Apache Hudi™ at Uber: Engineering for Trillion-Record-Scale Data Lake Operations
January 16 / Global
The Foundation of Uber’s Data Platform
Uber operates one of the most diverse and demanding data ecosystems in the world. Every trip taken, order delivered, ad served, or real-time arrival time recalculated generates an unending stream of data. These data points come from hundreds of microservices, thousands of cities, and millions of riders, each with its own velocity, shape, and business-criticality. At the heart of this ecosystem lies Uber’s data lake: a multi-hundred-petabyte repository that fuels operational decisions, machine learning models, experimentation platforms, and real-time business intelligence.
Powering this data lake requires far more than storing large volumes of data. Constant mutation, high cardinality, fast-changing schemas, and a relentless requirement for data freshness characterize Uber’s workloads. Many of Uber’s teams require data that isn’t only large in scale (trillions of rows in a single dataset), but also accurate within minutes, not hours.
This combination, unprecedented scale, relentless freshness, and high operational rigor, created a unique challenge that existing data lake technologies couldn’t meet at the time. And this challenge led to the birth of Apache Hudi™, a data lake storage engine designed and built at Uber. Hudi introduced the industry to a new paradigm: bringing database-like primitives (ACID transactions, indexing, incremental processing) directly to the data lake while retaining its scalability and flexibility. Since then, Hudi has grown into a critical pillar of Uber’s data platform, powering tens of thousands of datasets, handling massive daily ingestion volumes, and providing the consistency and freshness guarantees required by virtually every business line at Uber, from mobility and delivery to ads, marketplace, safety, and maps.
In this blog, we’ll take readers behind the scenes of the world’s largest Hudi deployment and one of the largest centralized data lakes on the planet, how Hudi was born at Uber, and how it evolved to handle trillion-record workloads. We’ll also show how Hudi fits into Uber’s broader data platform, the scale at which it operates, and the lessons we’ve learned after nearly a decade of managing one of the most demanding data lakes ever built.
Why We Built Hudi
By 2015, Uber’s data systems were expanding faster than any off-the-shelf technology could keep up with. We were ingesting data from thousands of microservices, dozens of new product lines, and a rapidly globalizing footprint. Data wasn’t only increasing in volume—it was constantly changing, with new events, backfills, late-arriving updates, and fast-evolving schemas becoming the norm. At that time, the industry standard data lake was fundamentally file-based, append-only, and batch-oriented. These architectures worked well for static or slowly evolving datasets, but they fell short on the workloads that mattered most to Uber:
- Mutable data models (trip life cycle, order states, device attributes, account changes)
- High-volume streams with high update rates
- End-to-end incremental processing to avoid full-table recomputation
No available solution provided a reliable way to maintain fresh, query-ready tables while supporting ACID guarantees, fast upserts, and near-real-time ingestion of frequently changing data. We needed the performance characteristics of a database system without giving up the openness, flexibility, and scale of the data lake. This gap is what led Uber engineers to build Hudi, a new class of storage engine purpose-built for the data lake. Instead of treating the lake as passive file storage, Hudi added the three primitives that fundamentally changed how data lakes operate:
- ACID transactions. Ensuring correctness despite concurrency, retries, late data, or overlapping pipelines.
- Indexing and fast upserts. Making it possible to update rows efficiently across hundreds of partitions and billions of records.
- Incremental processing. Allowing pipelines to read only what changed since the last commit instead of scanning terabytes each time.
Even as open-source Hudi has matured, Uber’s internal scale has pushed far beyond its original boundaries. That pressure led to innovations such as the Metadata Table, Record Index, multi-data-center sync, and highly optimized table services.
Apache Hudi Community and Ecosystem Highlights
The Apache Hudi community has had a broad reach, with 6,030 GitHub stars, over 15,000 members across Hudi Slack® and GitHub®, and 17,500 followers across LinkedIn® and X®.
The project has also seen large-scale activity, with over 10,000 pull requests, 6,500 issues, 7,500 Slack messages resolved, and over 85,000 GitHub interactions (comments, reviews, and so on).
