Enabling Deep Model Explainability with Integrated Gradients at Uber
October 23, 2025 / Global
Introduction
At Uber, machine learning powers everything from dynamic pricing and time of arrival predictions to fraud detection and customer support automation. Behind these systems is Uber’s ML platform team, Michelangelo, which builds Uber’s centralized platform for developing, deploying, and monitoring machine learning models at scale.
As deep learning adoption at Uber has grown, so too has the need for trust and transparency in our models. Deep models are incredibly powerful, but because they’re inherently black boxes, they’re hard to understand and debug. For engineers, scientists, operations specialists, and other stakeholders, this lack of interpretability can be a serious blocker. They may want to know: “Why did the model make this decision?” “What feature was most influential here?” “Can we trust the output for this edge case?”
In response to these needs, we at Michelangelo invested in building IG (Integrated Gradients) explainability directly into our platform, making it possible to compute high-fidelity, interpretable attributions for deep learning models at Uber scale.
This blog shares how we tackled the engineering and design challenges of implementing IG across multiple frameworks (TensorFlow™, PyTorch™), supporting complex pipelines, integrating with Michelangelo, and enabling broad adoption across teams. We’ll also highlight real-world motivations and use cases, and where we’re heading next on our explainability journey.
Background
Machine Learning Explanations
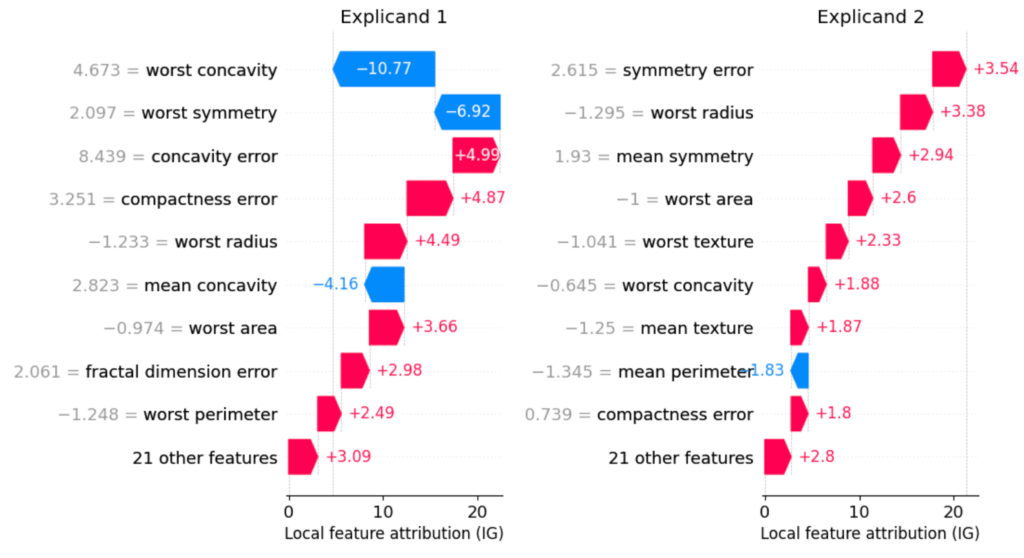
Explainability refers to techniques that help humans interpret machine learning model behavior. For deep learning models, this is especially important. Their high capacity and nonlinearity make them effective—but often opaque. One common explainability approach is feature attribution, which quantifies how much each input feature contributed to a model’s output.
At Uber, we rely heavily on local feature attributions as explanations for individual predictions (Figure 1). For example, if a model flags a trip as potentially fraudulent, a local attribution method can pinpoint whether the location, time, or payment method played the biggest role.
Integrated Gradients
We chose IG as our local feature attribution method because it offers a principled foundation for explainability, grounded in well-established theoretical properties. Specifically, IG satisfies key axioms like completeness and sensitivity, which ensure that feature attributions are faithful to the model’s internal logic. In addition, it naturally supports deep neural networks as it’s a gradient-based technique.
This strong theoretical foundation translates well into practical, scalable usage. IG is compatible with both TensorFlow and PyTorch, enabling smooth adoption across our diverse modeling ecosystem. It has a modest runtime overhead and supports large-scale, distributed computations, making it viable for large batch jobs. Importantly, it offers the flexibility needed for ad-hoc analyses, whether via automated attribution pipelines or during interactive debugging sessions.
