Evolution and Scale of Uber’s Delivery Search Platform
24 November / Global
Introduction
Search is a primary discovery funnel for Uber Eats: a large share of orders start with people typing into the search bar to find stores, dishes, and grocery items. Strong search directly translates into higher conversion, better basket quality, and faster time-to-order—especially for long-tail queries, new or seasonal items, and multilingual markets. When search misses intent, people bounce or fall back to browsing. When it understands intent, they find what they want in seconds.
Traditional search stacks begin with lexical matching, which is fast and effective when queries exactly match document text. But real queries are challenging—synonyms (“soda” versus “soft drink”), typos (“mozzarela”), shorthand (“gf pizza”), language mix (“pan” meaning bread in Spanish, but a container for cooking in English), and context (“apple” the fruit vs the company). Lexical methods see strings, not meaning, and aren’t suitable for such queries, producing bad search results.
Semantic search shifts from matching words to matching meaning. It encodes queries and documents into vectors in the same space, so semantically similar things are close—even without keyword overlap. When properly used, it delivers a search experience that better captures someone’s intent across verticals (stores, dishes, items) and languages.
Establishing semantic search at scale for industry applications is more than training a model, but instead a whole tech stack including model deployment, ANN (Approximate Nearest Neighbor) index serving at scale, monitoring, version control, and so on. This blog walks you through how Uber Eats built this system, reviewing challenges in this process and the solutions we took.
Architecture
The general semantic search model architecture is shown in Figure 1. We adopted the classic two-tower structure so that the query and document embedding calculation can be decoupled. The query embeddings are calculated via an online service in real time, while the document embeddings are calculated in a batch manner via offline scheduled services. When training the model, we used the MRL (Matryoshka Representation Learning)-based infoNCE loss function so that a single model could output various embedding dimensions, and downstream tasks could choose the optimal embedding dimension according to their own size versus quality tradeoffs.
The latest LLMs (QWEN®) are used as the backbone embedding layer inside two towers to leverage its world knowledge and cross-lingual abilities. We further finetuned them using Uber Eats in house data to adapt the embedding space to our application scenarios. Currently, this single embedding model supports the content embedding task for all Uber Eats verticals and markets.
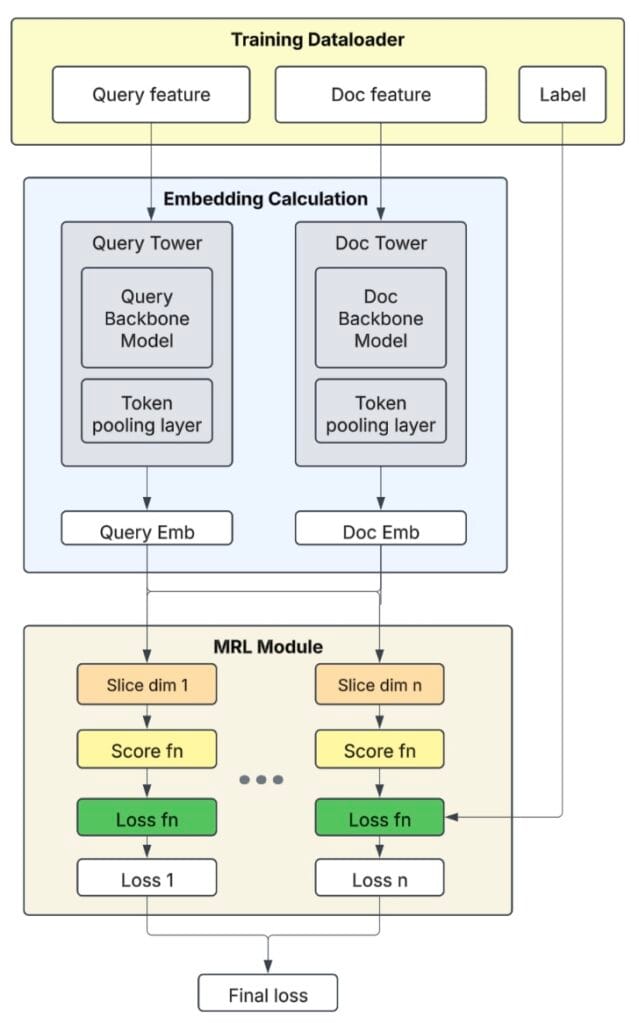
Model Training and Inference
Our model is a two-tower deep neural network built on a Qwen backbone. We use PyTorch™ with Hugging Face Transformers® for model development and Ray™ for distributed training orchestration. For large-scale training, we use PyTorch’s DDP (Distributed Data Parallel) together with DeepSpeed® (ZeRO-3), which shards the optimizer, gradients, and model parameters to handle the immense size of the Qwen model. This setup, combined with mixed-precision training and gradient accumulation, allows us to train on hundreds of millions of data points efficiently. Each successful training run generates versioned artifacts—a unique ID for the query and document models (query_model_id, doc_model_id), and a shared team-specific ID called two-tower-embedding-id (tte_id)—which are meticulously tracked for reproducibility and deployment.
