Improving MySQL® Cluster Uptime: Designing Advanced Detection, Mitigation, and Consensus with Group Replication
2 December 2025 / Global
Introduction
At Uber, engineers rely on MySQL® for applications that need relational databases. MySQL is the preferred choice for use cases that require ACID transactions and relational data modeling with a SQL interface. We support over 2,600 MySQL clusters.
MySQL clusters follow the topology of a single primary and multiple-replica model. The replication is by default asynchronous, where the replica nodes poll the binlogs from the primary server. Only the primary node is used to serve write requests, and the read requests are served from replicas in a round-robin fashion with region affinity. The number of replicas required in the cluster depends on the read volume served by the cluster.
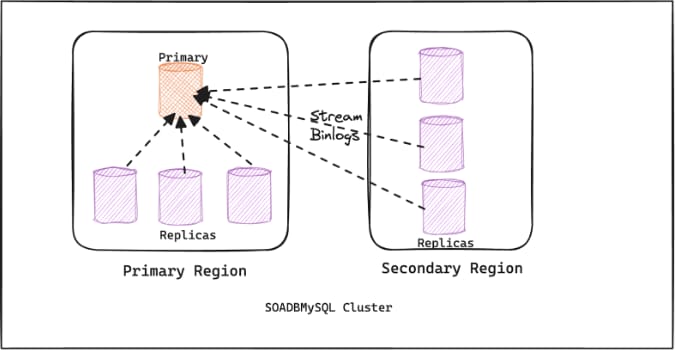
In the world of online services, a database going down isn’t just a minor issue. It can lead to service disruptions, unhappy customers, and lost revenue. While our existing systems have served us well, we’ve identified key areas for improvement, particularly when it comes to keeping our databases online and available.
At Uber, HA (High Availability) isn’t just a goal—it’s the very foundation of our systems. Maintaining a single, healthy MySQL leader node is critical for seamless operation. In the past (from 2020-2023), our systems failed to detect and mitigate numerous incidents reported over a Slack support channel within the promised time frame, leaving services disrupted. This translated to minutes of unnecessary downtime and lost revenue.
Our MySQL clusters relied on a setup with a single primary node and multiple read replicas. When the primary node failed, we used external systems like HC (Health Controller) and MEPA (MySQL Emergency Promotion Automation) to detect the problem and promote a new primary.
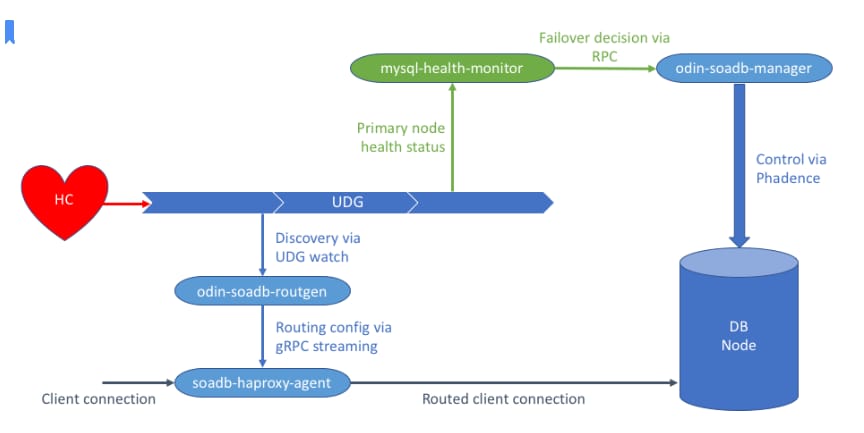
This approach, while functional, had significant limitations:
- High downtime. The time it took to detect a failure and promote a new primary (mean time to detect/resolve) was too long for our most critical services. Our SLAs were around 120 seconds (2 minutes) for mitigation.
- Reliance on external systems. The entire process depended on a chain of external components. If any of these failed, the failover process could be delayed or not happen at all. We saw many critical failures that our systems didn’t detect or mitigate within the promised timeframe, leading to service disruptions and unnecessary downtime.
- Lack of reliability. The systems were prone to issues and lacked the self-sufficiency needed to guarantee uptime without constant operational oversight.
We knew we needed a better solution—one that was more robust, faster, and could handle failures from within the database itself.
Architecture
After careful research, we decided to adopt a more decentralized approach using MGR (MySQL Group Replication). MGR is a plugin in MySQL that allows a group of MySQL servers to act as a single, fault-tolerant system. It uses a consensus protocol called Paxos to ensure that all members of the group have the same data at all times. This gives the cluster the ability to make its own decisions. When a primary node fails, the other nodes in the group can automatically and quickly elect a new primary without needing any external intervention.
