Vertical CPU Scaling: Reduce Cost of Capacity and Increase Reliability
July 14, 2022 / Global
This blog post describes the implementation of an automated vertical CPU scaling system in which every storage workload running at Uber is allocated the ideal amount of cores. The framework is used today to right-size more than 500,000 Docker containers, and since its inception it has applied a net reduction of allocations of more than 120,000 cores, leading to annual multi-million dollar savings in infrastructure spending.
At Uber, we run all storage workloads such as Docstore, Schemaless, M3, MySQL®, Cassandra®, Elasticsearch®, etcd®, Clickhouse®, and Grail in a containerized environment. In total, we run more than 1,000,000 storage containers on close to 75,000 hosts with more than 2.5 million CPU cores. To reduce the risk of noisy neighbors, every workload is allocated an isolated set of CPU cores [ref], and hosts are not overprovisioned. We run a multi-region replicated setup where traffic can be drained from an entire region as part of incident response.
One major challenge is to assign the right number of CPU cores to every container. Until recently the appropriate core count to set per container was manually determined by engineers responsible for each storage technology. The advantage of this approach is that domain experts have the responsibility of monitoring each of their technologies and making the right decisions. The disadvantage is that humans need to do this work, and it often becomes a reactive scaling strategy where settings are changed when they cause cost or reliability issues, instead of a proactive approach where containers are vertically scaled up and down based on actual usage to ensure consistent performance at the lowest possible cost.
Choosing the Right Metric to use for Vertical CPU Scaling
The first step in right-sizing containers is to define what we mean by “the right size.” In a nutshell, we want to assign as few resources to every container as possible without compromising the performance of the workload running in the container.
Different strategies can be used to determine the right core count to assign to each storage container. A very direct approach would be to establish a feedback loop between core business metrics (e.g., P99 latencies) and the allocation for the container. If the feedback loop is tight and fast enough then the allocation can be brought up or down to ensure the right allocation at all times. This approach, however, isn’t well suited for managing storage workloads, for the following reasons:
- Storage workloads can take hours to move between hosts. Because data needs to be brought along with the compute resources, a model with frequent movements of workloads between hosts must be avoided.
- Load can easily change by 2-5x throughout the week. With load changing that much, it becomes very difficult to create a model that determines the optimal core count to assign, since the containers most of the time will be overprovisioned.
- Different use cases will have different key metrics to monitor. Building a model that works well for batch workloads will be very different from low-latency use cases, like serving restaurant menus for the Uber Eats app.
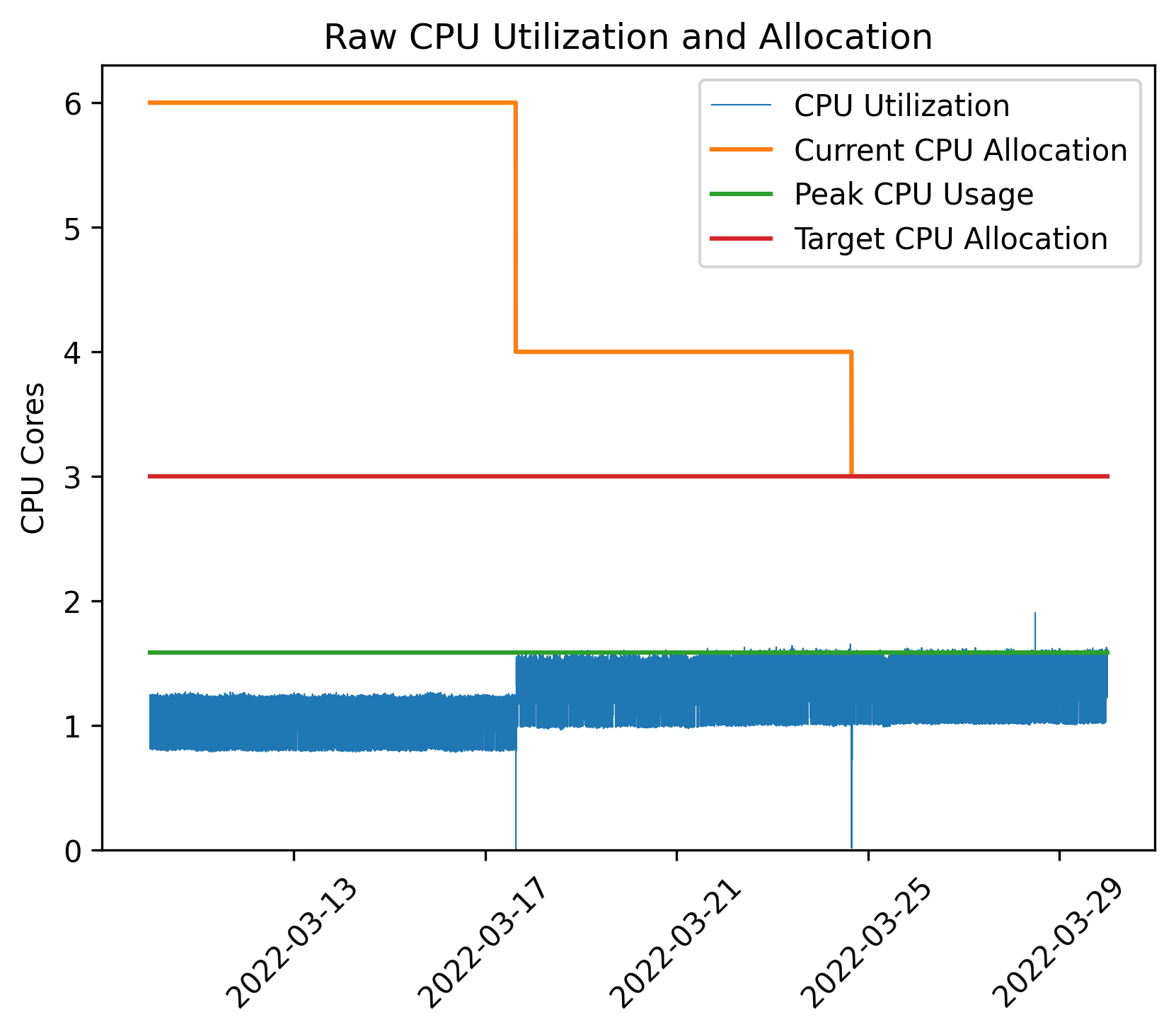
Instead of monitoring key business metrics, we instead built a model based on the CPU utilization measured externally for every storage container. The model ensures a specific ratio between the historically measured peak CPU utilization and the core count assigned to the container. The ratio between the peak usage and the allocation will be referred to as the CPU usage ratio. Figure 2 shows how the model based on the past 14 days of CPU usage determines the peak usage (green), and from this calculates the target allocation (red). The figure additionally shows how the current CPU allocation (yellow) is gradually converged to the green line.
The benefits of this approach are the following:
- CPU utilization metrics are always available. This ensures we can create a “one-model-fits-all,” avoiding the time-consuming work creating a model per storage technology or use case.
- CPU utilization metrics are fairly constant week over week, so in most cases, the last two weeks will predict the peak usage in the coming weeks quite accurately.
- CPU utilization tends to increase in a predictable manner during a regional failover. By targeting, e.g., 40% CPU utilization, it is fairly certain that CPU utilization will not go above 80% during a regional failover, briefly doubling the load in a worst-case scenario.
More details on how the peak CPU utilization is calculated will be given in the next section.