Given the scale of our document corpus, offline inference is critical. To manage costs, we embed documents at the feature level (for example, store or item) and then join these embeddings back to the full catalog of billions of candidates before indexing. The resulting embeddings are stored in stable feature store tables, keyed by entity IDs, making them readily available for both retrieval and ranking models. These embeddings are used to build our search index, which are supported by HNSW graphs and store both non-quantized (float32) and quantized (int8) vector representations to optimize for various latency and storage budgets.
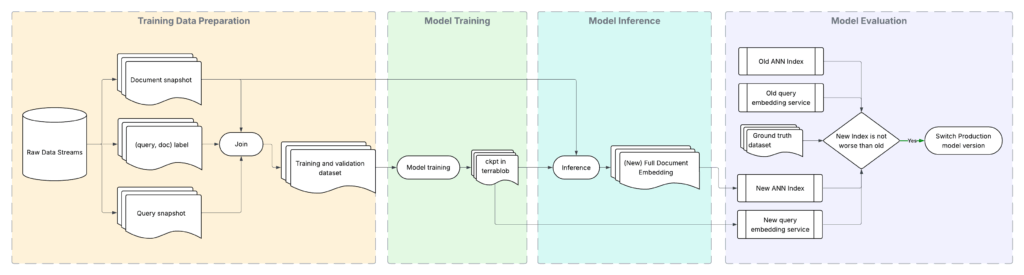
Development and Deployment Challenges
We tackled key challenges in scaling our semantic search system. For example, we had to balance retrieval accuracy with infrastructure and compute costs through careful tuning of ANN parameters, quantization, and embedding dimensions.
To achieve productionization and reliability, we had to ensure safe, automated, and rollback-capable index deployments with strong validation, versioning, and real-time consistency checks in production.
Quality and Cost
We use Apache Lucene® Plus as our primary indexing and retrieval system. To manage the scale and diverse nature of the data, we maintain separate indices for each vertical—OFD (restaurants) and GR (grocery/retail).
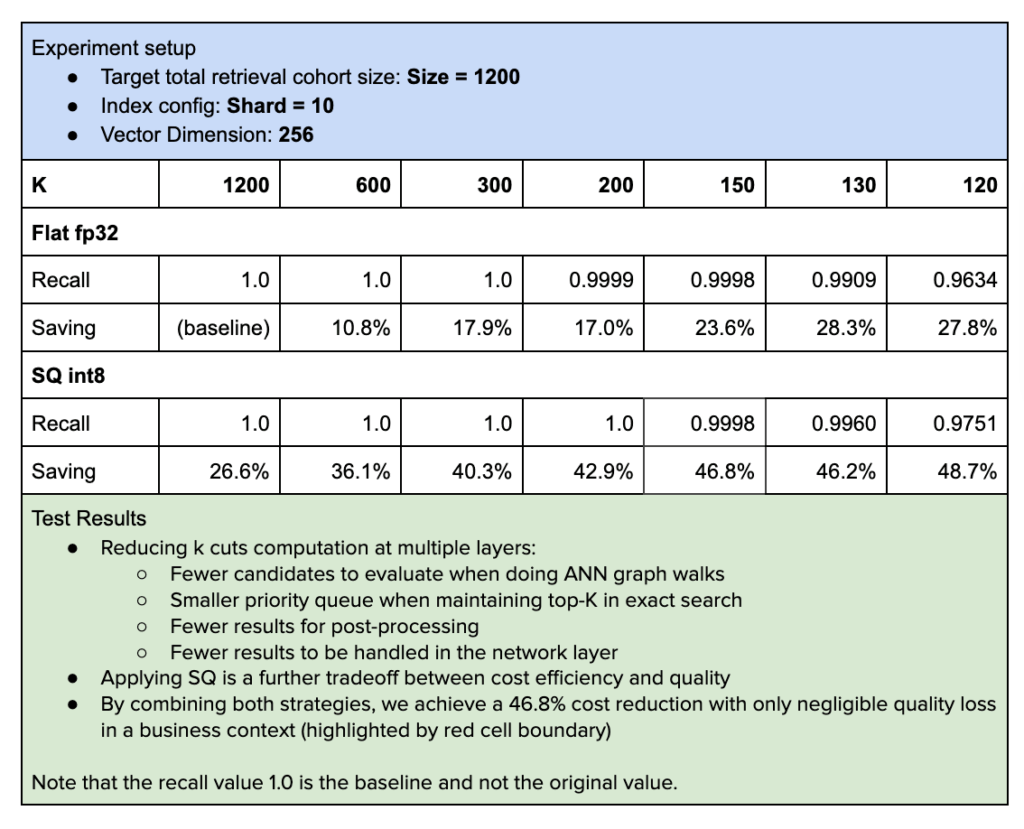
Storing and serving large-scale indexes can be expensive, in terms of infrastructure costs and query latency. To optimize this tradeoff while maintaining strong retrieval quality, we explored several mechanisms to balance cost, latency, and performance. In particular, we ran controlled experiments varying three key factors:
- Search parameter K: controls the number of nearest neighbors retrieved per shard in ANN search. By carefully choosing k per shard—guided by data distribution statistics—you can maintain the overall retrieval cohort size and preserve result quality.
- Quantization strategy: comparing non-quantized float32 embeddings against compact int7 SQ (scalar-quantized) representations.
- Embedding dimension: using different Matryoshka-cut representations generated via MRL (Matryoshka Representation Learning), such as emb_256 and emb_512.
