
Introduction
With Uber Eats, you can get almost, almost anything. We support every type of store you can find in your local community, from restaurants to small convenience stores, giant supermarkets, pet stores, pharmacies, and so on. This blog introduces the backbone for managing the retailer product data and inventory at Uber: INCA (INventory and CAtalog).
Motivation
Uber Eats was born in restaurants—optimized for menus with a few hundred dishes and a relatively simple set of use cases. But as our ambitions grew beyond food to include grocery, pharmacy, retail, and more, we faced a transformational challenge: could we scale our systems from serving meals to cataloging the modern retail universe?
Retailers like Walmart® and Carrefour™ operate with product catalogs that are orders of magnitude larger—hundreds of thousands of SKUs, rich metadata, and constantly shifting inventories. Supporting this complexity required a fundamental rethinking of our data infrastructure.
Our original restaurant-centric architecture assumed low data volume, minimal variation, and a direct pass-through model: what merchants sent, consumers saw. That simplicity was a strength in the early days—but it quickly became a bottleneck. Retail catalogs demand precision, extensibility, and context. A head of lettuce might need nutritional info, freshness validation, and local compliance tagging—all before it reaches the consumer.
To meet this challenge, we built INCA (INventory and CAtalog): a next-generation catalog system engineered to ingest, enrich, and publish massive, diverse inventories in real time. INCA isn’t just a solution—it’s a platform built to power the next decade of Uber’s growth in delivery and beyond.
We designed INCA with a few core principles:
- Unlimited scale. No practical limits on catalog size, product types, or fulfillment complexity.
- Extensibility. Product teams can introduce new attributes—like battery voltage or bottle deposit—on the fly.
- Smart behavior. Rules govern how products behave based on location, vertical, or merchant, making logic configuration modular and scalable.
- Enrichment-first: Sparse data gets enriched, validated, and quality-checked before ever reaching consumers.
- Taxonomy-driven: A curated, structured taxonomy enables search, compliance, and personalization.
- Industrial-grade ingestion: A robust external API supports both push and pull models, with built-in throttling and reliability at scale.
And critically, INCA is fast. We process billions of changes daily, with latency targets under a minute for critical updates like pricing and availability—all while keeping cost and performance in balance.
Architecture
Figure 1 shows the overall catalog pipeline at a functional level. The pipeline is intentionally split into the phases of ingestion, storage, publishing, and indexing to achieve a high degree of optimization at each stage. Had we combined one or more of these, we would have been constrained by solving multiple use cases in the same. An example of where this happens is how we index data in the storage phase versus the indexing phase, where the former is focused on normalized data and high throughput, and the latter on specialized queries to serve the app.
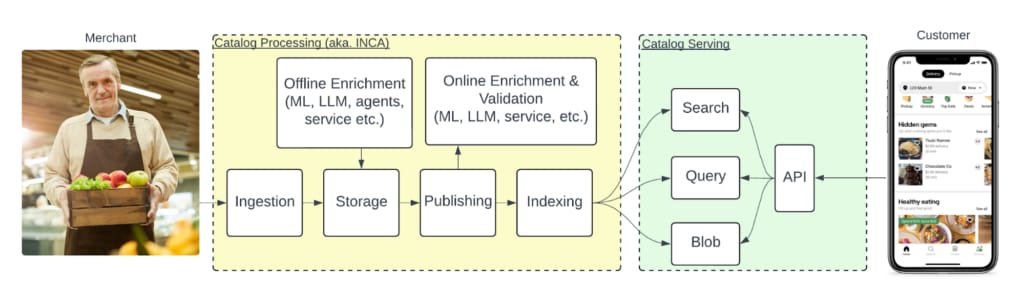
We start by ingesting retailer data and storing it. At that point, the data is just sitting there, and no customer can see it. Also, at this stage, we have only done basic data validation, like type checking, string sizes, and collection sizes. As described in the enrichment section later, the retailer’s data is generally sparse (containing only a price and a barcode) and not necessarily ready to be presented to a customer without thorough data enrichment. The sparse nature means that validating anything before we combine retailer data with all the enrichments Uber provides doesn’t make sense.
