, on Uber Eats, the data model includes a large number of stores (restaurants), each containing a set of items (dishes). A typical search scenario involves retrieving items from stores within a specific geographic area—such as the Uber Eats user’s current location.
This type of query involves filtering both child entities (items) and their parent entities (stores) simultaneously, and can be described in a SQL snippet as shown below. For instance, Uber Eats users may want to find items whose names contain keywords like “milk”, from stores located within a given set of H3 spatial indices (Uber’s hexagonal hierarchical location system). Additionally, results are often grouped by store, with only the top-k items returned per store to ensure diversity and relevance in the final results.
However, Apache Lucene does not offer a join mechanism that meets our performance and scalability requirements for parent-child queries at Uber’s scale. Currently, Lucene supports two approaches:
- Index-time join (BlockJoin): Documents are indexed in contiguous blocks—children followed by their parent. While this enables efficient mapping during queries, any update to either parent or child requires reindexing the entire block, making it unsuitable for use cases with frequent updates.
- Query-time join: Parent and child documents are indexed independently, with children referencing parent IDs. The join is executed in two passes: first retrieving parent documents, then finding matching children. Although this allows independent updates, it often results in significant over-fetching and high query latency.
To overcome these limitations, we optimized the data layout by grouping items by their parent store and partitioning stores using their UUIDs. Within each store, items are stored contiguously and sorted by a static rank score (see Figure 3). This structure enables a custom, efficient join operator, which maintains iterators over all parent documents, the subset of eligible parents matching the query, and the corresponding child documents. The operator advances the parent iterator once enough children are collected or all associated child documents have been processed—ensuring efficient traversal without unnecessary scanning.
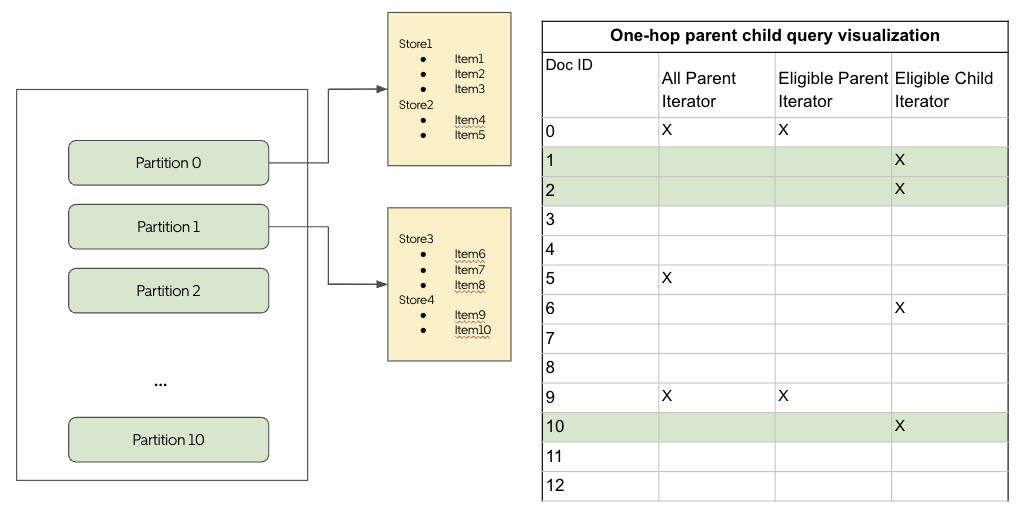
A major challenge in supporting parent-child queries efficiently is maintaining a sorted data layout during continuous ingestion, which involves frequent document inserts, updates, and deletions. Sorting the index is computationally expensive, and Lucene’s forced merge—used to consolidate segments—can significantly degrade query latency if done on the serving path.
To address this, we implemented a read/write separation architecture (see Figure 4). In this model, the ingester reads from Kafka and periodically commits the index. Each commit includes a forced merge that produces a single optimized segment, which is then uploaded to remote storage (like Apache HDFS™ or Google Cloud Storage™). The searcher retrieves the merged index from remote storage for serving, ensuring that all ingestion-related overhead is kept off the query path. This separation allows us to optimize data layout during ingestion without impacting the latency or stability of the search service.