According to ossinsight.io, there are over 50 contributing companies to the ecosystem. Over 36,000 companies visit the Hudi website, including 65% of Fortune 500 companies. Further, 10 cloud providers support Hudi, including the big three of AWS®, Microsoft Azure®, and GCP (Google Cloud Platform™ ).
For project governance, there are 20 PMC members. Contributions are large, with 41 committers and over 2,000 contributors.
Data at Uber Scale
To understand why Hudi is indispensable at Uber, it’s important to appreciate the scale at which our data platform operates. Uber doesn’t just run a large data lake; we run one of the largest and most diverse production data lake environments ever built, with data patterns spanning mobility, delivery, freight, mapping, ads, pricing, safety, experimentation, and real-time machine learning. Every one of these workloads has its own shape, its own cadence, and its own tolerance for latency. Hudi sits at the center of this ecosystem, orchestrating billions of records and thousands of tables with strong guarantees of correctness and freshness.
Hudi’s Daily Footprint at Uber
Here are the high-level aggregate metrics that represent the magnitude of operations Hudi supports within Uber’s data platform.
- 19,500 Hudi datasets managed across multiple business domains
- 6 trillion rows across ingested per day and 3 million new data files added
- 350 logical petabytes on HDFS™ and Google Cloud Storage
- 10 petabytes ingested per day and over 3 petabytes written to the data lake
- 350,000 commits per day
- 70,000 table service operations daily (compactions, cleans, clustering)
- 4 million analytical queries served via Presto® and Apache Spark™ per week
- Ultra-large tables exceeding 400 billions rows that update continuously
- The majority of datasets are partitioned by date, optimized for large-scale distributed processing
These numbers highlight a simple truth: no other open data lake technology had been tested at this scale before. Running Hudi at Uber effectively meant inventing new operational patterns, new indexing systems, and new table services—many of which have since influenced the open-source roadmap.
Every dataset at Uber maps to one of several workload classes, each with unique operational behaviors, which drive how Hudi is configured and tuned.
Append-Only Datasets (11,200 tables)
Append-only tables constitute the majority of Uber’s datasets and are responsible for the highest data ingestion volume. These tables, which include data from raw ingestion sources, use Apache Hudi’s bulk insert capabilities to efficiently ingest billions of rows and thousands of Parquet files into the data lake. The speed of these bulk inserts is a critical factor, directly determining the freshness SLA offered to data lake users while simultaneously ensuring optimal file sizing and a query-friendly data layout.
Upsert-Heavy Datasets (4,400 tables)
Upsert datasets model changing business states, sometimes with very high update frequencies or sparse updates in enormous datasets. These tables use index-based lookups to achieve high write throughput and fast commits.
Derived Datasets (1,600 tables)
Derived datasets power Uber’s analytics and machine learning ecosystem through transformations, joins, and aggregations of raw Hudi datasets. We use both Spark batch jobs and Hudi Streamer to run these pipelines, using incremental reads to process only new or changed data from upstream tables. Freshness remains important, but correctness and schema evolution become equally critical, especially when the upstream tables may themselves get rolled back or fixed. Even though the source tables can be append-only, the derived tables doing incremental aggregations move to a mutable data model. So, having data lake storage that’s upsert-optimized is crucial at Uber.
Realtime Ingestion (Flink®-Native Streaming) (500 tables)
Uber has been steadily shifting a portion of ingestion from Spark-based batch jobs to Flink®-native streaming to support sub-15-minute freshness SLOs. Real-time ingestion is designed for very high-throughput, low-latency writes as the primary goal, and various data optimizations (file stitching, data sorting, data encryption) are applied asynchronously through our Table Services Platform continuously without blocking ingestion.
This workload diversity is one of the defining characteristics of Uber’s data platform and a key reason Hudi evolved beyond standard open-source capabilities.
Running Hudi at Uber is a continuous journey of scaling, optimizing, and engineering beyond established boundaries.
Uber’s Data Lake Technology Stack
Hudi is a foundational component of Uber’s data lake, but its real power lies in its seamless integration with the rest of Uber’s data platform. At Uber’s scale, no system can exist as a standalone component. Instead, Hudi participates in a deeply interconnected stack spanning ingestion, orchestration, compute, querying, observability, and downstream ML and analytics platforms.
