Evolving Michelangelo Model Representation for Flexibility at Scale
October 16, 2019 / Global
Michelangelo, Uber’s machine learning (ML) platform, supports the training and serving of thousands of models in production across the company. Designed to cover the end-to-end ML workflow, the system currently supports classical machine learning, time series forecasting, and deep learning models that span a myriad of use cases ranging from generating marketplace forecasts, responding to customer support tickets, to calculating accurate estimated times of arrival (ETAs) and powering our One-Click Chat feature using natural language processing (NLP) models on the driver app.
Most Michelangelo models are based on Apache Spark MLlib, a scalable machine learning library for Apache Spark. To handle high-QPS online serving, Michelangelo originally supported only a subset of Spark MLlib models with in-house custom model serialization and representation, which prevented customers from flexibly experimenting with arbitrarily complex model pipelines and inhibited Michelangelo’s extensibility velocity. To address these issues, we evolved Michelangelo’s use of Spark MLlib, particularly in the areas of model representation, persistence, and online serving.
Motivation behind Michelangelo’s Spark MLlib evolution
We originally developed Michelangelo to provide scalable machine learning models for production. Its end-to-end support for scheduled Spark-based data ingestion, model training, and evaluation, along with deployment for batch and online model serving, has gained wide acceptance across Uber.

More recently, Michelangelo has evolved to handle more use cases, including serving models trained outside of core Michelangelo. For instance, scaling and accelerating end-to-end training of deep learning models requires operational steps performed in differing environments in order to leverage the distributed computation of Spark transformations and low-latency serving of Spark Pipelines on CPUs as well as distributed deep learning training on GPU clusters using Horovod, Uber’s distributed deep learning framework. To facilitate these requirements and guarantee training and serving consistency, it is critical to have a consistent architecture and model representation that can leverage our existing low-latency JVM-based model serving infrastructure while providing the right abstraction to encapsulate these requirements.