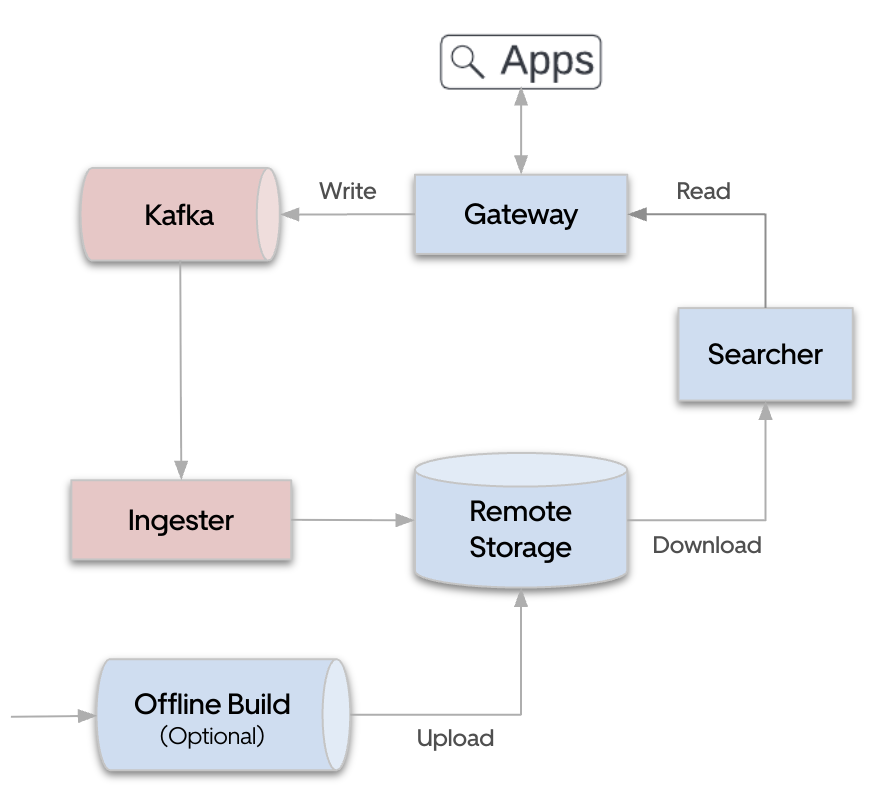
To align with open standards and ensure compatibility, we built a Search Gateway service that implements the OpenSearch APIs. As shown in Figure 4, data writes are published to Kafka, while query reads are fanned out to the backend Searcher nodes.
The primary goal of the Search Gateway is to abstract away internal implementation details from end users, providing a stable, OpenSearch-compatible interface. This design allows us to gradually consolidate our custom LucenePlus-based implementation into OpenSearch, enabling a smooth, low-friction migration path for clients without requiring changes on their end.
Community Contribution
With the innovations achieved in Sia and LucenePlus, we intend to use our experience in building large-scale search platforms to contribute to the evolution of OpenSearch. Building on these internal advancements, we contributed several critical features to OpenSearch 3.0, including pull-based ingestion—a more efficient and scalable method for retrieving data from upstream sources—and gRPC APIs, which offer a modern, high-performance alternative to traditional REST-based communication. These enhancements were designed to improve both the performance and flexibility of OpenSearch in high-throughput environments like ours.
In parallel, we recognized the need for a more resilient and elastically scalable version of OpenSearch. To address this, we are actively working on developing a cloud-native variant of OpenSearch. This extended architecture is designed to theoretically enable unbounded cluster scalability, allowing us to dynamically scale resources based on workload, without hitting traditional bottlenecks.
Moreover, in current OpenSearch architecture, cluster state coordination can become a reliability pain point, especially in large and dynamic clusters. Our cloud-native approach aims to mitigate these reliability issues by offloading coordination and state management to an external more powerful coordinator (more on this in another post)—paving the way for a more fault-tolerant, highly available search platform that can adapt to Uber’s growing data needs and evolving infrastructure.
Next Steps
Looking ahead, and in alignment with our broader Project Sunrise strategy—we are committed to deepening our engagement with the OpenSearch community and accelerating the development of advanced features that push the boundaries of scalability, resilience, and performance.
In addition, while we already benefit from the robust suite of machine learning tools integrated into OpenSearch, our AI-driven workloads are growing rapidly. One of our immediate priorities is to enable critical semantic search use cases, which are essential for delivering more accurate, contextual, and intelligent search experiences. We foresee significant innovation in this space as we build and contribute new styles of vector-based retrieval—to improve search quality while continuing to serve at lower cost.
As our infrastructure scales, we also see a strategic opportunity to unify search and observability under a single, cohesive platform. To that end, we’re actively exploring the adoption of OpenSearch for our observability stack.
By aligning these initiatives, we are intentional in future-proofing Uber’s long term search strategy. At the same time, we’re excited to continue innovating with a thriving open-source community.
Cover Photo Attribution: ”Lake Inle sunrise” by Blanksy is licensed under CC BY-NC-SA 2.0.
Amazon Web Services®, AWS®, and the Powered by AWS logo are trademarks of Amazon.com, Inc. or its affiliates.
Apache®, Apache Lucene Core™, Apache Spark™, Apache HDFS™, Flink®, Apache Kafka®, Apache Solr™, and the star logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Elasticsearch is a registered trademark of Elasticsearch BV.
Google Cloud Storage™ is a trademark of Google LLC and this blog post is not endorsed by or affiliated with Google in any way.
LinkedIn® is a registered trademark of LinkedIn Corporation and its affiliates in the United States and/or other countries.
OpenSearch™ is a trademark of LF Projects, LLC.
SAP is a registered trademark of SAP SE or its affiliates in Germany and in other countries.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.
Mingmin Chen
Mingmin Chen is the Director of Engineering on Uber’s Storage, Search, and Data (SSD) team, leading Search and Real-Time Data Platforms.
Shubham Gupta
Shubham Gupta is Senior Engineering Manager on Uber’s Storage, Search, and Data (SSD) team, leading the Search Platform team. Shubham is a member of the OpenSearch Software Foundation Technical Steering Committee (TSC).
Yupeng Fu
Yupeng Fu is a Principal Software Engineer on Uber’s SSD (Storage, Search, and Data) team, building scalable, reliable, and performant online data platforms. Yupeng is a maintainer of the OpenSearch project and a member of the OpenSearch Software Foundation TSC (Technical Steering Committee).
Shanshan Song
Shanshan Song is a Senior Director of Engineering at Uber, where she leads the Storage, Search, and Data (SSD) organization. She also serves as a member of the Opensearch Software Foundation Governing Board.