Ludwig v0.2 Adds New Features and Other Improvements to its Deep Learning Toolbox
Uber released Ludwig, our open source, code-free deep learning toolbox, in February 2019, introducing the world to one of the easiest ways to get started building machine learning models. The simplicity and the declarative nature of Ludwig’s model definition files allows machine learning beginners to be productive very quickly, while its flexibility and extensibility enables even machine learning experts to use it for new tasks with custom models.
Over the course of the last five months, a great community gathered around Ludwig. Members of the broader open source community contributed many of new features to enhance Ludwig’s capabilities.
Today, we release these new features in Ludwig version 0.2, including many new tools, several improvements under the hood, and bug fixes. The major ones are the integration with Comet.ml, the addition of BERT among text encoders, the implementation of audio/ speech, H3 (geospatial) and date (temporal) features, substantial improvements on the visualization API, and the inclusion of a serving functionality.
We are very thankful for these contributions and encourage others to give back to Ludwig for future releases.
Comet.ml
Comet.ml is a tool that lets users track their machine learning code, experiments, and results. The Comet.ml team, in particular Doug Blank, contributed a new Comet.ml integration that allows models trained in Ludwig to be automatically monitored in their platform so that users will never miss an experiment again. With this integration, users can compare experiments in an easy and elegant interface, capture model configuration changes, easily track results and details across multiple experiments, view live performance charts while the model is training, and analyze hyperparameters to build better models.
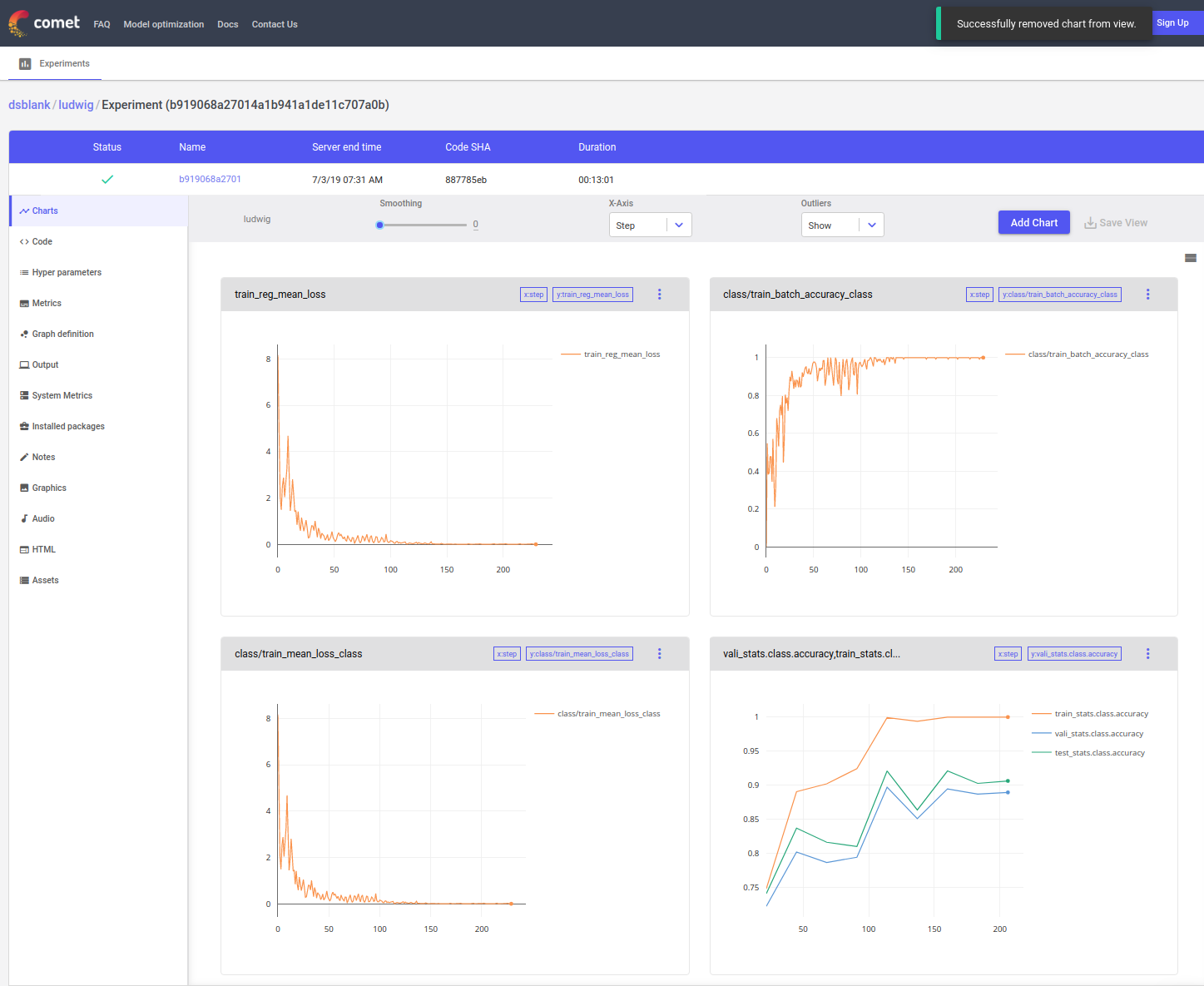
In order to use the Comet.ml integration, users just have to add the –comet parameter and configure their comet.config files. With this integration, experiments will be tracked automatically.
Alongside this new Comet.ml integration, we defined a number of hooks inside Ludwig for other integrations to use, which will make contributions even easier moving forward.
BERT encoder
BERT is a language encoding model based on the Transformer architecture for encoding textual data that is trained on a large corpus of textual data in a self-supervised way. It can be used as a form of pre-training or transfer learning to train models to perform text-based tasks like classification or generation. An extensive body of research shows that the positive transfer from pre-training on a huge corpus can translate to better performance and faster training, in particular when the supervised data for the specific task is small.
We added a BERT encoder to Ludwig’s list of available text encoders to allow for use cases where the supervised data is small but the performance requirements are high. This means that from today anyone can obtain a state-of-the-art text classifier without writing a single line of code.
Using it is as simple as downloading a preferred pre-trained model and specifying the following information in the YAML model definition file:

Paths for config, weights, and tokenizer_vocab are provided in the downloaded models.
Audio/speech features
We are excited to announce that audio features are now available in Ludwig. The way they work in terms of preprocessing is similar to image features, as in both cases file paths need to be specified so that Ludwig can load data from them, while encoding is similar to sequential and time series features.
The audio features double down as speech, too. By default they are mapped into a one-dimensional raw signal, but short-time Fourier transform and group delay feature extraction can also be applied by changing the preprocessing parameters and obtain the classic features that are used in many speech models.
Here’s an example of how to add an audio/speech feature to the YAML model definition:

The addition of audio features opens not only the gate to many more applications, such as speaker identification and automatic speech recognition, among others, but also provides an additional signal for multimodal tasks. We can’t wait to see how Ludwig users are going to use them!
H3 features
Created and open sourced by Uber in 2018, H3 is a spatial indexing system that relies on hierarchical hexagons to identify areas on earth at different levels of granularity. It is used for encoding a location into 64-bit integers, and leveraged at Uber to analyze geographic information to set dynamic prices and make other decisions on a city-wide level. With H3 integration, users can feed hexagonal data to Ludwig models without any additional manipulation.
We are also providing three new encoders that encode an H3 integer into a latent representation by encoding its components (the mode, the base hexagon, and the lower resolution cells). The first encoder, embed, embeds each component and aggregates them by summing the embeddings. The second, weighted_sum, does the same, but also learns weights to combine the embeddings. The third, rnn, embeds the components and then uses a recurrent neural network to combine them, following the sequential dependencies in the hierarchy from the more fine-grained hexagon to the most fine-grained one.
Here’s how to add an H3 feature to the YAML model definition file:

Date features
In our 0.2 release, we added a simple way to support dates and timestamps in Ludwig. This feature lets users input events to Ludwig that happened on a specific day or at a specific time to obtain predictions about them. Date information is parsed through either a user-specified pattern or Python’s automatic date parsing function, and subdivided in components (year, month, day, day of the week, day of the year, hour, minute, and second). We also provide two encoders for dates: the first, embed, embeds each component independently and then concatenates the obtained representation, while the second, wave, encodes each component with a periodic function and concatenates the results.
Here’s an example of how to add a date feature to the YAML model definition file:

Server
There are several ways to deploy Ludwig models, due in part to the fact that Ludwig trains TensorFlow models, but with this release, we added a feature to allow users to serve trained models directly into the core Ludwig library. We adopted the FastAPI library to spawn a REST server that can be queried to obtain predictions.
To serve trained models directly into Ludwig, users just need to run:

(In this case the input contains a text feature and an image feature).
Visualization API
Ludwig’s visualization options are pretty extensive, but have gone underutilized so far. The main reason is that the plots are, by default, displayed in a new window, and this setting is not ideal for many users, in particular those working on remote machines or within notebooks.
We solved this issue by first providing an option to specify an output path where the plots will be saved rather than showing them in a new window. This functionality can be used this way:

While this snippet shows how to save the ‘learning_curves’ visualization, this new functionality works for all other visualizations.
The second way we addressed the visualization issue is by providing functions in the API that can be called programmatically from within a notebook. Every function previously available through the command line now is also available through the API. Here is an example:

In order to do add this functionality, we refactored all of the visualization code, making it much cleaner, better encapsulated, and much more testable.
spaCy preprocessing
Beyond regular whitespace and punctuation tokenizers, the first release of Ludwig only supported English language text tokenization. In this new release we added Italian, Spanish, German, French, Portuguese, Dutch, Greek, and multi-language, thanks to the models in the newest version of the great spaCy NLP library.
Smaller improvements based on user feedback
As we added new features to Ludwig over the past months, users around the world requested clarity on how to achieve their tasks. To help new users get started with Ludwig, we increased the number of examples in the Github substantially, from just a handful to more than 20.
We also considerably improved image and numeric features by adding many more parameters for both preprocessing and prediction.
There have also been many improvements going on under the hood, including a faster import speed (by ~50 percent), more optional parameters in the API, and improved test coverage and speed.
We added a new test command to avoid the confusion around the predict command: now they both predict from unseen data, but the test command also calculates measures of the quality of the prediction, as long as ground truth outputs are available in the data, while predict only computes the predictions, and does not require these outputs.
We reorganized the preprocessing code to make it more testable and extensible, allowing support for more input data types in the future like TSV, JSON, and Apache Parquet.
We resolved more than 50 bugs, which made the codebase much more stable and dependable. This was possible also thanks to our friends at deepsource.io, as their tool allowed us to identify areas for improvement in the codebase.
Moving forward
Over the course of the last five months, Ludwig has grown a lot, but there is still a lot to do to make it fully featured.
One specific weakness of the current version of the library is data preprocessing: because Ludwig needs to extract metadata, the framework requires users to provide the full data in batch and load it in memory (with the exception of image features). This is a limitation as it caps the size of the data Ludwig models can be trained on to the size of a hard drive, but models themselves do not have this limitation. For this reason, over the next few months, we are planning to overhaul the preprocessing pipeline to support Petastorm, Uber’s open source data access library for deep learning, to allow Ludwig to train on petabytes of data stored in HDFS or Amazon S3.
We are also exploring adding a hyperparameter optimization functionality to Ludwig in order to obtain more optimized models that perform better on tasks with less effort. We already have a working Bayesian approach thanks to contributor Michael Pearce, but it needs a bit more polishing to be ready for prime time, so we will likely include it in v0.3.
We plan to add more state-of-the-art encoders for all features, in particular adding the ability to load pretrained models like VGG and ResNet for images, and XLNet and other Transformers for text. We believe that contributing these encoders would be a great way for the community to help, so we encourage developers to reach out to us and we can provide guidance on how to do it–it’s really easy and an opportunity to learn all about Ludwig!
More feature types are also on the radar, in particular multivariate time series, vectors, and point clouds–all three will likely be added in the next release. We also plan on spinning up missing decoders.
Finally, we are pleased to announce that we are working with Professor Christopher Ré’s HazyResearch group at Stanford University to integrate Ludwig with Snorkel, their system for programmatically building and managing training datasets to rapidly and flexibly fuel machine learning models. The combination of their weak supervision approach with multitask learning and Ludwig’s quick iteration and declarative model definition is really promising because of their complementarity. We hope to see the fruits of this collaboration soon!
Interested in learning more about Ludwig? Check out our official site, read our announcement, and watch our new video tutorial!
Acknowledgements
We want to thank all our amazing open source contributors!
Doug Blank and the Comet.ml team contributed the Comet integration. Audio/speech features were initially contributed by Patrick von Platen. John Wahba contributed Ludwig’s new server functionality. Ivaylo Stefanov refactored the visualization code and contributed the visualization API. Thanks to the spaCy team for enabling more language tokenization in Ludwig.
Piero Molino
Piero is a Staff Research Scientist in the Hazy research group at Stanford University. He is a former founding member of Uber AI where he created Ludwig, worked on applied projects (COTA, Graph Learning for Uber Eats, Uber’s Dialogue System) and published research on NLP, Dialogue, Visualization, Graph Learning, Reinforcement Learning and Computer Vision.
Sai Sumanth Miryala
Sai Sumanth Miryala is a data scientist on Uber's Conversational AI team.
Yaroslav Dudin
Yaroslav Dudin is a senior software engineer on Uber's New Mobility Optimization team.