Another motivation is to empower data scientists to build and experiment with arbitrarily complex models in familiar Jupyter Notebook environments (Data Science Workbench) with PySpark while still being able to leverage the Michelangelo ecosystem to reliably do distributed training, deployment, and serving. This also opens up the possibilities for more complex model structures required by ensemble learning or multi-task learning techniques while allowing users to dynamically do data manipulation and custom evaluations.
As such, we revisited Michelangelo’s use of Spark MLlib and Spark ML pipelines to generalize its mechanisms for model persistence and online serving in an effort to achieve extensibility and interoperability without compromising on scalability.
Michelangelo was initially launched with a monolithic architecture that managed tightly-coupled workflows and Spark jobs for training and serving. Michelangelo had specific pipeline model definitions for each supported model type, with an in-house custom protobuf representation of trained models for serving. Offline serving was handled via Spark; online serving was handled using custom APIs added to an internal version of Spark for efficient single-row predictions.
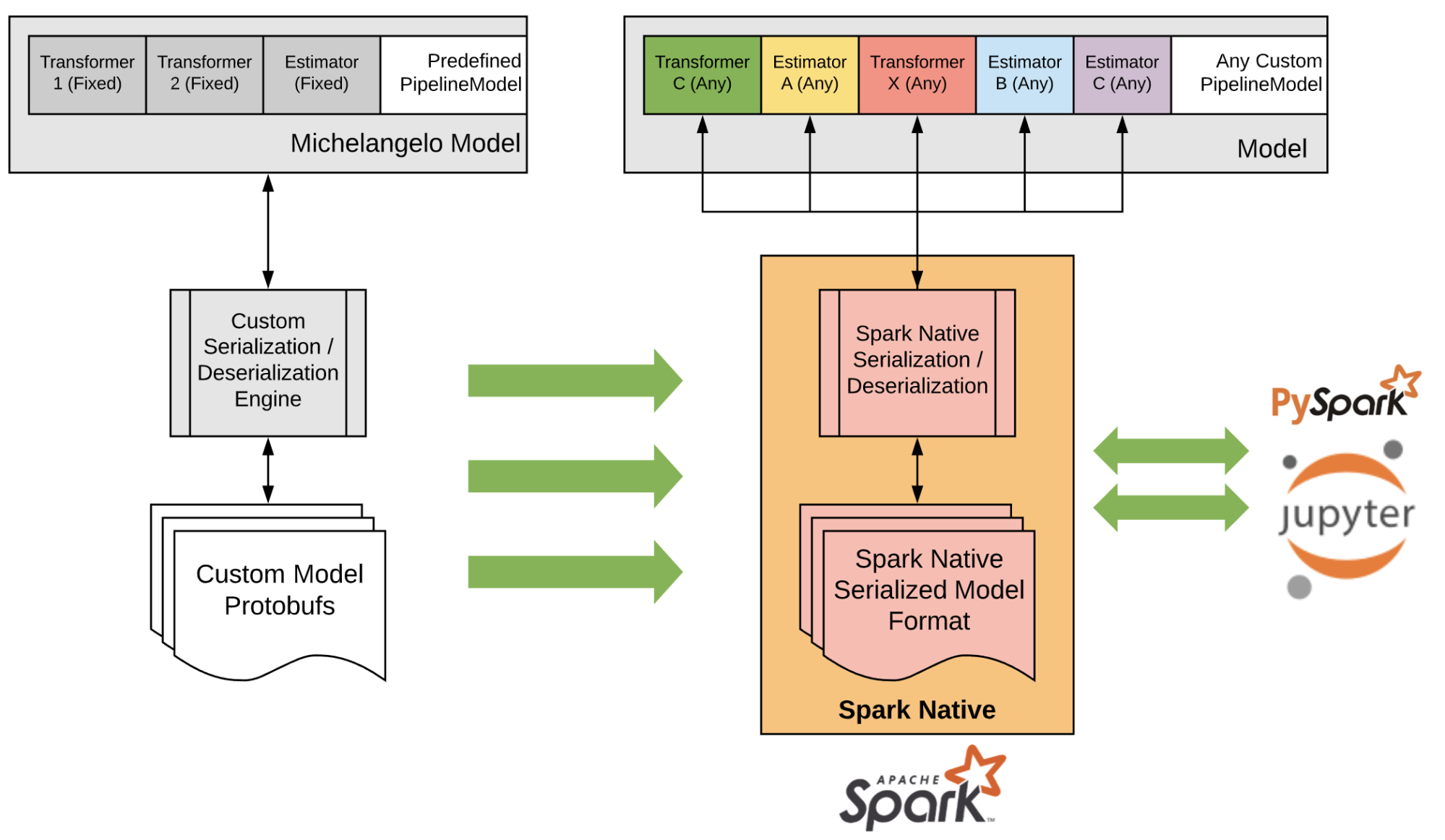
The original architecture enabled training and serving of common machine learning models such as generalized linear models (GLM) and gradient boosting decision tree (GBDT) models at scale, but the custom protobuf representation made adding support for new Spark transformers difficult and precluded serving of models trained outside of Michelangelo. The custom internal version of Spark also complicated each iteration of upgrading when new versions of Spark became available. To improve the velocity of support for new transformers and to allow customers to bring their own models into Michelangelo, we considered how to evolve the model representation and to more seamlessly add the online serving interfaces.
Evolution of Michelangelo architecture and model representation

Machine learning workflows at Uber are often complex and span various teams, libraries, data formats, and languages; to properly evolve model representation and online serving interfaces, we needed to account for all of these dimensions.