Here’s how we designed search parameters and quantization:
We also used MRL (Matryoshka representation learning) to reduce the dimension of the embeddings to optimize the latency and storage costs further. MRL solves this by training a single model whose embeddings can be cut at different lengths. Shorter versions of the embedding capture coarse information quickly, while longer versions add finer details for higher accuracy. This gives us the flexibility to trade off speed versus quality at inference time, without retraining separate models.
In our application, we chose the following vector dimensions with equal weights: [128, 256, 512, 768, 1024, 1280, 1536]. In our offline evaluation results, we observed that the MRL provides strong performance in dimension reduction.
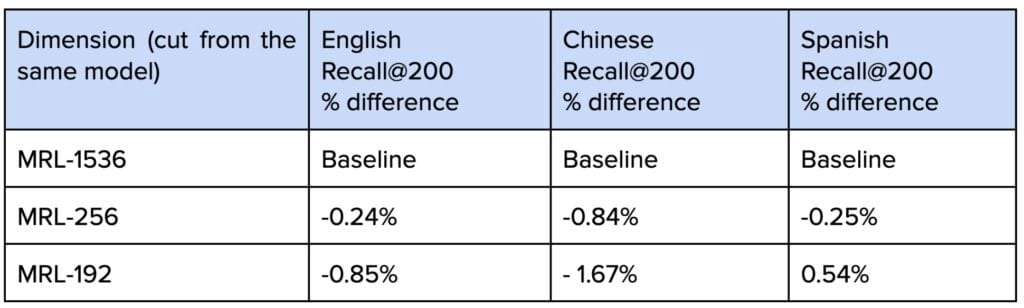
Lowering shard-level k from 1,200 to around 200 yielded a 34% latency reduction and 17% CPU savings in our experiments, with negligible impact on recall. On top of that, applying scalar quantization (int7) further cut compute costs, reducing latency by more than half compared to fp32 while maintaining recall above 0.95. MRL added another layer of efficiency by enabling us to serve smaller embedding cuts (256 dimensions) with almost no loss (< 0.3% for English and Spanish) in retrieval quality compared to full-size embeddings, while also reducing storage costs by nearly 50%. Together, these optimizations significantly lowered the cost and latency of serving large-scale indexes without any significant compromising in retrieval quality.
Beyond quantization and k tuning, our vector index is paired with locale-aware lexical fields and boolean pre-filters—including hexagon, city_id, doc_type, and fulfillment_types—that run before the ANN search. These pre-filters dramatically shrink the candidate set up front, ensuring low-latency retrieval even against a multi-billion document corpus. Once the ANN search identifies the top-k candidates per vertical, we optionally apply a lightweight micro-re-ranking step, using a compact neural network, to further refine results before handing them off to downstream rankers.