This section provides a high-level view of that architecture and explains how Hudi fits into it.
Ingestion Layer
Spark Batch Ingestion is used for large-scale, hourly, or daily pipelines, handling backfills, reprocessing, and high-throughput batch writes. It powers bulk inserts into both append-only and upsert tables and has been extensively optimized using custom serializers and shuffle strategies. The ingestion process writes directly into Hudi tables, relying on Hudi’s commit protocol to produce atomic, consistent snapshots. The thousands of pipelines writing to Hudi tables are managed by an internal scheduler called Piper, which executes DAGs, manages retries, enforces SLAs, and tracks failures.
Flink Streaming Ingestion is designed for continuous, low-latency writes and supports event-time ordering, watermarking, and high-concurrency pipelines. It’s ideal for workloads requiring sub-15-minute freshness and is enabling Uber’s shift to streaming-native ingestion across critical business lines. Streaming ingestion is a significant focus area for Uber for achieving data freshness targets in minutes.
Query Layer: Spark, Presto, and Downstream Platforms
Two analytical engines dominate query access to Hudi tables at Uber: Apache Spark and Presto. Apache Spark is heavily used for complex data engineering and ML workflows, including ETL pipelines, feature engineering, and distributed batch ML workloads. A deeply optimized integration between Spark and Hudi enables fast scans, pruning, and crucial incremental data processing via Hudi’s commit timeline.
In contrast, Presto is the go-to engine for high-concurrency, interactive analytics.
Observability and Monitoring
Managing over 18,000 datasets requires first-class observability, which Uber achieves by pairing Hudi with a comprehensive monitoring ecosystem. All Hudi operations emit M3-based metrics tracking events like read/write performance, commit latency, compaction throughput, file/growth rates, and even table health. An alerting system queries the metrics to address SLA misses, storage regressions, out-of-bound growth, and indexing or Metadata Table failures. This robust observability layer is essential for the operational excellence needed to manage a trillion-scale data lake.

Innovations at Scale: Engineering Beyond Hudi’s Limits
As Uber’s data lake grew from billions to trillions of records, we quickly discovered that even Hudi’s advanced architecture needed new capabilities. Many challenges we encountered were simply not present in typical data lake deployments. Hudi gave us the foundation—ACID transactions, incremental processing, upserts—but Uber’s scale demanded innovations that went far beyond the original design.
This section highlights three major engineering breakthroughs born inside Uber: MDT (Metadata Table), RI (Record Index), and Hudi sync for multi-data-center reliability and cloud migration.
Each of these systems represents a first-of-its-kind approach in the data lake space, enabling Hudi to handle workloads an order of magnitude larger than typical open-source installations.
Metadata Table: Solving the File Listing Problem at Extreme Scale
One of the earliest bottlenecks Uber faced as our lake grew was simply listing files. At tens of thousands of datasets—each with thousands of partitions and millions of files, the HDFS NameNode was overwhelmed. Frequent file listings from writers, readers, table services, and query engines introduced significant latency and operational instability. The MDT (Metadata Table) was created to eliminate these bottlenecks.
MDT is a Hudi-managed key-value store, backed by HFile (an SSTable-based format for fast indexing of metadata), that tracks all metadata needed for data operations such as file listings, column statistics (min/max values per Parquet file), and bloom filters. By storing this natively within Hudi, MDT avoids hitting the filesystem entirely for many operations. Being a key-value store, MDT allows O(1) lookups for keys at scale. Therefore, operations such as listing large folders can be completed in O(1) time by looking up the specific key corresponding to the directory being listed.
MDT fundamentally changed the economics of operating Hudi, allowing large-scale deployments without worrying about the load on the HDFS infrastructure. We’ve deployed MDT to over 90% of datasets in production.
Record Index
Upserts are among Uber’s most demanding workloads, as they require quickly locating the exact Parquet file and partition containing the record to be updated. While simple methods like Bloom filters or file scans suffice at a small scale, they are inadequate for the company’s trillion-record scale.