We concluded that we needed to implement a consensus group of three MySQL nodes within the MySQL cluster. This approach significantly improves availability by enabling faster failover to a secondary node of the consensus group in the event of a primary node failure.
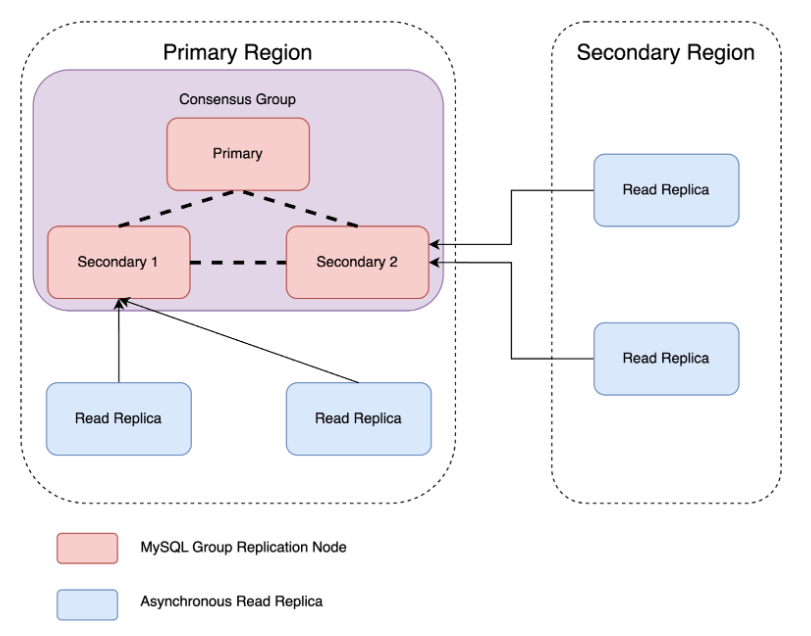
Consensus Group
To improve the availability and fault tolerance of our MySQL setup, we transitioned to an architecture with a consensus group and scalable read replicas.
A consensus group is a group composed of three MySQL nodes forming a consensus where one node acts as the primary, accepting write operations. The other two nodes in the same region as the primary node function as secondaries. They don’t accept direct writes, but participate in the consensus process for write operations. All nodes within the group maintain strong data consistency through a consensus protocol (like Paxos). This ensures all nodes have identical, up-to-date data.
With scalable read replicas, N read replicas distributed across various data centers are configured to replicate data from any secondary node within the consensus group. This allows for horizontal scaling of read capacity to handle increased read traffic while maintaining fault tolerance.
Benefits of the New Consensus Setup
The new consensus setup provides many benefits:
- Faster failover. When the primary node fails, the remaining nodes in the consensus group elect a new primary node automatically. This significantly reduces downtime for write operations compared to promoting a traditional read-only replica.
- No errant GTIDs post-primary failure. This design helps avoid errant GTIDs in failure scenarios. If the primary crashes, it may still have some uncommitted transactions that get rolled forward during recovery. But since no replicas are reading directly from the primary, these uncommitted transactions don’t get replicated outside the group. That way, the GTIDs from the failed primary don’t leak into the wider cluster, and we avoid errant GTID issues.
- In-built flow control in MGR. The flow control mechanism in MGR prevents a single, fast-writing primary node from overwhelming its secondary nodes, which could fall behind and eventually drop out of the cluster. MGR automatically monitors the queues of incoming transactions on each secondary node. If a queue grows too large, a signal is sent to the primary node to temporarily pause or slow down its transaction rate. This ensures that all nodes in the group can keep up, maintaining a healthy and consistent state across the entire cluster. This proactive approach to managing the workload prevents potential performance issues and ensures the stability and availability of the entire database.
- Increased availability. Group replication enables faster failover to a secondary node during primary node failures, minimizing downtime for write operations. This translates to improved overall application availability.
- Scalability. Adding read replicas to the secondary nodes allows for scalable read operations without impacting write performance.
Overall, having a consensus group among a few MySQL nodes within a cluster offers a compelling solution to enhance MySQL cluster availability by facilitating faster failover for write operations and ensuring strong data consistency. While some performance overhead may be introduced, the benefits in terms of improved application uptime and scalability make it a valuable option for high-availability deployments.
