From Batch to Streaming: Accelerating Data Freshness in Uber’s Data Lake
December 11 / Global
Introduction
At Uber, the data lake is a foundational platform powering analytics and machine learning across the company. Historically, ingestion into the lake was powered by batch jobs with freshness measured in hours. As business needs evolved toward near-real-time insights, we re-architected ingestion to run on Apache Flink®, enabling fresher data, lower costs, and scalable operations at petabyte scale.
Over the past year, we built and validated IngestionNext, a new streaming-based ingestion system centered on Flink. We proved its performance on some of Uber’s largest datasets, designed the control plane for operating thousands of jobs, and addressed streaming-specific challenges such as small file generation, partition skew, and checkpoint synchronization. This blog describes the design of IngestionNext and early results that show improved freshness and meaningful efficiency gains compared to batch ingestion.
Why Streaming?
Two key drivers motivated our move from batch to streaming: data freshness and cost efficiency.
As the business moved faster, the Delivery, Rider, Mobility, Finance, and Marketing Analytics organizations at Uber consistently asked for fresher data to power real-time experimentation and model development. Batch ingestion provides data with delays of hours—or in some cases, even days—limiting the speed of iteration and decision-making. By re-platforming ingestion on Flink, we cut freshness from hours to minutes. This shift directly accelerates model launches, experimentation velocity, and analytics accuracy across the company.
When considering cost efficiency, Apache Spark™ batch jobs are resource-heavy by design. They orchestrate large distributed computations at fixed intervals, even when workloads vary. At Uber’s scale—thousands of datasets and hundreds of petabytes—this translates into hundreds of thousands of CPU cores running daily. Streaming eliminates the overhead of frequent batch scheduling, enabling resources to scale with traffic in a smoother, more efficient way.
Architecture at a Glance
The IngestionNext ingestion system is composed of multiple layers.
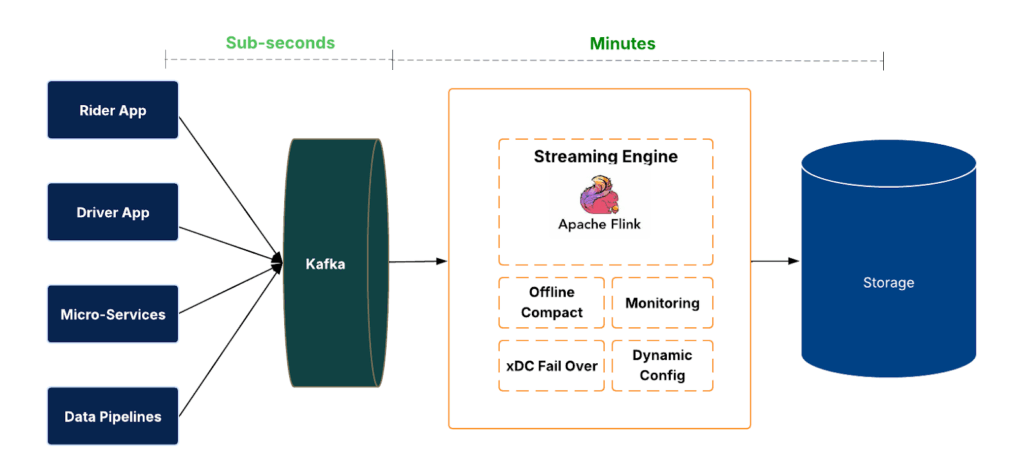
At the data plane, events arrive in Apache Kafka® and are consumed by Flink jobs. These jobs write to the data lake in Apache Hudi™ format, providing transactional commits, rollbacks, and time travel. Freshness and completeness are measured end-to-end, from source to sink.
Managing ingestion at scale requires automation. We designed a control plane that handles the job life cycle (create, deploy, restart, stop, delete), configuration changes, and health verification. This enables operating ingestion across thousands of datasets consistently and safely.
The system is also designed with regional failover and fallback strategies to maintain availability. In the event of outages, ingestion jobs can shift across regions or temporarily run in batch mode, ensuring continuity and no data loss.