In practice, IG also meets our usability and robustness requirements. The attributions it generates are interpretable and actionable, helping engineers understand and troubleshoot model behavior. Furthermore, we validated IG’s effectiveness through ablation studies, where we perturbed the top features it identified and measured the resulting performance drop. Across both regression and classification tasks, IG consistently produced feature rankings whose ablation caused the largest degradation in model performance compared to other methods like SHAP, LIME, and XGBoost feature importance. This confirms that IG isn’t only theoretically sound but also empirically effective at highlighting the features most critical to model predictions. In addition, it supports both local and global explanations, allowing us to surface insights for individual predictions while also tracking overarching patterns over time.
Together, these theoretical strengths and operational advantages make IG a compelling choice.
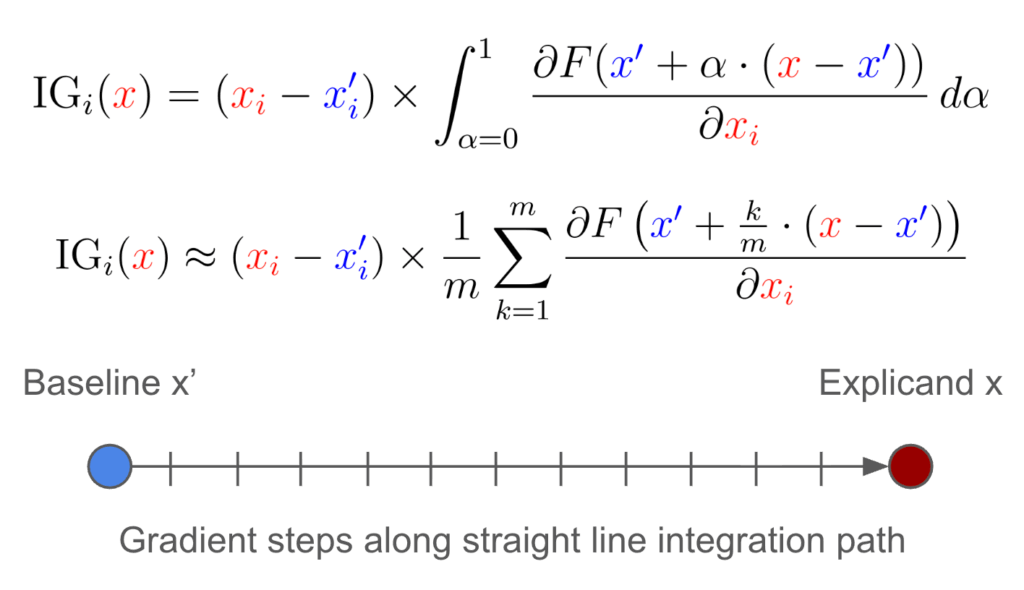
IG measures how the model’s prediction changes as the input transitions from a baseline (typically zero or a neutral value) to the actual input. It does this by integrating the model’s gradients along that path (Figure 2). IG measures how the model’s prediction changes as the input transitions from a baseline (typically zero or a neutral value) to the actual input. IG can be sensitive to the choice of baseline, and it’s important to choose it carefully.