After the data is stored, the publishing process scans for new changes to publish. The publisher combines various versions of the data into a final entity (like a product or section we want to show the customer). During the publishing process, we reach out to online enrichers that provide just-in-time improvements on the entities. Online enrichers tend to deliver business-critical data such as product classification (e.g., is it a chair or a bottle of milk). We also query validation providers that tell us if, for example, a product is safe to put on the marketplace and has high-quality attributes.
The enrichers and validators come in all shapes and forms, and the intention is that the platform itself doesn’t care about what sort of data manipulation the business needs—the enrichment providers own that. As explained later, we can add and combine providers through configuration. We also have the concept of offline enrichers, who generally do the same things as online enrichers. They work independently from retailer data ingestion to the publishing flow. When offline enrichers touch catalog data, the publishing flow is retriggered to include the changes in the published data. Offline enrichers are generally used to improve catalogs out-of-band and are triggered by ML flows.
Finally, after publishing, we index the data to support various flows. Generally, we distinguish between searches (like freeform text search), queries (like give me vegan products for this store), and blobs (the actual data). Requests from the app can go into any of these categories.
The rest of the blog gives a high-level overview of INCA.
Data Model
We intentionally made the INCA data model generic to extend the catalog’s types and attributes easily. The model we used before for the restaurant business was tailored towards that domain and essentially structured like a restaurant menu. The problem was that it was difficult to extend generically and to support the many more attributes we needed for the retail domain.
The catalog itself is a graph of entity nodes. At the most basic level, we have the entity shown in Figure 2. The entity essentially has a type and zero or more extensions. An extension is a group of attributes like nutritional information, product image data, and store opening hours. Think of the entity-extension model as a general layer that allows us to model any type of extension and attribute.
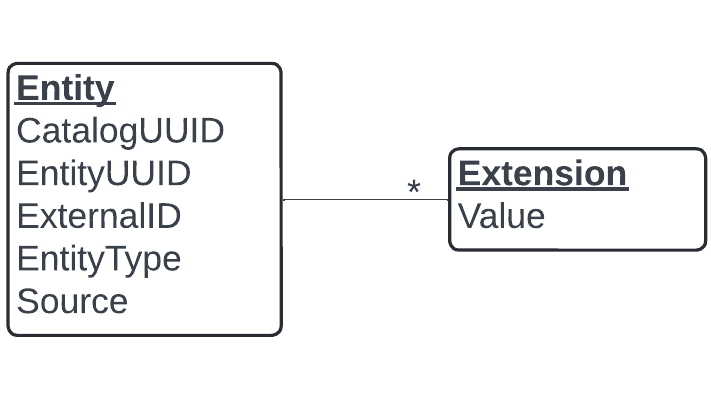
We address an entity by either the catalog UUID and externalID pair or only the entityUUID. We have both options because retailers use the externalID to address their entities, while we internally use the entityUUID at Uber. A significant reason for this split is to prevent retailers from controlling the internal entityUUID, which is globally unique within Uber. It also allows us to do so-called ID churn detection. ID churn happens when retailers don’t provide stable IDs between their ingestions. Below, we show a high-level example of how churn can happen.

The ID churn happens when retailers synchronize their catalogs with Uber and change the IDs of their items between each synchronization. A catalog synchronization replaces Uber’s copy of the retailer’s data with what they send. In this case, we would delete the Banana item with ID a-b-c-d since it is no longer referenced in the retailer’s catalog.
ID churn is a severe problem that affects the intelligence we’ve built for a specific entity, such as reordering and reranking. In those cases, we can remap the external IDs to known stable internal entity UUIDs.