Key Challenges and Solutions
Small Files
Streaming ingestion often generates many small Apache Parquet™ files, which significantly degrade query performance and increase metadata and storage overhead. This is a common challenge when data arrives continuously and must be written in near real time.
The traditional and most common merging method operates record by record, requiring each Parquet file to be decompressed, decoded from columnar to row format, merged, and then re-encoded and compressed again. While functional, this approach is computationally heavy and slow due to repetitive encode/decode transformations.
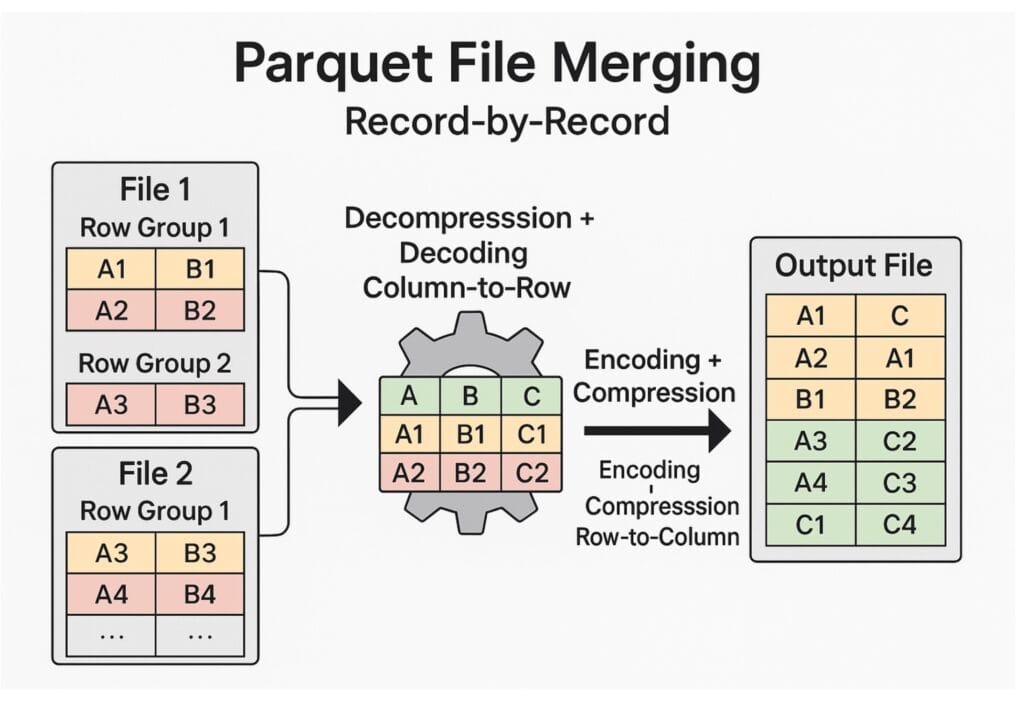
To overcome this, we introduced row-group-level merging, which operates directly on Parquet’s native columnar structure. This design avoids costly recompression and accelerates compaction by more than an order of magnitude (10x).
Open-source efforts such as Apache Hudi PR #13365 have explored schema-evolution-aware merging using padding and masking to align differing schemas, but this adds substantial implementation complexity and maintenance risk.
