Open-Sourcing Starlark Worker: Define Cadence Workflows with Starlark
11 September 2025 / Global
Introduction
At Uber, we strive to build platforms that enable our engineering teams to move faster while maintaining reliability at scale. We’re excited to announce the open-source release of Starlark Worker, a powerful integration between Cadence workflow orchestration and the Starlark™ scripting language that simplifies how teams define and run workflows.
Challenges
Workflow orchestration platforms typically fall into two categories in terms of workflow definition languages: those that use declarative configuration languages, such as JSON or YAML-based DSLs (Domain-Specific Languages), and those that allow users to express workflow logic in general-purpose programming languages, like Go or Java®. Both categories have their pros and cons.
The fundamental problem with DSL-based workflows is that they impose artificial constraints on developers, making them unsuitable for expressing sophisticated control flows or handling dynamic scenarios that require computational flexibility. As workflow complexity increases, DSL definitions become large, deeply nested JSON blobs, which are difficult to read and maintain.
General-purpose programming language-based workflows (like Cadence) are very powerful, but at the same time, can be overkill for use cases that don’t require such advanced capabilities. The workflow code must be replayable, which means that workflow authors need to write and update it carefully, following best practices. Each update requires a new deployment of workers where workflows are executed. The deployment requirement creates friction, especially in multi-tenant platforms, where different teams often need to write, update, and run workflows that are executed by a shared worker fleet. This approach would result in constant redeployment cycles for workers, leading to increased operational overhead.
This blog explains a novel approach, Starlark Worker, that addresses these challenges by combining the expressiveness of a scripting language with the deployment simplicity of configuration-driven systems.
Architecture
Starlark Worker is built on top of Cadence—Uber’s battle-tested workflow orchestration platform that handles over 12 billion executions per month. Starlark Worker is essentially a Cadence worker that implements a DSL (Domain-Specific Language) use case, as described here. However, instead of using a DSL, it uses Starlark scripting language, which enables developers to write workflow logic using an intuitive, Python®-like syntax.

By leveraging Starlark’s embedded nature and Cadence’s robust orchestration capabilities, Starlark Worker delivers a workflow service that provides three key advantages:
- Expressive workflow language: Starlark’s syntax enables developers to express complex control flows, conditional logic, and data transformations using familiar programming constructs, such as loops, functions, and variables.
- Serverless experience: New workflows can be defined and submitted for execution immediately without any server (worker) redeployment. This is a crucial capability for multi-tenant platforms serving diverse use cases.
- Scalability and reliability: Since Starlark Worker executes workflows through Cadence’s proven infrastructure, it inherits all of Cadence’s battle-tested capabilities, including fault tolerance, automatic retries, state persistence, and horizontal scalability.
Execution Flow
Starlark Worker architecture elegantly integrates three key components: the Cadence workflow engine, Google’s® Starlark interpreter for Go, and a suite of domain-specific function extensions. The overall architecture follows this flow:
- Define: The developer writes their workflow logic in Starlark language. For example, defining a function def my_workflow(p1, p2): … in a .star file.
- Submit: The .star files are compressed and submitted to Cadence as a workflow input. Cadence distributes the workflow to one of the available workers.
- Execute: The Starlark Worker starts executing the workflow, unpacks the tarball, and passes the unpacked Starlark code to the embedded open-source Starlark interpreter written in Go.
- Interpret: The Starlark interpreter has been extended with domain-specific functions that enable seamless integration with Cadence primitives and external services.

