Introduction
ML (machine learning) sits at the heart of how Uber operates at scale. This is made possible by Michelangelo, Uber’s centralized ML platform, which has supported the full ML life cycle since 2016. Today, it runs over 400 active use cases, executes over 20,000 training jobs each month, and serves more than 15 million real-time predictions per second at peak.
However, as ML adoption has grown, so have the risks. Unlike traditional code, models are probabilistic and tightly coupled to data—making them harder to validate through static tests alone. A model may perform well offline but fail under real-world conditions due to data drift or integration edge cases. At Uber scale, even small regressions can cause widespread impact within minutes.
In the first half of 2025, we rolled out a series of safety mechanisms aimed at catching issues earlier, validating models more reliably, and mitigating production risk without slowing delivery velocity. This blog explains the thinking behind these mechanisms, how they’re integrated into the ML life cycle (see Figure 1), and how they’re helping Uber raise the bar on model safety at scale.
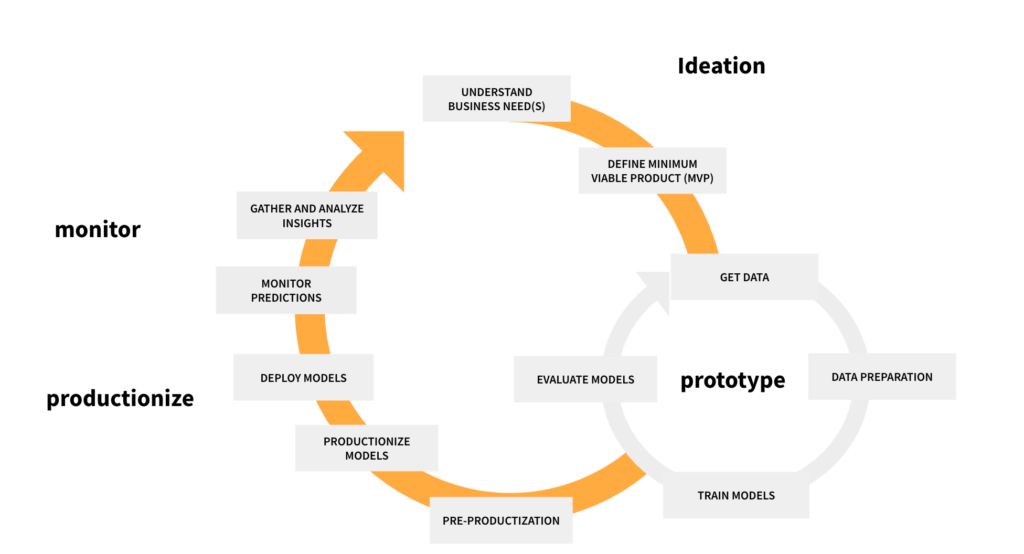
ML Model Safe Deployment Practices
Every model at Uber materializes from two artifacts: data and code. Both are essential—and both are vulnerable to silent failures that may degrade performance or destabilize dependent systems. To design our safe deployment strategy, we started by compiling best practices from MLOps and ModelOps for deploying machine learning models safely. Drawing on industry research and input from ML experts across Uber, we identified a set of safeguards that span the entire ML life cycle. Our safe deployment strategy centers on continuously measuring the health of these artifacts throughout the ML life cycle and using those measurements to drive automated, actionable safeguards such as alerts, rollout gates, and instant rollbacks.
The first line of defense lies in data and feature engineering, where many production failures originate. We enforce explicit handling of missing values, requiring that nulls be represented consistently rather than hidden behind placeholder constants. Feature imputation logic must be identical between training and serving to prevent subtle drift. Michelangelo’s ingestion pipelines automatically validate schemas—detecting type mismatches, distribution shifts, or cardinality changes before they propagate downstream.
During model training, we balance robustness with operational efficiency. For numeric features, we compute and record offline distributional statistics (e.g., percentiles, averages, and null rates) to characterize input scale and data quality and to provide baselines for later use. Model architectures are evaluated against strict latency budgets to protect serving infrastructure. Every training run produces a standardized model report consolidating these data‑quality metrics, feature‑importance rankings, and offline performance statistics. This artifact forms the basis for deployment‑readiness reviews, ensuring all stakeholders operate from the same source of truth.
Pre-production validation is mandatory. Backtesting against historical production data highlights regressions that may be invisible in aggregate metrics. For online models, shadow testing offers a closer approximation of real-world performance: the candidate model runs in parallel with production, processes identical live inputs, and logs outputs for real-time comparison—without affecting user-facing predictions. Today, shadow testing is part of over 75% of critical online use cases at Uber (with plans to move to 100% in 2025 H2) and has become a default safeguard in retraining pipelines.