We show the entity types in the catalog. The center of the universe is the item, which describes what we have for sale in terms of price, availability, and quantity. The item, also known as “offering” in the industry, refers to the retailer selling it, the sections where the customer can find it, and the so-called fulfillment selectors that describe how the item can be fulfilled (like delivery or pick-up). The item’s product describes what we’re selling. For example, it’s a water bottle with nutritional information, physical dimensions, and bottle fee. Finally, we can sell products together. Think bundles (buy two together), variants (choose shirt size and color), and combos (choose side and drink).
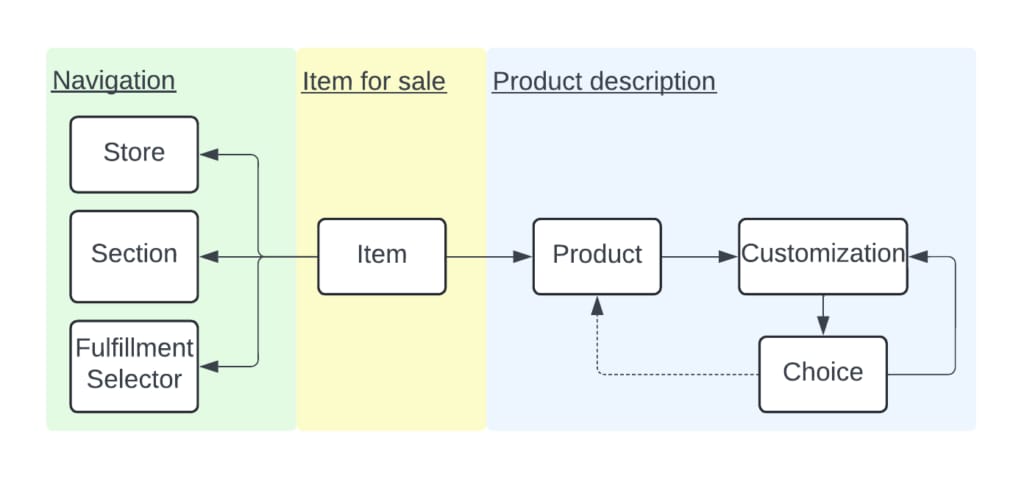
The source aspect of an entity plays a vital role in the namespace of different data providers. The namespaces mean that every entity data provider can contribute with improvements and without coordination. The publishing section later highlights how we combine various sources to create a final published data artifact.

We define the extensions as Google Protobuf™ schemas. We use the schemas as the single source of truth for data definition, and we have tooling to map them to database schemas, external APIs, and more.
Use Cases
This section describes retailer inventory and catalog use cases.
Ingestion
The general pattern for retailer integrations is that they provide one or more CSV files at an SFTP server, and Uber pulls the data at regular intervals. This is a preferred integration method for most grocery and retail retailers as they just have to snapshot their inventory periodically into a CSV file. Uber then provides the glue to bridge retailer CSV files with the internal INCA data definitions.
To scale onboarding, we built a way to express CSV mappers in Starlark™. Integration engineers can onboard a new retailer in a few lines of Starlark. Best change management practices, including code reviews and versioning, underpin the Starlark changes.
The output of the Starlark mappers is a so-called ingestion feed. The feed is a long list of entity operations to apply to a catalog. The feed can be either a full catalog synchronization or an incremental change. In the case of synchronization, each operation in the feed is a complete entity. We upsert the list of upserts and delete anything not referenced by the feed. For the incremental feed, we do update operations on the entities (that is, only update the parts specified in the feed). Synchronization helps specify an explicit full copy of a catalog, whereas incremental changes benefit minor, fast-moving updates like price and availability changes.
We execute the feed itself as Cadence workflows that provide fault-tolerant execution.
Publishing
Publishing should be straightforward. Given N sources for an entity, choose the best source for each attribute. The hard part is figuring out which data is best.
As mentioned in the functional overview, offline enrichers can write sources out-of-band. The publishers read those sources, including the retailer source. Some enrichment types are required to run at each publishing step. We query these online enrichers when publishing in a standard way. Besides online enrichers, we also call out validation providers that assess the outcome of the publishing process.