Uber’s initial solution relied on an external HBase index, which, although powerful, introduced operational complexity. To eliminate this significant dependency and reduce latency, Uber developed the Record Index (RI) natively within Hudi.
The RI is an HFile-backed data structure stored within the Metadata Table. It maps record keys to file groups, enabling O(1) key lookups without the need for external servers like HBase.
This Record Index is a critical enabler for efficient, large-scale updates, operating across 3,600 large tables that require frequent record-level modifications. For the largest tables, which exceed 300 billion rows, the index is sharded into up to 10,000 HFiles. This sharding facilitates highly parallelized lookups across thousands of executors, forming the backbone for rapidly locating millions of records within billion-row datasets during updates.
Performance is strong, with lookup latency consistently low, requiring only 1-2 milliseconds to resolve a single record key from an HFile. To support rapid adoption, the RI initialization process has been highly optimized, allowing massive tables (300 billion rows) to be onboarded in approximately 7 hours using about 4,000 executors. Ongoing work aims to extend this architecture to support tables with up to 1.2 trillion rows.
Beyond write operations, the Record Index also functions as a powerful search index on the query path, enabling fast, record-key-based lookups regardless of the overall dataset size.
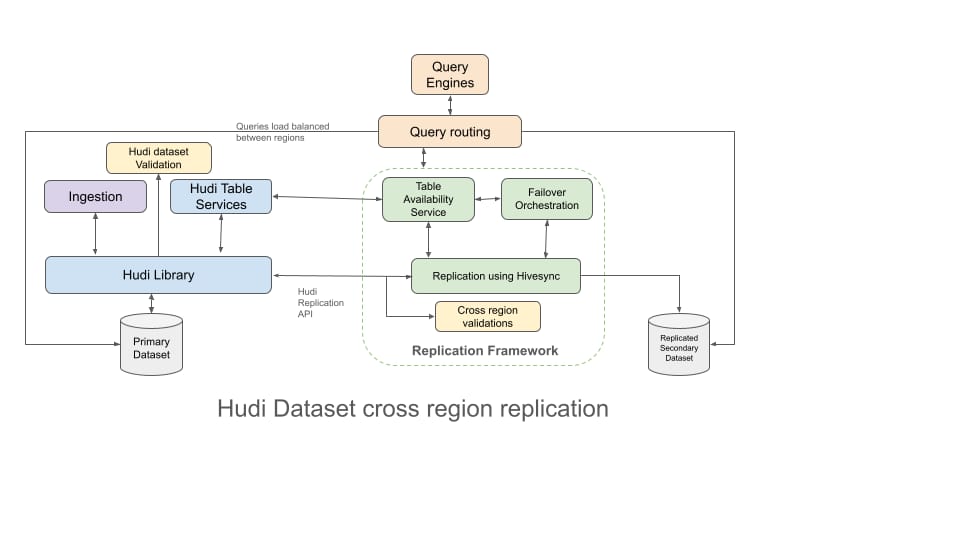
HiveSync: Multi-Data-Center and Cloud Migration Resilience
As Uber’s data lake became mission-critical for real-time decisions across mobility, delivery, maps, and commerce, ensuring datasets remained available and consistent across regions became a core architectural requirement. To improve elasticity and reduce fixed infrastructure costs, Uber also migrated portions of the data lake to cloud environments—completed without downtime or disruption to existing Hudi tables. Cloud storage now provides dynamic scaling while preserving the same consistency and replication guarantees that Hudi enforces on-prem.
At the center of Uber’s multi-data-center design is a primary dataset and a replicated secondary dataset. Hudi’s commit timeline and atomic operations make it possible to propagate every write, streaming, batch, or table-service generated, safely and consistently to the secondary region. Validation and consistency-checking tools ensure that cross-region replicas remain fully aligned and ready to take over instantly during failovers or to serve low-latency regional reads.
Uber’s table availability service and failover orchestration monitor regional health and promote the secondary dataset when disruptions occur. Intelligent query routing across Presto, Spark, and internal engines directs reads to the nearest or healthiest region, improving global query latency and balancing compute load.
Together, these capabilities make HiveSync the foundation of Uber’s multi-region reliability, disaster recovery, and cloud-enabled scalability, operating at significant production scale across both on-premises and cloud data centers.