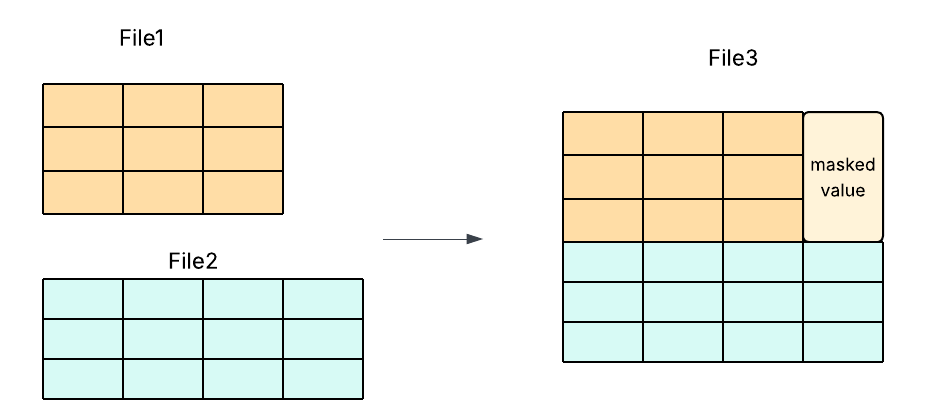
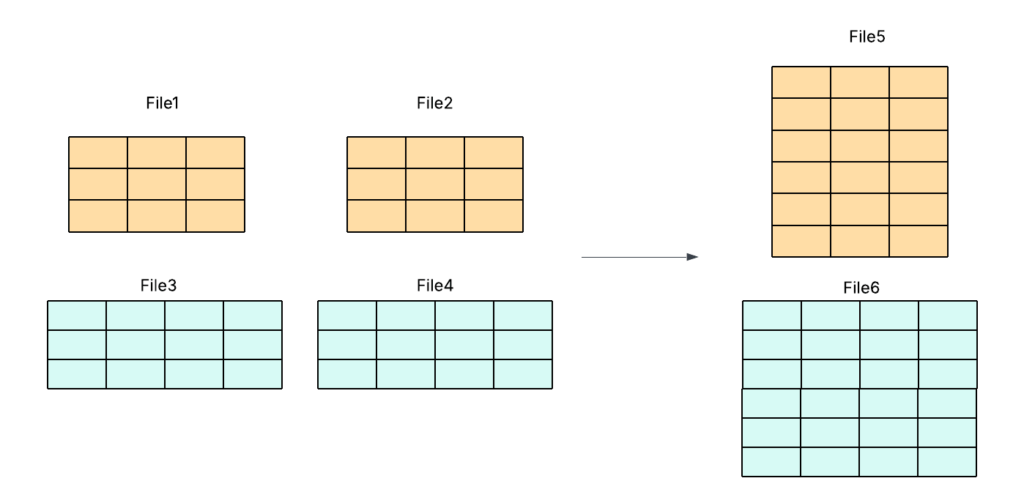
Our approach simplifies the process by enforcing schema consistency—merging only files that share an identical schema. This eliminates the need for masking or low-level code modifications, reducing development overhead while delivering faster, more efficient, and more reliable compaction.
Partition Skew
Another problem we faced was that short-lived downstream slowdowns (like garbage collection pauses) can unbalance Kafka consumption across Flink subtasks. Skewed data leads to less efficient compression and slower queries.
We addressed this through operational tuning (aligning parallelism with partitions, adjusting fetch parameters), connector-level fairness (round-robin polling, pause/resume for heavy partitions, per-partition quotas), and improved observability (per-partition lag metrics, skew-aware autoscaling, and targeted alerts).
Checkpoint and Commit Synchronization
We also found that Flink checkpoints track consumed offsets, while Hudi commits track writes. If they become misaligned during a failure, data can be skipped or duplicated.
To solve this problem, we extended Hudi commit metadata to embed Flink checkpoint IDs, enabling deterministic recovery during rollbacks or failovers.
Results
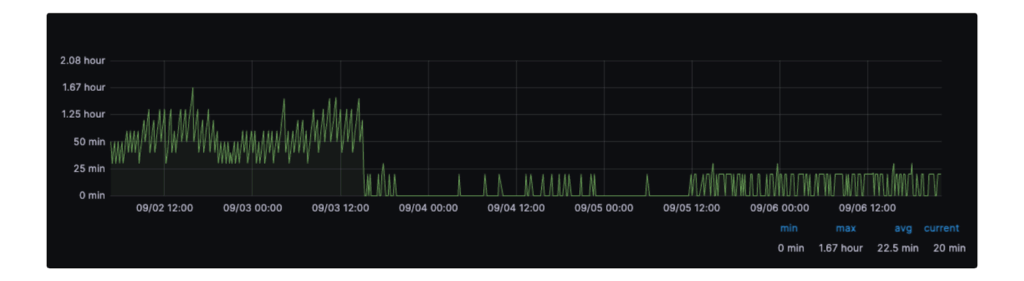
We onboarded datasets to the Flink-based ingestion platform and confirmed that Flink-based ingestion delivers minutes-level freshness while reducing compute usage by 25% relative to batch. Here is an example of the data freshness being improved.