Architecture
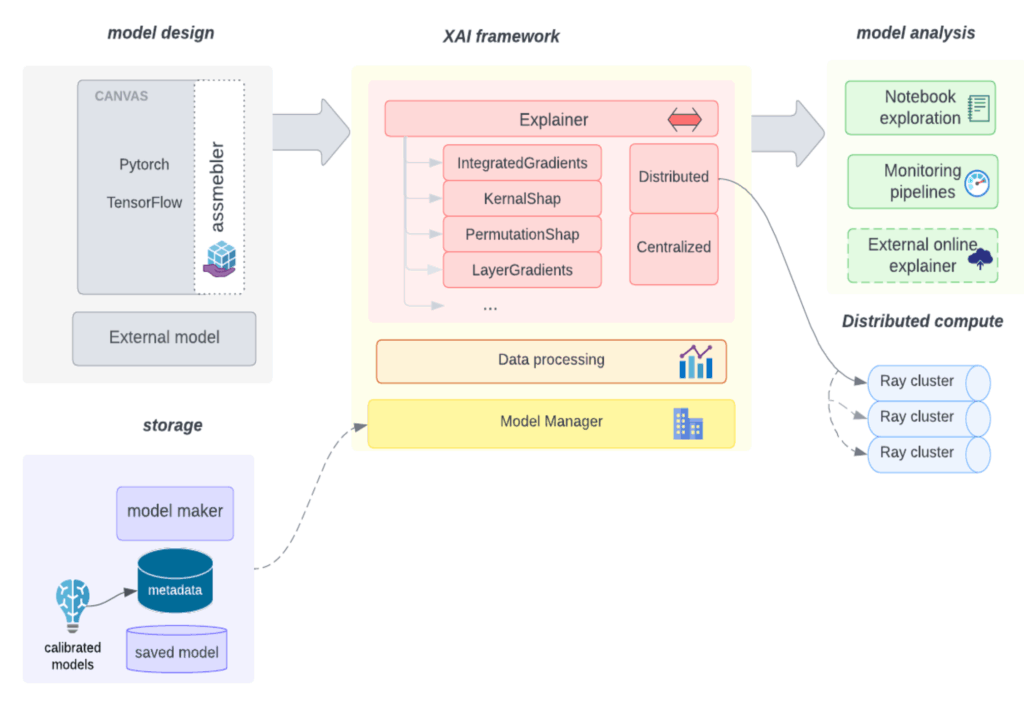
Uber’s ML platform, Michelangelo, supports the full life cycle of machine learning—enabling teams to build, deploy, and maintain models at scale. At its core are configurable pipelines that automate every stage, from data preparation and model training to evaluation, deployment, and monitoring.
These pipelines fall into two categories:
- ML application pipelines handle core tasks like training, validation, and prediction
- ML orchestration pipelines connect multiple applications, allowing teams to schedule retraining, monitor performance, and manage deployments in a version-controlled, repeatable way
Because explainability is important across every stage, we designed IG to work natively within these pipelines (Figure 3). Currently, we support offline, batch-mode explanations, where IG is run as part of model training, evaluation workflows, or ad hoc notebooks.
Explanation Use Cases
Explanations are made available to our stakeholders across a wide range of needs at Uber.
- Regulatory and ethical accountability: In areas like fraud detection, financial products, and safety, we must be able to explain individual model decisions to regulators, users, and internal stakeholders.
- Model development and debugging: Engineers use IG to investigate unexpected behavior, such as features that gain or lose importance over time.
- One team found that a feature irrelevant during training became dominant in production due to a distribution shift. IG surfaced the issue quickly, leading to a data pipeline fix.
- Feature validation and optimization: Product teams rely on IG to measure the real-world impact of new features, and to justify the cost of data collection and logging.
- For a large-scale model, IG showed that newly introduced behavioral signals were strongly influencing top-ranked results—validating their value and guiding future iterations.
- Operational monitoring: Analysts use IG to trace anomalies and explain outlier predictions in production systems, enabling faster incident response and better visibility into model behavior.
By integrating explainability into the core of Michelangelo, we give teams across Uber the tools to understand and trust their models—leading to faster iteration, safer decision-making, and more resilient ML systems.
Interactive Exploration with Notebooks
In addition to direct pipeline integration, we also support ad hoc interactive explainability runs via Jupyter® notebooks. These notebooks empower engineers, scientists, and operations teams to debug and understand individual model predictions after training has been completed. Unlike batch attribution in pipelines, notebook-based workflows offer the flexibility to:
- Investigate a single prediction or a small set of examples
- Run IG on-demand using prebuilt utilities
- Visualize attribution results in interpretable formats
This workflow is especially valuable for teams auditing specific decisions for regulatory compliance, understanding outcomes in city operations, or debugging escalated customer support tickets where model behavior impacted user experience.
This tight integration between pipelines and notebooks ensures that deep models at Uber can be explained not only at scale, but also at the human level, where every decision may need to be justified and understood in detail.
Challenges
Implementing integrated gradients across Uber’s ML platform required more than just plugging in a new method. It meant adapting our entire infrastructure to support end-to-end explainability for deep models. Below are some of the core technical challenges we faced and how we addressed them.
Saving and Loading Raw Models
Michelangelo typically packages models for inference using model formats which optimize for portability and consistency—but not for differentiability. Since integrated gradients require access to gradients, we updated our pipelines to also persist the raw TensorFlow and PyTorch models alongside any required metadata (for example, baseline configuration and input spec schemas). This enabled explainability tooling to load models directly into a differentiable context without disrupting existing production flows.