Key Lessons from Operating Trillion-Row Data Lake Tables
Operating Hudi at Uber scale has taught us that building a data lake is only the beginning; keeping it consistent, fresh, and reliable across tens of thousands of datasets is an entirely different engineering challenge. Over the years, several themes have emerged that shape how we design, tune, and evolve our systems.
Data Changes
One of the earliest and most persistent lessons is that schema evolution must be treated as a first-class concern from day one. At Uber, schemas change constantly as product teams iterate, launch new features, or refine experimentation metrics. Doing backwards-incompatible changes like a seemingly harmless rename can break thousands of downstream jobs. Strong backward-compatibility rules, automated schema validation, and validating proposed schema changes have become critical guardrails. Without them, operational cost grows exponentially as the number of datasets increases.
Planning for the Hardest Workloads
Another defining insight is planning the tech stack around the toughest technical challenges first. Punting them to later and tackling easier challenges first can seriously derail the platform and projects. In our case, we learned to treat indexing as the backbone of a mutable data lake. While small deployments can get away with bloom filters and file scanning, Uber’s upsert-heavy workloads—often operating on tables with hundreds of billions of rows—require fast, deterministic record location. The development of the Record Index emerged from this necessity. It enabled true O(1) key lookups at scale, transforming ingestion performance and making upsert-driven pipelines viable on trillion-row tables. Without a scalable index, no amount of compute would make such workloads tractable.
What Gets Measured Gets Fixed
Equally important is the realization that constant automated observability and validations determine long-term platform health. Many of the most challenging incidents we faced stemmed from silent issues like corrupted files, configuration errors, and bugs in open source software. Our investment in the Hudi Validation tool allows us to detect inconsistencies early, often before they cascade into large-scale outages.
Config Management is Key
We also learned that configuration management becomes a scaling bottleneck faster than almost anything else. What starts as a few parameter overrides per dataset quickly turns into tens of thousands of subtly different configurations unless rigorously centralized. Uber’s Hudi Config Store solved this by providing a controlled, globally consistent configuration layer. As a result, new features, compaction logic, or file-sizing improvements can be rolled out across thousands of datasets safely and predictably.
Failures are the Norm
Finally, one of the most important lessons is that failures are inevitable, but recovery must be fast and safe. With thousands of pipelines rewriting data around the clock, even rare corner cases will eventually surface. The difference between a minor incident and a platform-wide outage often comes down to tooling: shadow pipelines for safe testing, automated backfill and repair systems, a variety of operational tools, and consistent validation frameworks. These systems transformed recovery from painful multi-day efforts into repeatable, runbook-based workflows.
Operating Hudi at Uber scale has reinforced a simple truth: extreme-scale data lakes succeed not because of individual features, but because of a disciplined operational ecosystem around them—collectively enabling Uber’s trillion-row tables to run reliably every day.
Why Hudi Remains Central to Uber’s Future
Nearly a decade after its creation, Hudi remains at the core of Uber’s data platform, not because it’s familiar, but because it continues to evolve alongside Uber’s rapidly changing needs. Few systems in the data ecosystem have demonstrated the ability to support both historical scale and next-generation workloads, and Hudi’s architecture gives Uber the flexibility to push forward without abandoning the foundational guarantees we rely on.
A prime example of this evolution is IngestionNext, Uber’s initiative to shift from batch to streaming ingestion. Hudi played a pivotal role in this re-architecture by bridging the gap between streaming runtime and storage. To solve data freshness challenges, we used Hudi’s commit metadata to embed Flink checkpoint IDs, ensuring deterministic recovery and preventing data duplication during failovers. Furthermore, Hudi’s flexible file management enabled a new row-group-level merging strategy that accelerates compaction by over 10 times, addressing the small-file problem inherent in streaming without complex schema masking. This synergy between Flink and Hudi reduced data latency from hours to minutes while cutting compute usage.
