Requirement Adherence: Boosting Data Labeling Quality Using LLMs
21October,2025 / Global
The demand for labeled datasets continues to grow exponentially as machine learning and AI models are deployed across industries like autonomous vehicles, healthcare, retail, and finance. Uber AI Solutions provides industry-leading data labeling solutions for enterprise customers and plays a crucial role in enabling organizations to annotate data efficiently.
We’ve developed several internal technologies to ensure that our clients receive high-quality data. This blog highlights one such technology: our in-tool quality-checking framework, Requirement Adherence, which detects text labeling errors before submission.
Background
Labeling workflows typically rely on post-labeling checks or interhuman agreement to ensure the quality of the labeled data. While this is effective at ensuring quality, mislabeled and incomplete data must be sent back to experts for rework. This takes additional time, increases costs, and creates a bad experience for our enterprise clients.
A more effective approach is to identify quality issues within our in-house labeling tool, uLabel, during the labeling process. However, the diverse nature of data labeling requests from clients makes creating a custom solution for each instance unscalable. To address this, we developed a scalable system that uses an SOP (Standard Operating Procedure) document. This document, which includes all client requirements along with other information, is either provided by the client or compiled collaboratively by an Uber AI Solutions Program Manager and the client.
We use LLMs to extract the exact requirements from this document and enforce them during the time of labeling. The LLM calls are stateless and privacy-preserving, ensuring data integrity and confidentiality. We found that this two-step process is key to reliably label high-quality datasets. In addition to catching errors, we also provide suggestions on how to improve data labeling to adhere to the requirements.
Architecture
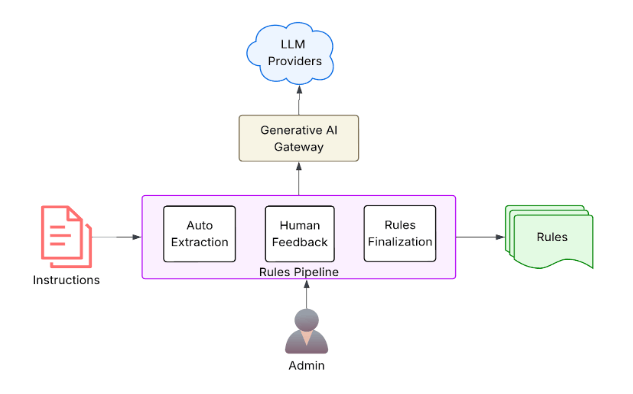
Requirement Adherence involves two steps: rule extraction and in-tool validation.
Rule Extraction
We first convert the SOP document into a markdown format to make it more optimal for processing in an LLM. The document usually lists multiple requirements for the labeled data. We found that a single LLM call to enforce all the requirements at once leads to hallucinations and missed enforcements. To simplify the task, we extract each requirement as an individual rule. The rules are designed to be atomic, unambiguous, and self-contained.
We found that the complexity of the rules varies and that different complexity requires different treatment during enforcement. So we also classify the rules into four categories:
- Formatting checks: For output format requirements (like using regex)
- Deterministic checks: For rules requiring specific words or exact matches
- Subjective checks: For rules requiring reasoning or interpretation based on input
- Complex subjective checks: For intricate logical flows and client objectives
We’ve designed our rule extraction logic using LLMs with a reflection capability. This allows the LLM to analyze the SOP text, generate a structured JSON output, check its work, and make changes if necessary.
We also allow for manual rules to be added at this stage to cover any gaps in the rules the LLM extracted or to add new requirements not included in the SOP document. We found that this human-in-the-loop step is useful to ensure high-quality rules.
Finally, we use another LLM call to ensure that the manual rules follow the required format and there’s no overlap between them and the auto-extracted rules. If there’s overlap, we suggest changes to finalize the list of rules.