Model Wrapping for Explanation
To support consistent attribution computation, we developed a model wrapper abstraction that standardizes the process of converting inputs into compatible tensors and electing the specific model output to explain.
This abstraction allowed us to generalize IG computation across different model architectures, input formats, and use cases with less manual configuration from users.
Calibration Support
Uber’s model pipelines often include calibration layers trained on top of raw model outputs—for example, to map logits to probabilities. Since calibration can affect decision thresholds and model confidence, we extended IG to support explanations through calibrated models. Because many common calibration methods (for example, Platt scaling, temperature scaling) are differentiable, we can chain them into our IG pipeline with minimal overhead using the model wrapper.
Explaining Categorical Features
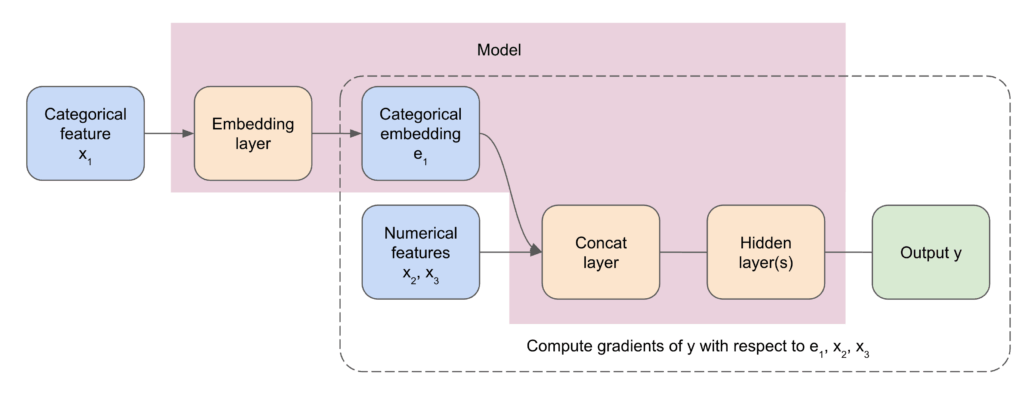
Categorical features pose a unique challenge for gradient-based attribution methods like integrated gradients because they aren’t inherently differentiable. A common workaround is to compute attributions with respect to the embedding vectors these features are mapped to (Figure 4), and then postprocess those scores to reflect the importance of the original categories.
Since embedding vectors are high-dimensional and sit deep within the model architecture, a major challenge was enabling IG to target intermediate layers for attribution—not just inputs. This capability, known as multi-layer explanations, became a key component of our system.
We also developed flexible postprocessing tools to reshape and aggregate embedding attributions into human-readable formats. Since embedding vectors are often high-dimensional, their raw IG scores are spread across many components. Our tools support aggregations that make the output easier to understand and act on. This level of interpretability was especially important because clarity and compactness were key to usability.
Multi-Layer Explanations
Supporting multi-layer explanations required non-trivial extensions to the underlying integrated gradients implementations. Specifically, we needed to:
- Run forward passes for both samples and baselines all the way to the target intermediary layers (for example, embeddings, feature transforms)
- Register gradient hooks at these layers to capture the necessary backward signal for attribution
We implemented this in both PyTorch and TensorFlow, ensuring consistency across frameworks. Doing so meant navigating framework-specific quirks in how intermediate outputs and gradients are handled.
From a usability standpoint, this feature is powerful but requires care: users must select the correct layer(s) to explain, which demands a deep understanding of their model architecture and how categorical inputs are embedded. To make this easier, we introduced a configuration that lets users specify the layer(s) of interest while abstracting away the gradient plumbing.
By combining this with postprocessing tools to aggregate high-dimensional embedding attributions into interpretable category-level scores, we made multi-layer attribution not only feasible but practical.
Data Resilience and Validation
We support generating explanations in both training and evaluation pipelines. However, evaluation often involves new or evolving data sources, which can introduce inconsistencies not seen during training. A common issue is category mismatch: categorical features may contain previously unseen values at evaluation time. Since embedding layers rely on fixed vocabularies, these unexpected categories can cause runtime errors or invalid attributions.
To address this, we implemented validation and filtering logic that ensures safe and reliable explanations under data drift. The system can either skip invalid inputs or map them to safe defaults, allowing explanations to remain robust, consistent, and interpretable—even as the underlying data evolves.