The initial INCA publishing process uses a so-called merge specification, a statically configured prioritized list of sources ranging from the least important to the most important. Generally, we grouped the retailer data as the least important, followed up with various enriched versions, and finally topped it off with manual changes applied by our Operations agents. We take retailer data as the starting point for every attribute and overlay each if we find more important sources. Figure 6 shows the merge step.
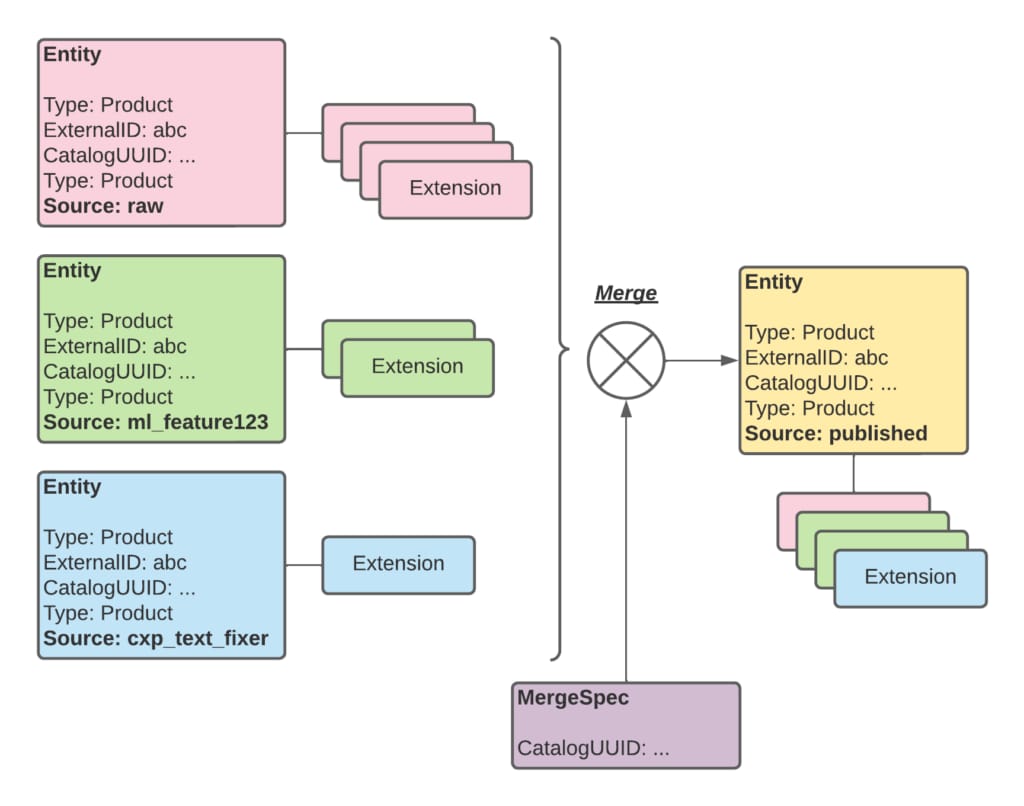
To break the merge step down from Figure 6, assume the merge logic is raw, then ml_feature123 and then cxp_text_fixer, the merge would proceed as follows:
- Use the raw source as the initial source for the published product. In Figure 6, the data provided by the raw source is pink.
- Overwrite attributes provided by the ml_feature123 source on the data provided by the raw source. In Figure 6, the data provided by the raw source is green.
- Overwrite attributes provided by the cxp_text_fixer source on the data provided by the raw and ml_feature123 source. In Figure 6, the data provided by the raw source is blue.
- The resulting merged published product’s attribute is a combination of the three sources.
The initial publishing logic works well and is easy to understand. However, with more and more enrichers adding sources, coming up with a fixed order of merging data is more complex. This basic logic led us to develop a new enrichment logic that’s much more advanced. Instead of working at the entity level, the logic works at the attribute level. Suppose multiple sources provide a value for an attribute. In that case, we have explicit rules that combine the data to achieve the nuanced ways we want to enrich data while having a clear, well-defined, and not the least traceable way to publish data.