In-Tool Validation
Once the rules are extracted and categorized, the next step is real-time validation during the labeling process in uLabel.
We’ve optimized the validation phase for efficiency and accuracy. Instead of a single, monolithic LLM call for all checks, we now perform a single validation call per rule. These calls can run in parallel, significantly speeding up the feedback loop for labelers. We rely on prefix caching to reduce the latency of the checks and create a better user experience.
Different rule types leverage different LLM strengths. Formatting checks are done using code, so an LLM isn’t involved. Deterministic checks use a non-reasoning LLM for speed and efficiency. Subjective and complex subjective checks use powerful reasoning LLMs, potentially with reflection or self-consistency built in, to handle the nuanced interpretation required. For example, a strong reasoning model might be used for subjective checks, while an additional reflection step is needed to handle complex subjective ones. This intelligent routing ensures that we apply the right computational power to the right problem, maximizing both accuracy and cost-efficiency.
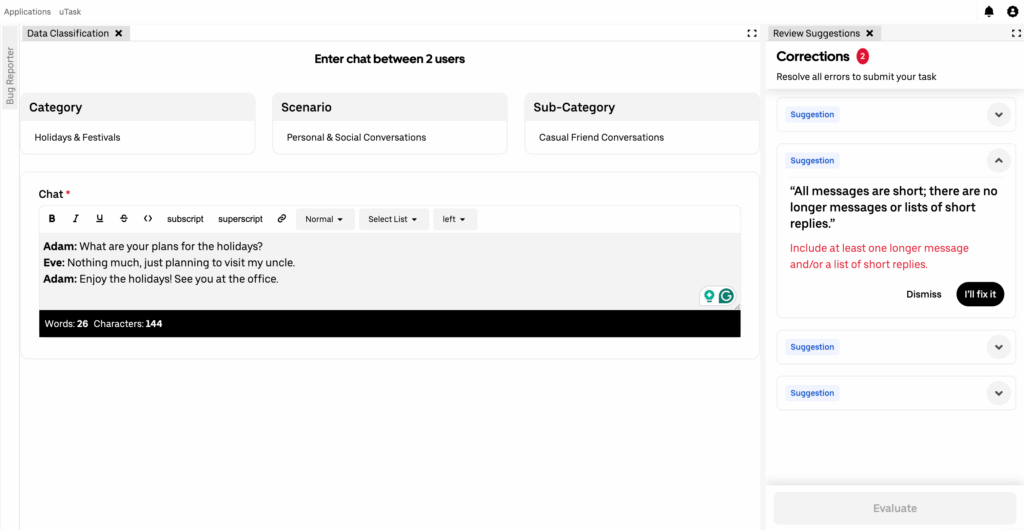
In addition to checking whether the labeling follows the rules, we also provide suggestions to the expert on the changes required to fix the quality issues. Alongside these validations, we also run spelling and grammar checks to assist the expert.
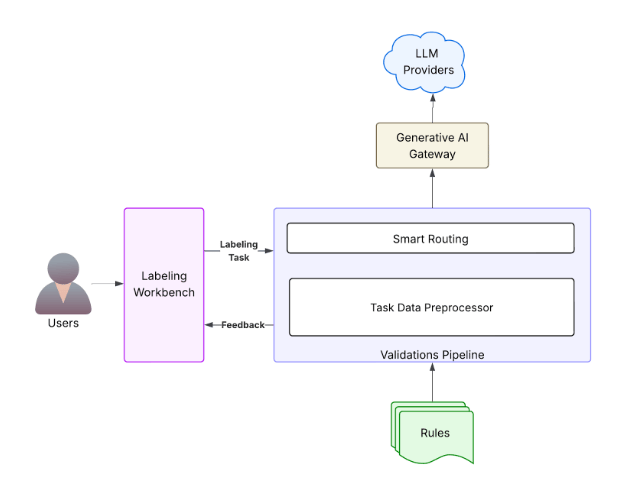
Figure 4 shows how the quality check happens in uLabel.
Results
By integrating this in-tool quality-checking framework, we observed a substantial enhancement in our in-tool annotation quality, which resulted in an 80% reduction in audits required, helping meet timelines and reduce costs. This validation is now a standard and widely adopted step within our annotation pipeline, used across our entire client base.
Next Steps
To make sure our system continuously improves, we’re building mechanisms to collect feedback on validations. This data is crucial for optimizing our LLM prompts over time, with a long-term goal of auto-optimizing them based on real-world performance.
We’re excited about how LLMs are transforming our approach to data quality, ensuring that Uber AI Solutions’s systems continue to be powered by the best possible data.
Conclusion
Uber AI Solutions’ LLM-powered Requirement Adherence system marks a significant advancement in data annotation quality. By integrating in-tool validation, we’ve reduced rework and ensured a consistently high standard of labeled datasets for our enterprise clients. This innovative approach, leveraging LLMs for rule extraction and real-time validation, is now a cornerstone of our annotation pipeline, enhancing efficiency and accuracy across all operations. As we continue to refine and optimize our prompts with real-world feedback, we’re confident that this technology will further cement Uber AI Solutions’s leadership in AI-driven data solutions.
Data Privacy
When using LLMs for rule extraction and validation, we ensure that no data from client SOPs is retained or used to train the models. All LLM interactions are designed to be stateless and to process data in a privacy-preserving manner, without compromising the integrity or confidentiality of the information.
OpenAI® and its logos are registered trademarks of OpenAI®.
Cover Photo Attribution: “Quality” by mikecohen1872 is licensed under CC BY-SA 2.0
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.

Siddarth Reddy Malreddy
Siddarth is a Staff AI Engineer, TLM based out of Hyderabad. He leads the development of key AI and machine learning initiatives for Uber AI Solutions.

Akshay Arora
Akshay is a Staff Software Engineer based out of Bangalore. He leads the development of the labeling platform for Uber AI Solutions.

Aditi Agarwal
Aditi is a Senior Product Manager based out of Bangalore. She leads the labeling platform, transforming raw data into model-ready truth via HITL.

Subrat Sahu
Subrat is a Software Engineer based out of Bangalore. He’s part of the labeling platform team for Uber AI Solutions.

Nikhil Mittal
Nikhil is a Software Engineer based out of Bangalore. He’s a member of the labeling platform team for Uber AI Solutions.

Rupal Khare
Rupal is an Engineering Manager based out of Bangalore. She leads the labeling platform team.
Posted by Siddarth Reddy Malreddy, Akshay Arora, Aditi Agarwal, Subrat Sahu, Nikhil Mittal, Rupal Khare