Figure 3 shows a histogram of the peak CPU usage ratio before and after vertical CPU scaling was enabled for the Schemaless technology [ref]. By default, the scaler is set to target a 40% peak CPU usage ratio. The 40% has been selected to ensure room for a regional failover (potentially doubling load). The 40% has been selected because we do not want to go above roughly 80% CPU utilization. At above 80% CPU utilization congestion issues occur due to Hyper-Threading being enabled.
Comparing the before and after in Figure 3, we can observe that the ratio of overprovisioned allocations (the low category) has gone down significantly. The reason why it has not disappeared fully is mainly due to Schemaless running in a leader/follower setup based on Raft with a single leader for every cluster. Only the leader can serve consistent reads, and for some use cases it has a significantly higher request rate than the rest. At any given time any of the other containers can become the leader, so it is important that all containers from the same cluster are scaled equally.
From Figure 3 it is also clear that the ratio of containers in the high category has gone up. This is actually intended, because we have realized that some storage clusters do not increase much in load during a regional failover. For these clusters, we can therefore target a significantly higher peak usage ratio.
The net effect of right-sizing all containers associated with Schemaless has been an overall reduction of about 100,000 cores or roughly 20%. The typical host used at Uber has 32 or 48 cores, and the allocation ratio is around 83% with CPU cores being the bottleneck in most cases. These 100,000 cores thus translate into a savings of 3,000 hosts (with no change in end-user latencies).
The overall reduction of ~100,000 cores is a combination of containers being decreased by ~140,000 cores, and others being increased by ~40,000 cores. This means that a large set of containers were actually provided with too few resources. The vertical CPU scaler has thus not only generated significant savings but also ensured consistent performance and reliability across the board. The impact of this has been evident during regional failovers due to containers now generally being allocated the required resources and therefore not generating latency degradations to the same degree as they used to.
Calculating Allocation Targets
The previous section argued why CPU container metrics can be used to vertically right-size storage workloads. In this section, we go into more detail on exactly how the calculation of the target is done. The term pod, as borrowed from Kubernetes®, will be used in the following to describe a collection of containers making up a storage workload running on a single host.
The model for calculating the CPU allocation to set per pod is, as already described, based on calculating the peak CPU utilization and then converting that into an allocation that ensures a given peak CPU utilization ratio. One important additional consideration is that all pods in the same storage cluster must be allocated the same amount of cores. The reason for this is that responsibilities within a storage cluster can change over time, and all pods must therefore be allocated sufficient resources so that they can become the busiest pod in the cluster.