Models that pass validation enter a controlled rollout. Deployments start with a small traffic slice, with system health and prediction quality continuously monitored. If error rates, latency, or CPU/GPU utilization breach thresholds, auto-rollback reverts to the last known good version. Rollouts are paired with predefined fallback plans to ensure operational continuity.
Once live, models are monitored continuously by Hue, Michelangelo’s observability stack. Hue tracks both operational metrics—availability, latency, throughput—and prediction-level indicators such as score distributions, calibration, and entropy. Feature health checks run in real time, tracking null rates, detecting drift via statistical tests, and verifying online-offline feature parity. Alerts can be triggered automatically, and in high-risk cases, model promotions can be blocked entirely until issues are resolved.
By embedding these protections into the platform, we’ve built an end-to-end safety net—from early feature preparation to ongoing production monitoring—that increases predictability, reduces the risk of issues, and improves confidence across engineering, data science, and platform operations.
How We Make Every Critical Model Safe
Uber’s ML ecosystem is vast and fast‑moving. Thousands of models run in production, with many being retrained daily or weekly. The core challenge is maintaining a consistent safety baseline for critical models without slowing down the teams. Our solution is a hybrid safety framework:
- Centralized, platform-enforced safeguards that apply by default to all deployments, ensuring baseline protection without additional work from model owners.
- Decentralized, team-owned best practices supported by tooling and frameworks, allowing deep, domain-specific validation where it matters most.
Built for Adoption
Safety only works when it’s easy to adopt. We embed mechanisms directly into Michelangelo workflows, minimize setup, and abstract operational complexity.
Shadow deployments are a cornerstone. They validate new models with live production traffic while keeping user behavior unchanged. We support two modes:
- Endpoint shadowing. Offers maximum flexibility. Teams can configure traffic split, define custom validation logic, and track bespoke metrics. This is ideal for use cases with complex business rules, though it requires more setup effort.
- Deployment shadow. Fully automated and runs by default for supported use cases. It currently focuses on prediction drift detection, with more advanced validation logic on the roadmap.
However, not every use case fits neatly into these two options. Some teams run their own experiments to validate the impact on business metrics like conversion rate. We treat these self-managed experiments as valid external shadow deployments, and the safety scoring system gives teams full credit for them.
Data Quality at Scale with Hue
Many severe incidents begin with upstream data changes—unexpected nulls, distribution shifts, or schema drift. Hue separates data profiling from monitoring so teams can compare live feature distributions against training, evaluation, or historical production baselines. It supports slicing by region, caller, or custom dimensions for precise debugging, and it operates at Uber scale via a streamlined Apache Flink® job deployed through Flink‑as‑a‑Service and backed by Pinot. With Hue, we detect prediction drift, verify online-offline parity, and surface anomalies within minutes, which tightens CI/CD gates and shortens time to mitigation.
Continuous Validation
We provide turnkey pipelines for ongoing performance checks, backtesting, and feature‑consistency validation. These integrate with Michelangelo so teams can evaluate against historical and real‑time data without a heavy lift. The impact is clear: regressions that once lingered for days now surface within hours. By default, every deployment benefits from automated data‑quality checks, system‑level monitoring with alerting, and a gradual rollout with rollback protection. Teams can layer unit tests, deeper offline evaluation, advanced shadowing, and richer performance monitoring when a higher bar is needed.
Model Safety Deployment Scoring System
Adoption improves when teams can see where they stand. We created a transparent scoring system to measure deployment readiness. It complements the MES (Model Excellence Scores), which tracks data‑plane quality such as accuracy and drift. The safety score focuses on the control plane—whether the right guardrails are in place.
We track four indicators:
- Offline evaluation coverage: the share of production models evaluated in the last 30 days.
- Shadow‑deployment coverage: the fraction of production deployments validated with live shadow traffic.
- Unit‑test coverage: in the ML monorepo, both overall and for new lines.
- Performance‑monitoring coverage: the percentage of production models with active monitoring pipelines and alerts.
These roll up into a single score that makes a model family’s readiness easy to compare and improve. Figure 2 details the CI/CD integration and monitoring architecture behind the score.