Next Steps
We’ve significantly improved data ingestion latency with IngestionNext, moving from batch to streaming ingestion from online Kafka to the offline raw data lake. However, freshness still stalls downstream in transformation of the rawdata and analytics. To truly accelerate data freshness, we must extend this real-time capability end-to-end—from ingestion to transformation to real-time insights and analytics. This is especially critical now. Uber’s data lake, which powers the Delivery, Mobility, Machine Learning, Rider, Marketplace, Maps, Finance, and Marketing Analytics organizations, makes data freshness a top priority across these domains. Most datasets originate in ingestion, but without faster downstream transformation and access, data remains stale at the point of decision. The business impact spans experimentation, risk detection, personalization, and operational analytics—where stale data delays innovation, reduces responsiveness, and limits the ability to make proactive, data-driven decisions.
Conclusion
Our journey from batch to streaming marks a major milestone in Uber’s data platform evolution. By re-architecting ingestion on Apache Flink, IngestionNext delivers fresher data, stronger reliability, and scalable efficiency across Uber’s petabyte-scale data lake. The system’s design emphasizes automated resiliency and operational simplicity, enabling engineers to focus on building data-driven products rather than managing data pipelines.
What makes this compelling for engineers isn’t only the technical foundation—streaming ingestion, checkpoint synchronization, and fault-tolerant control planes—but also the systemic shift in mindset: treating freshness as a first-class dimension of data quality. With IngestionNext proven in production, the next frontier lies in extending streaming ETL and analytics to complete the real-time data loop, empowering all the teams at Uber to move faster with confidence.
Cover Photo Attribution: “Fast running stream. Nikon D3100. DSC_0384” by Robert.Pittman is licensed under CC BY-NC-ND 2.0.
Apache Flink, Flink, and the Flink logo, Apache Spark, Apache Parquet, Kafka, and Hudi are either registered trademarks or trademarks of The Apache Software Foundation in the United States and other countries.
Presto® is a registered trademark of LF Projects, LLC.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.

Xinli Shang
Xinli Shang is the ex–Apache Parquet™ PMC Chair, a Presto® committer, and a member of Uber’s Open Source Committee. He leads several initiatives advancing data format innovation for storage efficiency, security, and performance. Xinli is passionate about open-source collaboration, scalable data infrastructure, and bridging the gap between research and real-world data platform engineering.

Peter Huang
Peter Huang is the architect of Uber’s hybrid cloud streaming platform and an active committer for OpenLineage. He leads several key initiatives, including the Self-Serve Flink SQL platform and the evolution of Uber’s streaming ingestion infrastructure. His primary focus is on enabling business-critical use cases by designing highly reliable and scalable data processing systems built on Apache Flink.

Jing Li
Jing Li is a Senior Staff Engineer on the Data team at Uber. She has been working on multiple domains including data ingestion, data quality and open table format.

Jing Zhao
Jing Zhao is a Principal Engineer on the Data team at Uber. He is a committer and PMC member of Apache Hadoop and Apache Ratis.

Jack Song
Jack Song is an engineering leader specializing in large-scale Data and AI platforms. At Uber, he leads the Data Platform organization, building multi-cloud infrastructure, multi-modal data systems, and the agentic automation layer that powers Uber’s next-generation Data AI Agents.
Posted by Xinli Shang, Peter Huang, Jing Li, Jing Zhao, Jack Song