Figure 4 shows how the peak CPU utilization is calculated from the past 14 days of CPU utilization data. CPU utilization data is collected using cexporter [ref] and published as a time series into our monitoring stack M3 [ref]. The algorithm goes through the following steps:
- Start from the raw CPU utilization signal for all pods in the same storage cluster. Using a 2-week window matches with the time-scale that load on Uber’s systems change since we are dominated by a weekly pattern with peak load happening Friday and Saturday night. Using a 2-week lookback ensures that we always include 2 weekends in the dataset.
- Downsample the raw time series to 8-hour resolution. In this step the raw time series per pod is downsampled to 8-hour resolution calculating the P99 CPU utilization for each time window. The P99 for an 8-hour time interval ensures that the CPU utilization is at most above this value for 5 minutes per 8-hour window. We have tried different downsampling windows from 4 to 24 hours. Using 8 hours seems to provide a good signal-to-noise ratio where we avoid over-indexing towards outliers, but also do not miss important peaks.
- Collapse the per-pod signal into a cluster signal. In this step the value from the most busy pod is chosen per timestamp. This collapses the per-pod signals into a cluster-level signal. For storage technologies like Cassandra with a potentially high number of pods per cluster, the P95 value is selected per timestamp instead.
- Define the third highest peak as the peak CPU utilization for the cluster. In this final step, the peak CPU utilization is extracted from the 42 data points (14 days * 3 data points/day) for the cluster. The peak CPU utilization is defined as the third-highest data point. By selecting the third-highest data point we avoid over-indexing toward an outlier.
Having determined the peak CPU utilization for every cluster, we calculate the quota as:
![]()
Quotas are rounded up to the nearest integer to avoid fractional core allocations. We want to avoid fractional core allocations due to the use of cpusets [ref] for workload separation.
Summary
Since enabling vertical CPU scaling in early 2021 Uber has saved millions of dollars in hardware spent from reducing core allocations by more than 120,000 cores. We have at the same time improved the overall reliability of our platform by ensuring that all storage pods are consistently sized.
The engineering efforts spent on right-sizing storage clusters have also been reduced dramatically because engineers now only need to express the desired utilization rate, instead of having to manually calculate and execute allocation changes. Work is ongoing on determining the optimal utilization rate to set per storage cluster, depending on failover behavior and criticality.
This blog post focused on the methodology behind determining the allocation to set per storage pod. In the next blog post, we will go into detail on how allocation changes are prioritized and safely applied.
Elasticsearch is a trademark of Elasticsearch BV, registered in the U.S. and in other countries.
ClickHouse is a registered trademark of ClickHouse, Inc. https://clickhouse.com

Lasse Vilhelmsen
Lasse Vilhelmsen is a Staff Software Engineer at Uber where he is the Tech Lead of the Stateful Capacity and Efficiency team.
Posted by Lasse Vilhelmsen
Related articles




How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global

Most popular

Balancing HDFS DataNodes in the Uber DataLake

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale
The Easter Shop and Pay with Uber Eats Gift Card Sweepstakes Official Rules

UberX Priority FAQ
Products
Company