Productionization and Reliability
Uber data changes continuously. To keep results fresh, our Delivery semantic search runs a scheduled end-to-end workflow that updates the embedding model and serving index in lockstep on a biweekly cadence. Each run trains or fetches the target model, generates document embeddings, and builds a new Lucene Plus index without changing the live read path.
To enable seamless model refreshes without disrupting live traffic—and to provide rollback flexibility when issues arise—we adopted a blue/green pattern at the index column level. Each index maintains two fixed columns, embedding_blue and embedding_green, with the active model version mapped to one of them via a lightweight configuration. During each refresh, a new index snapshot is built containing both columns: the active column is preserved as-is, while the inactive column is repopulated with fresh embeddings. This design allows us to safely switch between old and new versions when needed.
During each refresh, we rebuild a full index snapshot that contains both columns (embedding_blue and embedding_green). Even though only the inactive column is intended to change, the build re-materializes the active column as well, so a bug or bad input could silently corrupt what’s currently serving. To protect production, we gate with automated validations that run before any deployment: they block the flow if inputs are incomplete, if the carried-forward (active) column diverges significantly from the current prod index, or if the newly refreshed column underperforms.
Concretely, our pipelines run three checks.
- Completeness: verify document counts (and key filtered subsets) in the index match the source tables used to compute embeddings—fail fast on drift or partial ingestion.
- Backward-compatibility: ensure the unchanged column is byte-for-byte equivalent between the pre-refresh and post-refresh index (for example, at T1 compare embedding_blue across old and new builds if embedding_blue is currently serving. Any mismatch ends the run.
- Correctness: deploy the newly built index to a non-prod environment, replay real queries at a controlled rate, and compare recall against the current production index. These checks catch issues like data corruption during indexing, bad distance settings, or upstream feature regressions, ensuring the new index is at least as good as production before we make a switch.
We also considered maintaining two separate blue and green indexes instead of two columns within a single index. While that approach would simplify reliability—since we wouldn’t need to touch the production index during a refresh—it’d significantly increase storage and maintenance costs. Given that trade-off, we built a mechanism that lets us safely operate with one index containing two columns.
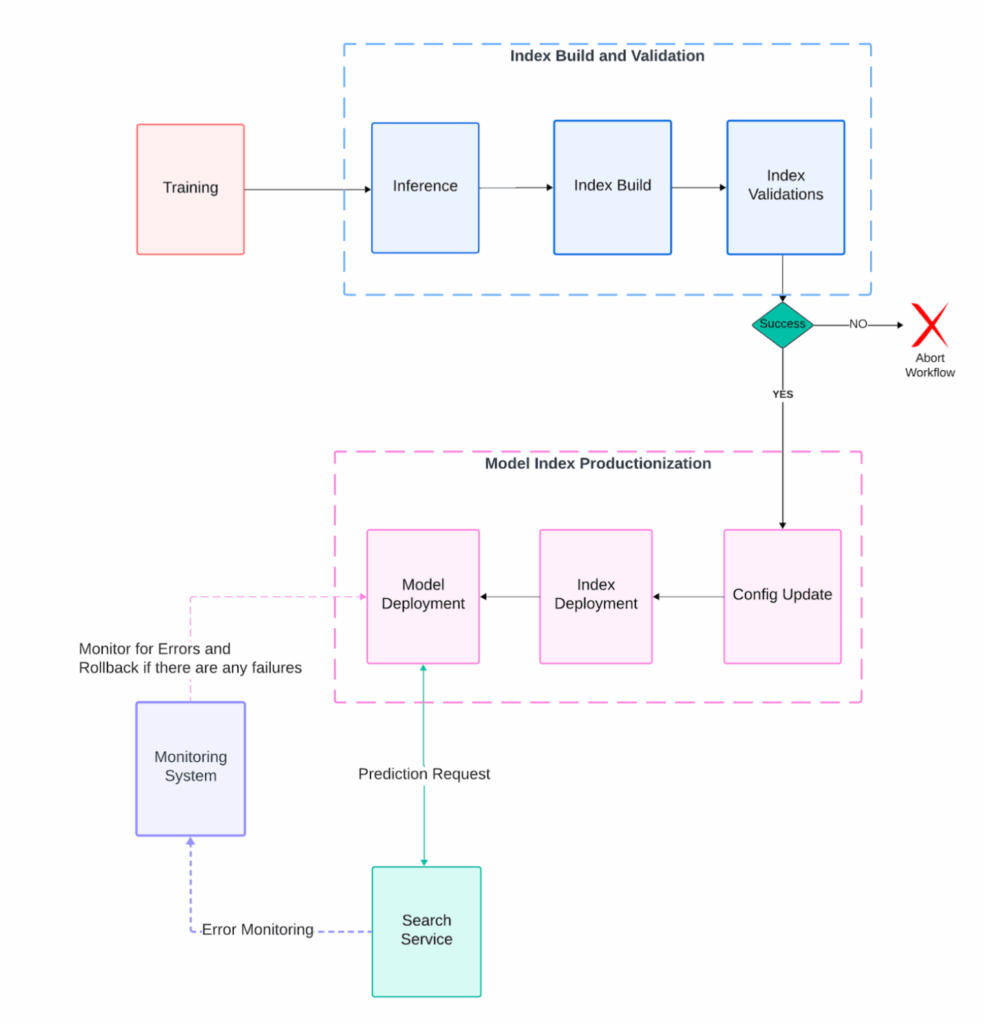
Even with strong build-time and deploy-time checks, there’s still a risk of human error or bugs. For example, a wrong model-to-column mapping or an index built against a different-than-expected model. To guard against this, we added serving-time reliability checks. Reliability of the production system was a significant challenge during the development process.