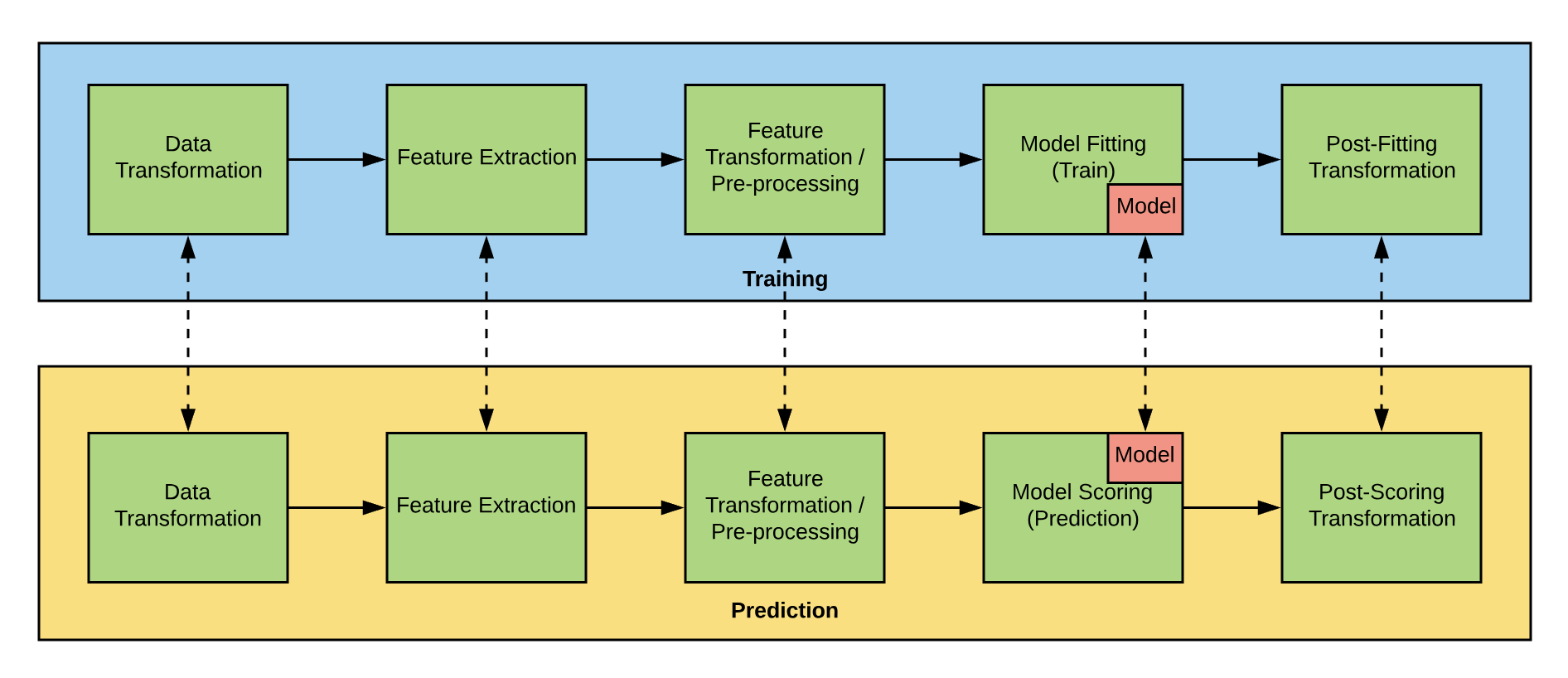
To deploy a machine learning model for serving, one needs to deploy the entire pipeline, including the workflows of transformations leading up to the model. There are often data transformations, feature extraction, pre-processing, and even post-prediction transformations that need to be packaged, as well. Raw predictions typically need to be interpreted or transformed back into a label, or in some cases to a different dimensional space such as log space that can be consumed by downstream services. It can also be valuable to augment the raw predictions with additional data such as their confidence intervals and calibrated probabilities via probabilistic calibration. We wanted a model representation that would reflect the pipeline steps inherent to a Spark MLlib model and that would allow seamless interchange with tools external to Michelangelo.
Choosing an updated model representation
In evaluating alternative model representations, we assessed various requirements, including:
-
- Power to express generalized transformation sequences (required)
- Extensibility to handle lightweight serving for the online use case (required)
- Support for interchanging models stored in Michelangelo with non-Michelangelo native Spark tools (required)
- Low risk of deviation in model interpretation between train and serve time (high want)
- High Spark update velocity and ease of writing new estimators/transformers (high want)
One approach we considered was using MLeap, a standalone library that provides pipeline and model serialization (into Bundle.ML) and deserialization support with a dedicated runtime to execute the pipeline. MLeap has the desired expressive power and support for lightweight online serving. However, it has its own proprietary persistence format, which limits interoperability with tool sets that serialize and deserialize plain Spark MLlib models.
MLeap also introduces some risk in deviation of serving time behavior from training time evaluation, since the model at serving time is technically loaded from a different format than it had in memory at training time. MLeap also introduces friction to Spark update velocity since separate MLeap save/load methods must be added for each transformer and estimator, in addition to those used by Spark MLlib natively. Databricks’ ML Model Export dbml-local offers a similar approach.