Design
Building explainability into Uber’s ML platform meant not just choosing the right algorithm, but designing a flexible, scalable, and user-friendly system around it. Below are the key components of our implementation, which make integrated gradients usable in both production and research workflows across a diverse set of models.
Flexible Explainer Framework
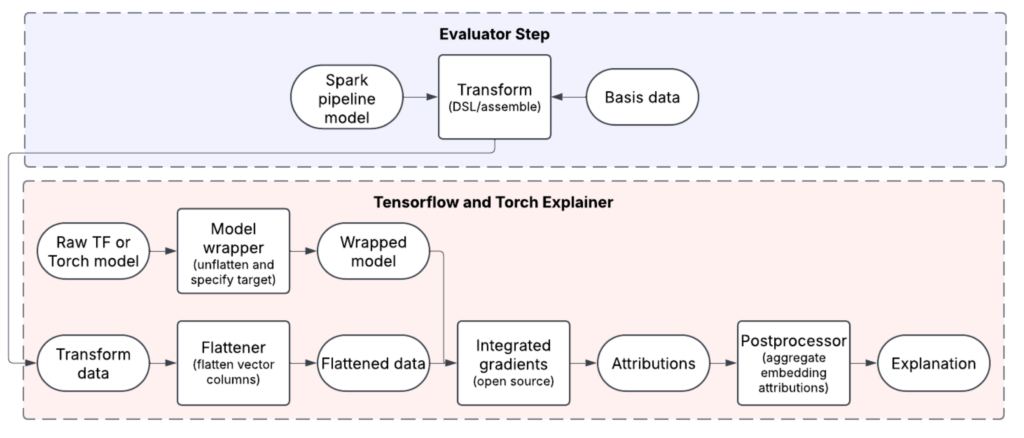
At the core of our solution is a flexible explainer framework (Figure 5) that abstracts away model- and framework-specific details, enabling consistent attribution across Uber’s diverse ML landscape. Supporting both TensorFlow and PyTorch was essential, as teams across the company rely on both frameworks for production and research.
To implement integrated gradients efficiently, we wrapped robust open-source libraries:
By building on these proven tools, we accelerated development, stayed aligned with community standards, and retained the flexibility to contribute improvements back upstream. Our wrapper layer standardizes key components like model loading, metadata parsing, and preprocessing—making IG usable across Michelangelo pipelines, notebooks, and custom workflows.
One of the key design choices was to make IG configuration code-driven and declarative. Teams enable and customize IG by editing YAML files that define their ML workflows. These YAML files specify details such as which layers to attribute, what baselines to use (we support zero, mean, median, and manually specified ones), and how the output should be logged or visualized. This seamlessly integrates IG into the same configuration system they already use to define training, evaluation, and deployment logic.
The framework is also designed to be extensible, allowing us to incorporate new attribution methods (for example, SHAP, DeepLIFT) with minimal additional engineering effort. By decoupling attribution logic from platform infrastructure, we’ve created a unified interface that scales across use cases and teams.
Integration with Michelangelo
We tightly integrated IG into Michelangelo, Uber’s ML platform, making explainability a first-class feature in the model life cycle.
IG is integrated into the evaluator step of our training and evaluation pipelines, which is typically used to compute metrics after training. This allows teams to generate attributions as part of their regular model workflow—simply by modifying YAML configuration files.
Explanations can be generated both during model training (for deeper insights into feature learning) and during evaluation (for offline batch attribution, regression testing, and drift detection).
Our users can also run IG interactively through Jupyter notebooks, using preconfigured utilities that load the model wrapper and run attribution. This is especially useful for debugging individual predictions or for conducting deeper ad hoc analyses.