Why Starlark?
Starlark offers several compelling advantages for workflow definition:
- Deterministic by design: Starlark’s hermetic execution model aligns perfectly with Cadence’s requirement for deterministic workflow code. Unlike traditional programming languages, where developers must carefully avoid non-deterministic operations, Starlark’s design prevents these issues by construction.
- Familiar syntax: With Python-like syntax, Starlark is immediately accessible to most engineers and data scientists. This reduces the learning curve compared to DSLs while providing significantly more expressiveness.
- Safe execution: Starlark’s sandboxed execution environment ensures that workflow code cannot access external systems or perform unexpected side effects, making it safe to execute untrusted code in multi-tenant environments.
Extensible Functions
While Starlark provides core language features and functions, Starlark Worker extends the interpreter with domain-specific functions that integrate seamlessly with Cadence’s capabilities. Some notable examples of such functions include:
- Sleep function: The sleep(seconds) function enables workflows to pause execution for specified durations. Internally, this delegates to Cadence’s SDK Sleep function, ensuring proper workflow state management.
- UUID generation: The uuid() function generates random UUIDs within workflow code by leveraging Cadence’s SideEffect API, properly handling non-deterministic operations without exposing this complexity to workflow authors.
- HTTP integration: The http.do(request) function enables workflows to make HTTP calls by executing them as Cadence activities, providing reliable, retryable external service integration.
These extensions demonstrate how Starlark Worker abstracts away Cadence’s complexity while maintaining its reliability guarantees. Workflow authors don’t need to understand concepts like SideEffect or the distinction between workflow and activity code—the platform handles these concerns automatically.
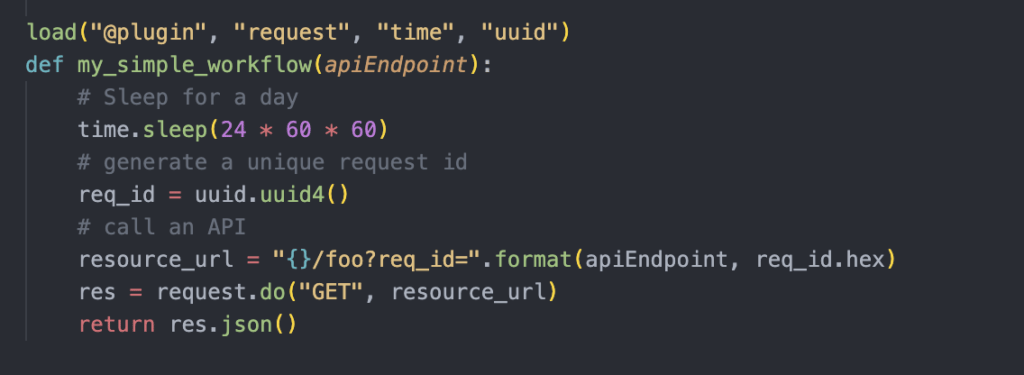
Figure 3 shows an example workflow written in Starlark. This workflow will sleep for a day, generate a UUID, and call an API. It uses some of the built-in plugins, including request, time, and UUID. Custom plugins can be easily introduced by implementing corresponding adapter interfaces in Go, similar to the built-in ones. Plugins internally leverage the Cadence SDK to make those operations durable and fault-tolerant. The worker executing it may die at any point, but the workflow will proceed and be completed by any other available worker.
Multitenant and Serverless
Starlark workers are easy to offer as a shared multi-tenant solution within the company because users don’t need to manage any servers. Users define their workflows in Starlark scripts, test them locally, and submit them to a centrally managed fleet of Starlark Workers. This approach eliminates the need for individual teams to maintain their own worker services while achieving resource efficiency through multi-tenant resource pooling.
The platform team managing the fleet of Starlark workers deals with capacity management, upgrades, and scalability of workers, leveraging Cadence’s auto-scaling capabilities to optimize compute resource utilization across all tenants. Workflow authors don’t have to be aware of these details. They can focus on their business needs and enjoy the serverless model, which is a game changer for developer velocity and is typically more reliable and resource efficient.
Use Case at Uber
Starlark Worker has found its application within Michelangelo, Uber’s machine learning platform that democratizes AI/ML capabilities across the organization. In this environment, various Uber teams define custom MLOps workflows tailored to their specific requirements. One example of such a workflow is an end-to-end model re-training workflow that performs the following steps:
- Trigger a Ray® job that re-trains a model on fresh data
- Deploy the newly trained model for online predictions in a shadow mode.
- Wait for a couple of days to allow the shadow model deployment to collect sufficient prediction data for evaluating the model’s performance.
- Trigger a job to build a model’s performance report for both production and shadow deployments.
- Ask the owning team to decide whether to promote the shadow model in production or not.
- Deploy (or not) the model on production based on the user’s decision (Human-In-The-Loop)
The Starlark code in figure 4 shows how these steps can be expressed. The code has been simplified to clearly demonstrate the core concepts and capabilities:

Michelangelo stores user-defined workflows in .star files in object storage. When execution is needed, Michelangelo starts a Starlark Cadence workflow execution, providing .star files as input. This approach empowers ML and data engineers to define and run their workflows independently of Cadence worker redeployment, facilitating swift iteration on workflows while upholding Cadence’s reliability standards.
Conclusion
This blog discussed how we combined Cadence’s proven orchestration capabilities with Starlark’s expressive yet safe execution model to enable rapid workflow development without sacrificing the robustness required for production systems.
The Starlark Worker is now available on GitHub. The repository includes example workflows and setup instructions to help you get started quickly. We encourage you to explore the project, provide feedback, and contribute to its continued development.
We’re excited to see how the broader community adopts and extends Starlark Worker. The project welcomes contributions across multiple areas, from expanding the domain-specific function library to improving development tooling. Whether you’re building an ML/AI platform or other workflow-intensive applications, Starlark Worker offers a compelling approach to workflow orchestration.
Cover Photo Attribution: The Great Mouse Detective by Jeremy Bronson is licensed under CC BY 2.0.
Google® is a trademark of Google LLC and this blog post is not endorsed by or affiliated with Google in any way.
Java is a registered trademark of Oracle® and/or its affiliates.
Python® and the Python logos are trademarks or registered trademarks of the Python Software Foundation.
Ray® is a registered trademark of Anyscale, Inc.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.

Andrii Kalishuk
Andrii Kalishuk is a Senior Software Engineer on Uber’s Michelangelo team, where he’s responsible for developing MLOps capabilities and AI infrastructure. He’s a generalist backend engineer with a focus on distributed systems.

Taylan Isikdemir
Taylan Isikdemir is a Sr. Staff Software engineer on Uber’s Cadence team, based in Seattle, US. He focuses on Cadence’s core orchestration engine while exploring new frontiers in orchestration. He’s a generalist backend engineer with previous experience in Cloud Infrastructure and Observability platforms.
Posted by Andrii Kalishuk, Taylan Isikdemir