Another approach we considered was to export the trained model into a standard format like the Predictive Model Markup Language (PMML) or Portable Format for Analytics (PFA), both of which feature our desired expressive power and interchange with Spark, with PMML having direct support in Spark and aardpfark providing Spark export to PFA. However, these representations again present risks in serving time behavior deviation, which we expect to be higher than with MLeap since general standards can often have different interpretations in particular implementations. The standards also present higher friction in Spark update velocity, since the standard itself may need updating depending on the nature of the Spark changes.
We found the most straightforward approach is to use standard Spark ML pipeline serialization for model representation. The Spark ML pipeline exhibits our desired expressive power, allows interchange with Spark tool sets external to Michelangelo, demonstrates low risk of model interpretation deviation, and low friction to Spark update velocity. It also lends itself well to writing custom tranformers and estimators.
The major challenge we saw with using Spark pipeline serialization out of the box is its incompatibilities with online serving requirements (also discussed by Nick Pentreath in his Spark AI Summit 2018 talk). This approach of starting a local Spark session and using it to load a Spark MLlib trained model is equivalent to running a small cluster on a single host with significant memory overhead and latency, making it unfit for many online serving scenarios that demand p99 latency on the millisecond scale. While the existing set of Spark APIs for serving was not performant enough for Uber’s use case, we found that we could make a number of straightforward changes in this out-of-the-box experience that would satisfy our requirements.
To provide lightweight interfaces for online serving, we added anOnlineTransformer trait to transformers that can be served online, including single and small list methods which leverage low-level Spark predict methods. We also tuned the performance of model loading to hit our target overheads.
Pipelines using enhanced transformers and estimators
To implement a Transformer or Estimator that can be trained and served online by Michelangelo, we constructed an OnlineTransformer interface that extends the out of the box Spark Transformer interface and enforces two methods: 1) Transform(instance: Dataset[Any]) and 2) ScoreInstance(instance: Map[String, Any]).  Transform(instance: Dataset[Object]) serves as the entry point for distributed batch serving that comes with the out of the box Dataset-based execution model. scoreInstance(instance: Map[String, Object]): Map[String, Object] serves as the lighter-weight API for single-row prediction requests for a single map set of feature values present in low-latency, real-time serving scenarios. The motivation behind scoreInstance is to provide a lighter-weight API that bypasses the significant overhead incurred by Datasets that relies on Spark SQL Engine’s Catalyst Optimizer to do query planning and optimization on every request. As noted above, this is critical for real-time serving scenarios such as marketing and fraud detection, whereby the SLA for p99 latency is often on the order of milliseconds.
Transform(instance: Dataset[Object]) serves as the entry point for distributed batch serving that comes with the out of the box Dataset-based execution model. scoreInstance(instance: Map[String, Object]): Map[String, Object] serves as the lighter-weight API for single-row prediction requests for a single map set of feature values present in low-latency, real-time serving scenarios. The motivation behind scoreInstance is to provide a lighter-weight API that bypasses the significant overhead incurred by Datasets that relies on Spark SQL Engine’s Catalyst Optimizer to do query planning and optimization on every request. As noted above, this is critical for real-time serving scenarios such as marketing and fraud detection, whereby the SLA for p99 latency is often on the order of milliseconds.
When a Spark PipelineModel is loaded, any Transformer that has a comparable class that includes the OnlineTransformer trait is mapped to that class. This allows existing trained Spark models comprised of supported transformers to gain the capability of being served online without any additional work. Note that OnlineTransformer also implements Spark’s MLWritable and MLReadable interfaces, which provides Spark’s native support for serialization and deserialization for free.
Maintaining online and offline serving consistency
Moving towards a standard PipelineModel-driven architecture further enforces consistency between online and offline serving accuracy by eliminating any custom pre-scoring and post-scoring implementations outside of the PipelineModel. Within each Pipeline stage, the standard practice when implementing custom scoring methods is to first implement a common score function. In the offline Transform, it can be run as a set of Spark User-Defined Functions (UDF) on the input DataFrame and the same score function can also be applied to the online scoreInstance and scoreInstances methods. Online and offline scoring consistency will be further enforced via unit tests and end-to-end integration tests.