Consensus Protocol
MySQL Group Replication, the implementation for the HA setup, uses a consensus protocol based on the Paxos algorithm. Specifically, it employs a variant called Single-Decree Paxos or Multi-Paxos, which is optimized for database transactions.
There are two kinds of prominent setups in MySQL Group Replication: single primary and multi-primary. Let’s look at some of the key differences.
Complexity
Single-primary offers a simpler consensus process as there’s only one proposer of transactions. In contrast, multi-primary is more complex due to multiple nodes proposing transactions and the need for conflict resolution.
Conflict Potential
With single-primary there’s no conflict potential because only one node handles writes. Multi-primary has a higher conflict potential, requiring robust conflict resolution mechanisms. There are some known limitations in the multi-primary conflict resolution techniques. One example is around supporting foreign key constraints. Foreign key constraints that result in cascading operations executed by a multi-primary mode group have a risk of undetected conflicts.
Scalability for Writes
Single-primary is limited by the capacity of the single primary node. Multi-primary has better availability for writes as multiple nodes can handle write operations concurrently. But eventually, all the writes need to reach all the nodes.
Failover Impact
When considering failover impact, single-primary requires the election of a new primary, which can cause temporary disruption. With multi-primary, other primaries can continue processing writes, minimizing disruption.
Consistency
With single-primary, consistency is easier to maintain due to a single source of transactions. Multi-primary requires careful management of transaction order and conflict resolution to ensure consistency.
Considering the above differences, we deployed the single-primary setup due to its advantages and simplicity. It’s also the default setup for MySQL Group Replication.
Benchmarks and Performance
To prove the value of our new architecture, we ran a series of benchmarks. We used a tool called YCSB™(Yahoo! Cloud Serving Benchmark) to test the performance of our new high-availability setup against our old async and semi-synchronous configurations. We wanted to see how the new system performed under different loads.
Here’s how we ran the benchmark. We configured the YCSB tool to run different types of tests:
- Insert-only: Simulating a workload where we only add new data
- Update-only: Simulating a workload where we only modify existing data
- Read-only: Simulating a workload where we only read data
- Mix of reads and writes: Simulating a more typical workload
We measured latency, which is the time it takes for a single database operation to complete. Lower latency is always better.
The results were clear: while the new HA setup has a small performance overhead compared to the old asynchronous replication, the added benefits of fast failover and data consistency are well worth it.
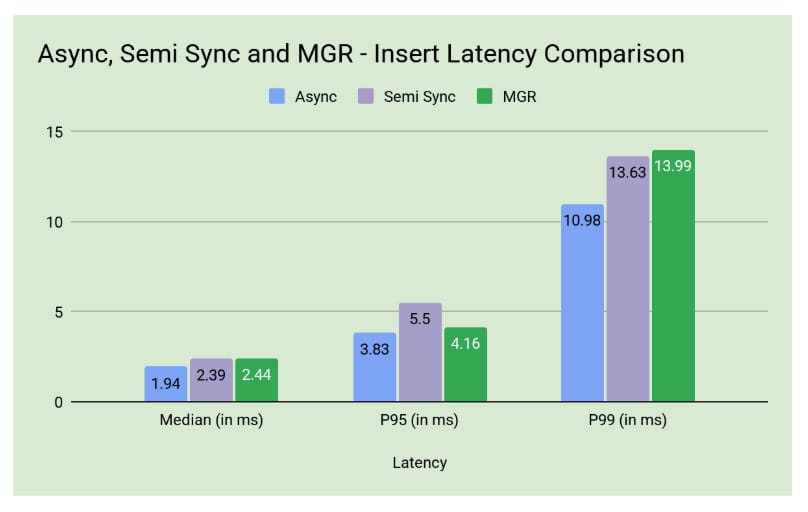
MySQL Insert Operations
For the new HA setup, there was about a 500 nanosecond increase in latency, which is a small cost for the huge gain in reliability.
| Latency | Async | Semi-Synchronous | HA |
| Median (in ms) | 1.938ms | 2.384ms (Δ446μs) | 2.436ms (Δ520μs) |
| P95 (in ms) | 3.831ms | 5.503ms (Δ1.6ms) | 4.159ms (Δ328μs) |
| P99 (in ms) | 10.983ms | 13.631ms (Δ2.6ms) | 13.999ms (Δ3.016ms) |
MySQL Update Operations
For the new HA setup, there was again a small increase in latency for a big jump in reliability.