To make the system more reliable and prevent outages, we deploy the new index to production, then roll out the model gradually. The index stores the model ID in its metadata for both columns. On sampled requests, the service verifies that the model used to generate the query embedding matches the model ID recorded on the active index column. On any mismatch, we emit a compatibility-error metric and log full context. If errors remain non-zero over a short window, an alert fires and we automatically roll back the model deployment to the previous version (the index remains unchanged). This protects against version mix-ups and config mistakes without adding latency or extra hops to the read path.
Conclusion
We built a scalable, multilingual search system for Uber Eats that powers discovery across restaurants, grocery, and retail with speed and precision. Our approach brings together advanced language models and smart architecture choices—like Matryoshka embeddings and Lucene Plus integration—to balance quality, cost, and latency at a global scale.
What makes this system stand out is its production-first design: it automatically retrains, rebuilds, and refreshes search indexes every two weeks, ensuring that results stay fresh and reliable as data changes daily. With a robust blue/green deployment strategy, strong validation gates, and efficient index optimization, we can safely roll out new models without disrupting live traffic.
Overall, this platform demonstrates how thoughtful engineering—combining strong modeling, reliable infrastructure, and cost-aware optimization—can deliver a search experience that feels smarter, faster, and more intuitive for users around the world.
Apache®, Apache Lucene Core™, and the star logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Deepspeed® is a registered trademark of the Microsoft group of companies.
Hugging Face® is a registered trademark of Hugging Face, Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Qwen® is a registered trademark of Alibaba Cloud.
Ray is a trademark of Anyscale, Inc.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.

Divya Nagar
Divya Nagar is a Staff Software Engineer on the Feature Engine team at Uber, where she leads the development of the Vector Store, the data plane powering embedding use cases across both generative AI and CoreML applications.

Zheng Liu
Zheng Liu is a Staff Software Engineer on Uber Eats Search team, where he focuses on improving search experience using advanced deep learning and large language models. He’s a major contributor to Uber Eats semantic search and generative ranking models.

Jiasen Xu
Jiasen Xu is a Sr. Software Engineer on Uber’s Search Platform team, where he leads the adoption of vector search technologies across the company. His work focuses on advancing large-scale similarity search through expertise in ANN algorithms, indexing libraries, and vector database optimization.

Bo Ling
Bo Ling is a Sr. Staff Software Engineer on Uber’s AI Platform team. He works on NLP, large language models, and recommendation systems. He’s the lead engineer for embedding models and LLM on the team.

Haoyang Chen
Haoyang Chen is a Sr. Staff Software Engineer on Uber Eats Search team, where he leads efforts in semantic search and generative recommendation to enhance the search experience on Uber Eats.
Posted by Divya Nagar, Zheng Liu, Jiasen Xu, Bo Ling, Haoyang Chen