Performance tuning
Our initial measurements showed that native Spark pipeline load latency was very high relative to the load latency of our custom protobuf representation, as shown in the table below:

This performance difference in serialized model load time was unacceptable for online serving scenarios. Models are virtually sharded in each online prediction service instance, and are loaded either at the startup of each serving instance, during new model deployment, or upon receiving a prediction request against the specific model. Excessive load time impacts server resource agility and health monitoring in our multi-tenant model serving setup. We analyzed the sources of the load latencies and made a number of tuning changes.
A source of overhead that affected load time across all transformers was that Spark natively used sc.textFile to read the transformer metadata; forming an RDD of strings for a small one-line file was very slow. Replacing this code with Java I/O for the local file case was significantly faster:
[loadMetadata in src/main/scala/org/apache/spark/ml/util/ReadWrite.scala]
Another source of overhead that affected many transformers of interest in our use cases (e.g., LogisticRegression, StringIndexer, and LinearRegression) was using Spark distributed read/select commands for the small amount of data associated with the Transformers. For these cases, we replaced sparkSession.read.parquet with ParquetUtil.read; doing direct Parquet read/getRecord greatly improved the load time of these transformers.
Tree ensemble transformers had some particular related tuning opportunities. Loading tree ensemble models requires reading the model metadata files serialized to disk which invoked groupByKey, sortByKey, and the Spark distributed read/select/sort/collect operations of small files was very slow. We replaced these with direct Parquet read/getRecord which was much faster. On the tree ensemble model save side, we coalesced tree ensemble node and metadata weights DataFrames to avoid writing a large number of small, slow-to-read files.
As a result of these tuning efforts, we were able to reduce native Spark model load time for our benchmark examples from 8x-44x to only 2x-3x slower than loading from our custom protobuf, which amounts to 4x-15x of speed-up over Spark native models. This level of overhead was acceptable in light of the benefits of using a standard representation.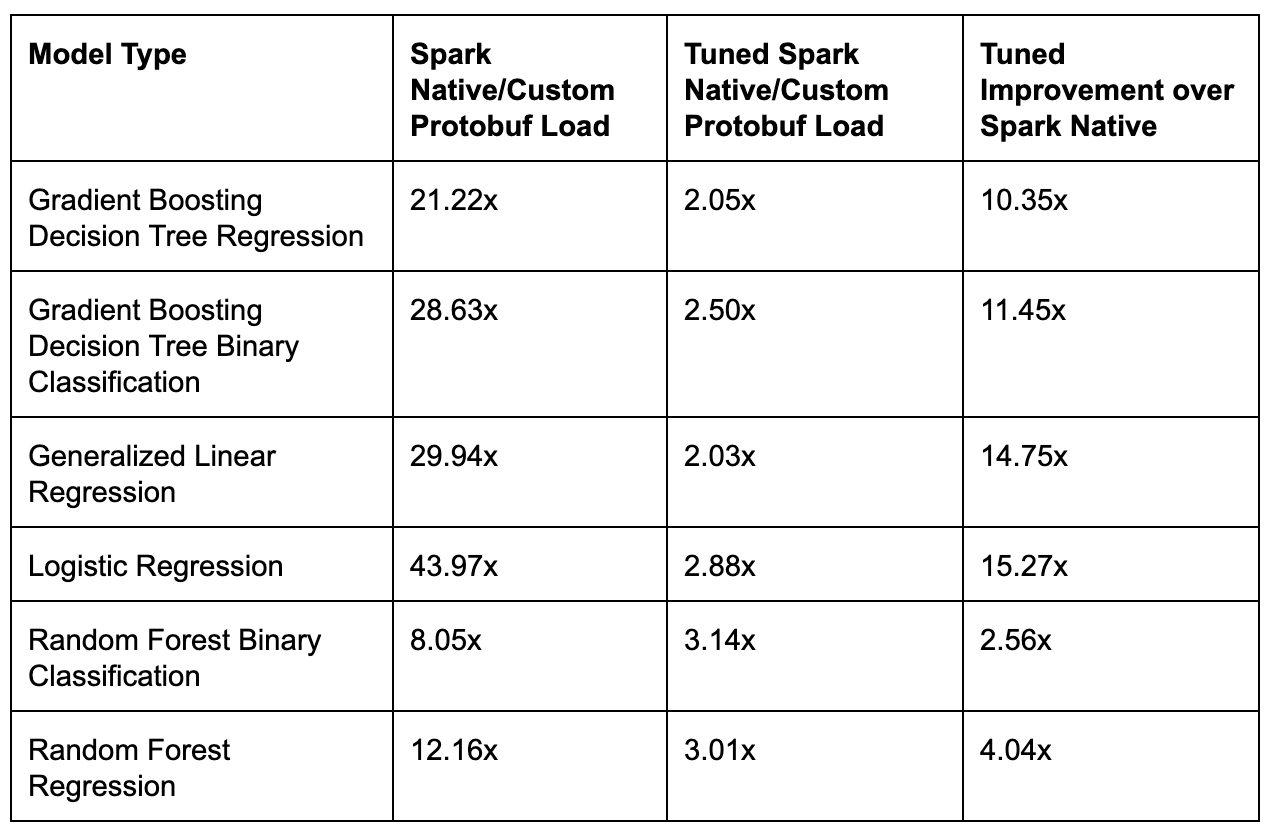