| Latency | Async | Semi-Synchronous | HA |
| Median (in ms) | 1.432ms | 1.625ms (Δ193μs) | 1.771ms (Δ339μs) |
| P95 (in ms) | 2.065ms | 2.693ms (Δ628μs) | 2.359ms (Δ294μs) |
| P99 (in ms) | 6.131ms | 7.899ms (Δ1.7ms) | 8.791ms (Δ2.6ms) |

MySQL Read Operations
The new HA setup had virtually no difference in read performance compared to the old asynchronous setup. This is because reads are served by a local replica without needing to communicate with the rest of the consensus group. This is a huge win for us, as our systems are very read-heavy.
| Latency | Async | Semi-Synchronous | HA |
| Median (in ms) | 0.821ms | 0.82ms (almost same) | 0.85ms (Δ30μs) |
| P95 (in ms) | 1.01ms | 1.02ms (Δ10μs) | 1.04ms (Δ30μs) |
| P99 (in ms) | 1.34ms | 1.35ms (Δ10μs) | 1.37ms (Δ30μs) |
The benchmarks confirmed that our new HA architecture, while having a slightly higher write latency, provides the massive benefit of near-instant failover and zero data loss without impacting our read performance.
Improved Primary Promotion Time
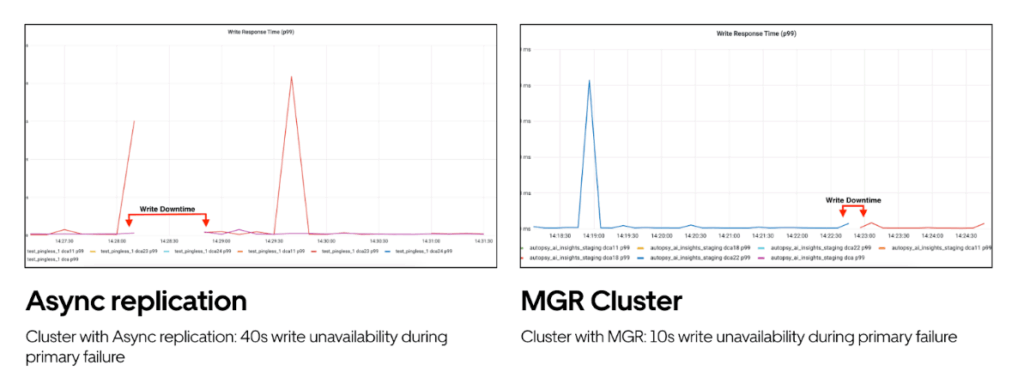
With the MGR cluster setup, we’re now able to achieve these SLAs:
- Time taken for MGR plugin to elect primary in case of emergency situation: <= 5 seconds
- Time taken for routing plane to get updated with latest primary: <= 5 seconds
- Total write unavailability: <= 10 seconds
Conclusion
Our journey toward improving MySQL cluster availability began with a hard look at the limitations of our traditional failover systems. While external health checks and emergency promotion tools got the job done, they came with tradeoffs in reliability, consistency, and recovery time.
By adopting MySQL Group Replication in a consensus-based, single-primary setup, we’ve laid a foundation that’s fundamentally more robust and autonomous. This new architecture reduces our reliance on external systems, enables faster failover through internal election protocols, and ensures data consistency across the consensus group.
We shared these results publicly at the MySQL and Heatwave Summit 2025.
In a future blog, we’ll dive deeper into how we operationalized this architecture at scale—covering automation workflows, node handling, failover behavior, and consistency guarantees of this setup.
Cover Photo Attribution: “Horse racing event” by tpower1978 is licensed under CC BY 2.0.
Java and MySQL are registered trademarks of Oracle® and/or its affiliates.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.

Siddharth Singh
Siddharth Singh is a Staff Software Engineer on the Core Storage team at Uber focusing on the reliability, availability, quality, and resiliency charters for MySQL/Vitess. He played a pivotal role as the lead for high availability via consensus in the MySQL project.

Raja Sriram Ganesan
Raja Sriram Ganesan is a Sr Staff Software Engineer on the Core Storage team at Uber. He’s the tech lead for MySQL initiatives and has led critical reliability and modernization projects for MySQL at Uber.

Amit Jain
Amit Jain is an Engineering Manager in the Storage organization and leads the charter of MySQL, sharded MySQL, CDC (Change Data Capture), and snapshot systems. His work centers on building reliable and scalable database infrastructure that delivers high availability and performance at Uber’s global scale.

Debadarsini Nayak
Debadarsini Nayak is a Senior Engineering Manager, providing leadership in the development and management of various online data technologies.
Posted by Siddharth Singh, Raja Sriram Ganesan, Amit Jain, Debadarsini Nayak