Parallelizing IG with Ray
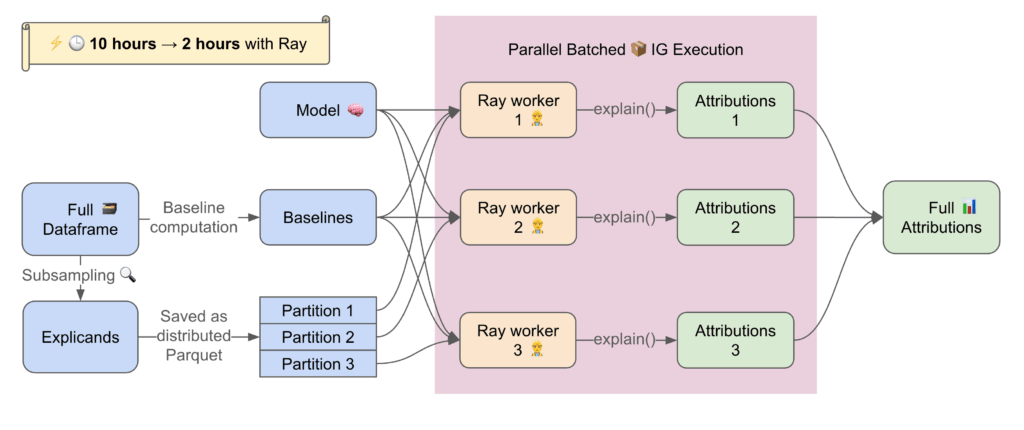
IG computation is inherently expensive. It requires multiple forward and backward passes per example across many integration steps. To make IG feasible at Uber scale, particularly for batch evaluation jobs and large deep learning models, we parallelized the computation using Ray (Figure 6).
Ray’s lightweight task-parallel execution model allowed us to distribute attribution workloads across CPU and GPU workers with minimal coordination overhead. This enabled us to cut total attribution time dramatically in large-scale pipelines—reducing runtime by over 80% in some cases.
Scalability wasn’t just a performance goal—it was critical for adoption. Many of our models operate on tight timelines and support key product experiences. Making explainability fast, and non-blocking ensured that teams could integrate IG into their existing workflows without compromising on iteration speed or user impact. By investing in speed from day one, we made explainability a practical tool, not just a theoretical one.
Conclusion
As deep learning becomes increasingly central to Uber’s ML systems, explainability is a priority. By developing a flexible, cross-framework IG implementation that spans TensorFlow and PyTorch, integrating deeply with Michelangelo, and scaling computation with Ray, we’ve made it a production-ready feature.
There are still some remaining challenges. Selecting the right baseline inputs and layers for attribution still requires deep model knowledge, making configuration a key usability hurdle. New users often face a steep learning curve navigating IG-specific concepts, parameters, and best practices. And while we’ve optimized batch IG for offline analysis, bringing explanation into low-latency online serving remains an active area of exploration, given its computational cost.
To address some of these, we’re now investing in:
- Smarter, more automated layer selection
- Embedding-aware and multi-layer attributions
- Model-agnostic explanations that minimize manual configuration
We’ll continue to make interpretable deep learning a priority at Uber—not just for ML engineers, but for operations teams, product managers, and decision-makers across the business. As we continue to enhance explainability, we’re developing ML systems that aren’t just powerful, but also practical to explain.
Cover photo attribution: “Cat: Collaborating with a Neural Network / Rachel Smith (DE)” by Ars Electronica is licensed under CC BY-NC-ND 2.0.
Jupyter® and Jupyter® logo are registered trademarks of LF Charities in the United States and/or other countries. No endorsement by LF Charities is implied by the use of these marks.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Ray is a trademark of Anyscale, Inc.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
Alibi and Captum are open-source projects governed by their respective maintainers.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.

Hugh Chen
Hugh Chen is a Software Engineer on Uber’s AI platform team. He’s currently the leading engineer on explainability.

Eric Wang
Eric Wang is a Senior Staff Software Engineer working on Uber’s Machine Learning Platform, focusing on developing scalable solutions to enhance the entire machine learning lifecycle.

Gaoyuan Huang
Gaoyuan Huang is a former Software Engineer on Uber’s AI platform team in the San Francisco Bay Area. He specializes in the end-to-end machine learning model development lifecycle, ensuring AI solutions move seamlessly from research to production.

Howard Yu
Howard Yu was a Senior Software Engineer on the Uber AI Platform that worked on various ML quality initiatives. He’s now working on Uber’s EngSec AI team focusing on using ML to improve security and privacy in different areas.

Jia Li
Jia Li is a Staff Engineer on the Michelangelo team. He has focused on ML monitoring work for the last few years.

Sally Lee
Sally is a Senior Staff Tech Lead Manager who leads Uber’s Core ML platform, Michelangelo. With over 15 years of experience, she’s passionate about applying machine learning solutions to large-scale business problems.
Posted by Hugh Chen, Eric Wang, Gaoyuan Huang, Howard Yu, Jia Li, Sally Lee