It is important to note that Michelangelo online serving creates a local SparkContext to handle the load of any unoptimized transformers, so that the SparkContext is not needed for online serving. We found that leaving a SparkContext running when no model loads were active could negatively impact performance and serving latency, for instance, by the actions of the SparkContext cleaner. To avoid this impact, we stop the SparkContext when there are no loads running.
Flexible construction of servable pipelines
Using pipeline models as Michelangelo’s model representation serves as a contract for users to flexibly compose and extend units of servable components that are guaranteed to be consistent when served online and offline. However, this does not fully encapsulate the difference in operational requirements with regard to how the pipeline model is being utilized throughout the various stages of the machine learning workflow. There are operational steps or concepts that are inherently relevant to particular stages of the machine learning workflow but are completely irrelevant to others. For instance, when users are evaluating and iterating on the model, there are often operations such as hyperparameter optimization, cross-validation, and the generation of ad-hoc metadata required for model interpretation and evaluation. These steps allow users to help generate, interact with, and evaluate the pipeline model, but once it is ready to be productionized, these steps should not be incorporated into model serving.
The difference in requirements at various stages of the machine learning workflow motivated in parallel to develop a workflow and operator framework on top of common orchestration engines. Aside from the flexibility of composing custom servable pipeline models, this further allows users to compose and orchestrate the execution of custom operations in the form of a directed graph or workflow to materialize the final servable pipeline model, as illustrated by Figure 6, below:
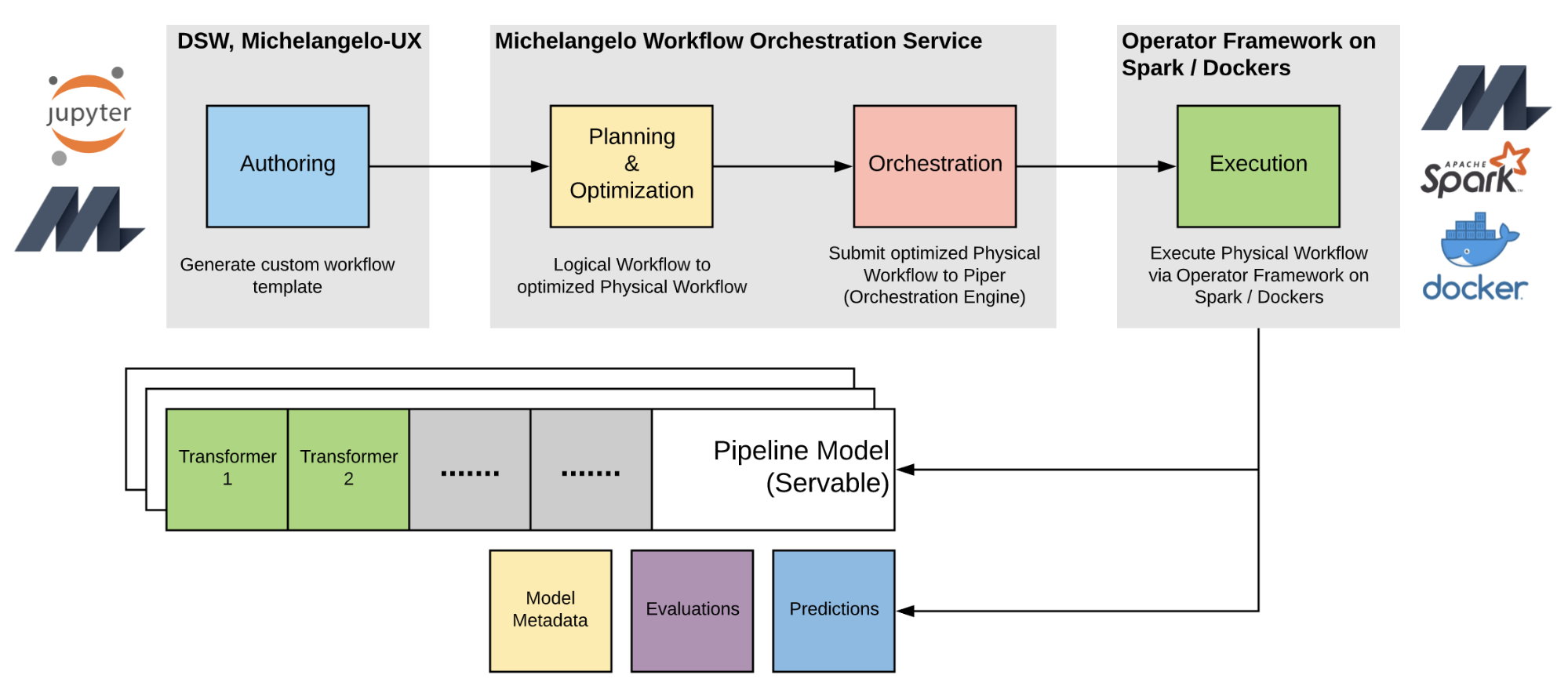
Moving forward
At this point, Spark native model representation has been running in production in Michelangelo for more than a year as a robust and extensible approach to serving ML models at scale across our company.