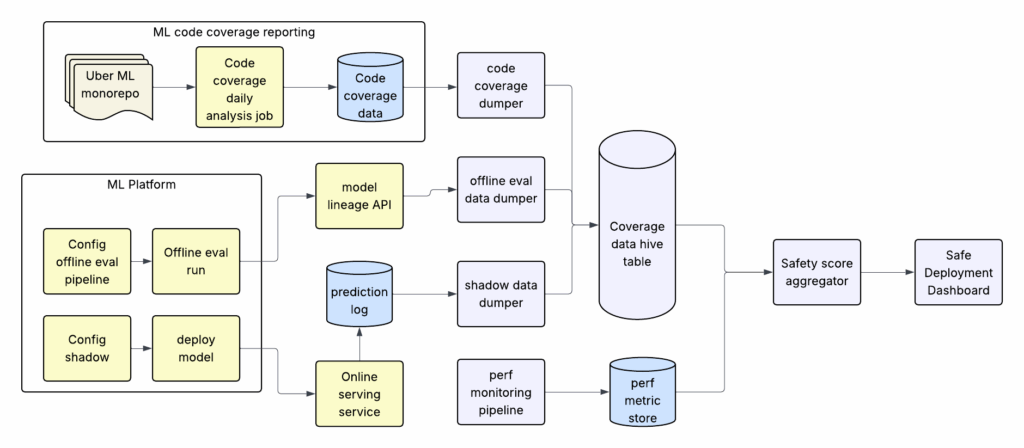
Foundational Safety—Always On
Some safeguards are too critical to leave to chance, so the platform runs them for every model by default. Real-time data quality checks continuously scan prediction logs for anomalies and drift. System monitors track availability, latency, and resource usage, triggering alerts when metrics move outside expected ranges. New model versions are rolled out gradually, with automatic rollback if failure signals appear—limiting the potential impact of an issue.
Driving Safety Adoption
Defaults establish a strong baseline, but higher assurance requires active engagement. We run company‑level programs that pair customer interviews and hands‑on engineering support with dedicated technical program management. Michelangelo engineers meet teams where they are, help write tests, set up evaluation pipelines, and wire monitoring into production.
By mid‑2025, we had onboarded over 75% of critical models to at least the Intermediate level, reflecting a broader cultural shift toward proactive model safety.
What’s Next
So far, our safe deployment work has mostly concentrated on the data side of model artifacts—tracking feature drift, null rate spikes, and online-offline inconsistencies. These systems have been effective at catching early signs of degradation, triggering targeted mitigation, and preventing small problems from becoming large-scale incidents.
The next step is to bring the same rigor to the code side of model development. Generative AI gives us new tools to do that. We see two immediate opportunities:
- GenAI-powered code generation. This can automate the creation of customized pipelines for model monitoring, backtesting, and feature consistency checks. This lowers the implementation cost for teams and helps standardize safety-critical logic across projects.
- GenAI-assisted code review. This can examine training and data processing code before deployment, surfacing potential bugs or anti-patterns—such as mismatched feature transformations between training and serving or unguarded data access that could introduce drift. See the uReview blog.
We’re also extending safety practices to GenAI applications and agents, which behave differently from static models. These systems may make multi-step decisions, invoke external APIs, or generate user-facing content in real time. Monitoring them requires not only operational metrics—latency, throughput, error rates—but also behavioral signals such as policy compliance, output relevance, and hallucination rates. By combining evaluation datasets, user feedback loops, and automated scoring pipelines, we can detect and mitigate unsafe behaviors before they reach users.
At the same time, we’re seeing a shift toward embedding-based models and significant growth in model size, which changes the nature of the safety problem.
- New kinds of drift. In embedding-heavy systems, statistical drift detection is no longer enough. We’ll need tools to detect semantic drift—changes in the conceptual meaning of inputs over time.
- Managing scale and complexity. Multi-gigabyte models bring heavier memory demands and longer inference times. Next-generation safety systems will need smarter resource management, sharding strategies, and rollback mechanisms tuned for large models.
- Safety beyond performance. For these models, the most critical risks aren’t always AUC drops or latency spikes—they can be hallucinations, factual inaccuracies, or unintended bias. Our safety framework will expand to include truthfulness checks, bias detection, and explainability requirements to ensure that more powerful models remain reliable and responsible.
Conclusion
The goal isn’t just to keep pace with the current generation of models, but to anticipate what’s coming next. As Uber moves deeper into AI-driven decision-making, our safety platform must be resilient to today’s risks and adaptable to the complex challenges of tomorrow—making every deployment not just fast, but safe by default.
Acknowledgments
We couldn’t have accomplished the technical work outlined in this article without the help of our team of engineers and applied scientists at Uber. We’d also like to extend our gratitude to the Technical Program Manager Melda Salhab for her pivotal role in promoting adoption across different organizations at Uber.
Apache®, Apache Flink™, Apache Pinot™, and the star logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.

Sophie Wang
Sophie Wang is a Senior Software Engineer on Uber’s Michelangelo ML Analytics team, working on model deployment safety.

Jia Li
Jia Li is a Staff Engineer on the Michelangelo team. He has focused on ML monitoring work for the last few years.

Joseph Wang
Joseph Wang serves as a Principal Software Engineer on the AI Platform team at Uber, based in San Francisco. His notable achievements encompass designing the Feature Store, expanding the real-time model inference service, developing a model quality platform, and improving the performance of key models, along with establishing an evaluation framework. Presently, Wang is focusing his expertise on advancing the domain of generative AI.
Posted by Sophie Wang, Jia Li, Joseph Wang