Looking ahead, Uber is solidifying its long-term strategy by engaging with Onehouse™ to accelerate the adoption of Hudi 1.x. This initiative is structured around three strategic pillars designed to de-risk, optimize, and expand our platform:
- Foundational modernization. We aim to eliminate the long-term maintenance overhead of our custom fork by porting internal Uber commits back to the open-source community. This effort aligns with a comprehensive upgrade to Hudi 1.x, targeting the deprecation of legacy RDD APIs to ensure a stable, community-aligned codebase.
- Performance optimization. To reduce operational costs, we’re implementing targeted improvements to clustering efficiency and developing tools for dynamic MDT (Metadata Table) sharding. These optimizations are critical for supporting tables with over a trillion records without service disruption. Additionally, we’re evaluating Hudi 1.x’s pluggable table formats to enable dual-writing to Apache Iceberg™, thereby providing data-driven insights for our future table format strategy.
- Capability expansion. We’re doubling down on real-time capabilities by scaling Flink-based ingestion with the Record Level Index for high-throughput, low-latency upserts. Concurrently, we’re enhancing DeltaStreamer for self-service onboarding and adopting modern Presto connectors to unlock advanced query features on mission-critical datasets.
This comprehensive roadmap ensures that Hudi not only remains the technical backbone of Uber’s data lake but also positions the platform at the forefront of community innovation, ready for the next decade of scale.
Acknowledgments
Cover Photo Attribution: ”Close up photo of mining rig” by Panumas Nikhomkhai is licensed under Free to Use.
Amazon Web Services®, AWS®, and the Powered by AWS logo are trademarks of Amazon.com, Inc. or its affiliates.
Apache®, Apache Hudi™, Flink®, HDFS™, Apache Spark™, Apache Iceberg™, and the star logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Azure® is a registered trademark of Microsoft, Inc.
GitHub® is a registered trademark of GitHub, Inc.
Google Cloud Platform™ is a trademark of Google LLC and this blog post is not endorsed by or affiliated with Google in any way.
LinkedIn is a registered trademark of LinkedIn Corporation and its affiliates in the United States and/or other countries.
Onehouse is a trademark of Infinilake Inc.
Presto® is a registered trademark of LF Projects, LLC.
Slack® is a registered trademark and service mark of Slack Technologies, Inc.
X® is a registered trademark of X Corp, Inc.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.

Prashant Wason
Prashant Wason is a Staff Software Engineer on Uber’s Batch Data Platform, where he works on building and scaling large-scale data lake and lakehouse systems, with a focus on table formats, data reliability, and performance at massive concurrency. He’s a committer and PMC member of the Apache Hudi project, and recently co-authored the book Apache Hudi: The Definitive Guide.

Balajee Nagasubramaniam
Balajee Nagasubramaniam is a Staff Software Engineer on Uber’s Batch Data Platform, where he works on building and scaling large-scale data lake and lakehouse systems. His focus areas include table formats, data replication, data quality and reliability, and optimizing large-scale production workloads to improve performance and reduce operational overheads.

Surya Prasanna Kumar Yalla
Surya Prasanna Kumar Yalla is a Senior Software Engineer on Uber’s Batch Data Platform, where he works on building and scaling large-scale data lake and lakehouse systems, with a focus on table formats, data ingestion, query performance, and optimization at massive scale.

Meenal Binwade
Meenal Binwade is an Engineer Manager on Uber’s Batch Data Platform, where she leads a team working on table formats and services. The team’s focus is on building highly scalable data lake and lakehouse systems.

Xinli Shang
Xinli Shang is the ex–Apache Parquet™ PMC Chair, a Presto® committer, and a member of Uber’s Open Source Committee. He leads several initiatives advancing data format innovation for storage efficiency, security, and performance. Xinli is passionate about open-source collaboration, scalable data infrastructure, and bridging the gap between research and real-world data platform engineering.

Jack Song
Jack Song is an engineering leader specializing in large-scale Data and AI platforms. At Uber, he leads the Data Platform organization, building multi-cloud infrastructure, multi-modal data systems, and the agentic automation layer that powers Uber’s next-generation Data AI Agents.
Posted by Prashant Wason, Balajee Nagasubramaniam, Surya Prasanna Kumar Yalla, Meenal Binwade, Xinli Shang, Jack Song