Thanks to this evolution and other updates to the Michelangelo platform, Uber’s ML stack can support new use cases such as flexibly experiment and train models in Uber’s Data Science Workbench, a Jupyter notebook environment that can be served in Michelangelo, as well as end-to-end deep learning using TFTransformers. In an effort to highlight our experiences and help others scale their own ML modeling solutions, we discussed these updates at the Spark AI Summit in April 2019 and have filed an SPIP and JIRA to open source our changes to Spark MLlib.
We look forward to hearing about your experiences with similar problems and we greatly appreciate the value of the Spark code base and its community.
Header image logo attributions: Apache Spark is a registered trademark of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of this mark. Docker and the Docker logo are trademarks or registered trademarks of Docker, Inc. in the United States and/or other countries. Docker, Inc. and other parties may also have trademark rights in other terms used herein. No endorsement by Docker is implied by the use of this mark. TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
References
-
- Spark AI Summit 2019, San Francisco Talk: Using Spark MLlib Models in a Production and Serving Platform Experiences and Extensions
- D. Sculley, G. Holt, D. Golovin, E. Davydov, T Phillips, D. Ebner , V. Chaudhary , M. Young , J. Crespo, D. Dennison, Hidden Technical Debt in Machine Learning Systems, Proceedings of the 28th International Conference on Neural Information Processing Systems, p.2503-2511

Anne Holler
Anne Holler is a former staff TLM for machine learning framework on Uber's Machine Learning Platform team. She was based in Sunnyvale, CA. She worked on ML model representation and management, along with training and offline serving reliability, scalability, and tuning.

Michael Mui
Michael Mui is a Staff Software Engineer on Uber AI's Machine Learning Platform team. He works on the distributed training infrastructure, hyperparameter optimization, model representation, and evaluation. He also co-leads Uber’s internal ML Education initiatives.
Posted by Anne Holler, Michael Mui
Related articles





Most popular

Load Balancing: Handling Heterogeneous Hardware

Balancing HDFS DataNodes in the Uber DataLake

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale

Audio Recording
Products
Company