We won’t describe the new logic in detail here (that’s for another blog post). The general idea is that the merge logic ends up being largely declarative based on various aggregation functions. For example, an attribute value could be based on quorum (choose the attribute most sources agree on), or based on a confidence score (each source attribute value includes a confidence score and we choose the highest), and so on.
Besides the merging logic, the publisher performs another exceedingly important task in terms of reliability: versioning! We periodically snapshot every catalog. We can roll back an entire catalog or store it in a previous state in data regression incidents. Versioning happens by including the version as part of the primary key of published data, so rolling back can be done instantly by changing the version used for retrieval.
Some of our largest catalogs include more than 100 million entities and take hours to ingest, enrich, validate, and publish. Rolling back a catalog or single store instantly is a game changer and serious operational muscle we’re proud to flex.
After the data is published, we index the generated data for various views.
Enrichments
The secret sauce for everything Uber does with the catalog during processing is the enrichments we apply. Some retailers provide excellent data, while others offer very sparse data that needs extensive work before it can be published.
We generally enrich data for two purposes: safety and high-quality attributes. Both are related, however. Getting to high-quality attributes enhances our system’s ability to handle restricted items that may trigger compliance requirements. Remember, even though Uber is a marketplace where retailers provide the underlying product data, Uber is committed to supporting compliance to maintain a high-quality and safe consumer experience. Generally, we must be sure that anything related to alcohol or tobacco is categorized as such. Depending on the market, the customer often must show identification to the courier before receiving their order.
Besides meeting safety regulations, high-quality attributes allow customers to ensure that what they order is what they want, helping reduce the return rate.
Some of the essential enrichments are listed below.
- Product descriptions. To facilitate in-app item description, we use LLMs to generate this description for retailers who have not provided them, with retailer review, where applicable.
- Uber product type. We categorize every product before publishing it for safety and discoverability.
- Canonical Products. We maintain curated versions of products that we use to enrich retailer products. If we find that a retailer’s product is the same as a canonical product, we link the two, and the publishing process bases much of the published data on the canonical product.
Regression Detection
Uber is the intermediary between the retailer and the customer—the retailer is responsible for the quality of data they send. However, if Uber customers end up having a bad experience due to bad data, the customer often perceives this as Uber having issues, instead of an issue on the retailer side.
INCA processes 100,000 changes per second. The speed is excellent from an ingestion point of view. Still, the mistakes can happen when, for example, retailers accidentally drop all items for a store, remove an entire aisle (like when a retailer stops sending dairy products), or all prices suddenly zero out or move unexpectedly across many products.
To avoid bad customer experiences, we put regression detection in place to catch incidents in real time. Regression detection is a difficult technical area that is a subject of another blog post.
Next Steps
The use cases listed above are only a sneak peek of what we want to do with the Uber catalog. At Uber, we understand that product selection, retailers, and couriers contribute to our success and that catalog technology itself is a competitive advantage. We have massive projects in the pipeline to continue to improve our external APIs, ingestion, enrichments, indexing, and retrieval with the latest technologies.
Conclusion
INCA provides a fast, extensible, and safe catalog processing pipeline. The data is rapidly growing, with INCA processing billions of retailer changes daily.
In future blogs, we’ll explore these areas in depth to explain how we perform ingestion, publishing, various enrichments, indexing, and more.
Cover Photo Attribution: The “white and red labeled pack on white shelf” image is covered by the Unsplash license and is credited to Franki Chamaki.
Carrefour™ is a trademark of CARREFOUR SA.
Protobuf™ and Starlark™ are trademarks of Google LLC.
Walmart® is a registered trademark of Walmart.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.

Kristian Lassen
Kristian Lassen is a Principal Engineer working for Uber Delivery, where he founded the INCA project. Kristian drives the technical vision for catalogs across Uber Delivery. He holds a PhD in Computer Science from Aarhus University.
Posted by Kristian Lassen